一篇写给从未编程过的人的入门教程
这篇讲的是编程入门的“心理障碍”有多不必要。作者开篇就破除了“外行/内行”的标签,认为编程本质是每个人都熟悉的逻辑表达,他以自己半天学会PlantUML为例,强调学习曲线比想象中平缓。 为了让抽象概念落地,作者巧妙地用“17点回家如何在18点30分前让家人吃上饭”这个日常场景,类比了编程中的算法(解决步骤)、数据结构(书架/柜子的存储逻辑)和程序实体(做饭)。这种类比让“编程=算法+数据结构”的公式瞬间变得亲切可感。 文章的核心观点是,区分编程小白与专家的,并非代码本身,而是思考问题的周全性。作者通过对比两段“做饭”的伪代码——一个临时发现没油才去买,另一个提前检查缺漏并携带清单——生动说明了后者如何通过“检查”步骤让流程更可靠、高效。这引出了编程中“抽象”思维的关键价值:将重复步骤(洗菜、切菜、炒菜)封装成方法,使得程序能通过扩展“菜单”而非重复代码来处理复杂任务。 最终,作者将编程的复杂性落回到现实:入门简单,但写出考虑周全、高效且能应对需求变化的“好程序”却极具挑战。结尾那句关于“程序员最苦恼的是需求变化”的调侃,也让这篇技术入门文多了一份共鸣和幽默。
裁剪和空间管理
这篇讲的是游戏引擎里渲染优化的一个关键模块——Culling与空间管理。作者从一个基本问题出发:当场景里可渲染对象很多,但相机实际能看到的只有一小部分时,如何避免让GPU处理所有对象,从而节省CPU到GPU的带宽?最朴素的做法是对每个对象做视锥体检测,复杂度是O(n)。但当对象数量n极大时,我们需要更好的方法。 核心思路是利用空间结构来加速。把对象按空间位置组织成树状结构,这样在检测时可以快速剔除一整个分组,将复杂度降到O(log n)。文章梳理了这条技术路径的演进:从简单的等距网格,到处理不均匀分布的四叉树/八叉树,再到为解决对象跨边界问题而提出的BSP。作者特别推崇K-D Tree和BVH方案,它们通过在每次二分时智能选择分割线位置(比如让两侧对象数量均衡),能形成完全二叉树,既紧凑又高效。 作者强调,Culling本质上是一个可选的“加速缓存”,而非引擎核心容器,因此其数据结构应保持独立和简洁。例如,他建议用一块连续内存存储K-D Tree的切割信息,实现简单且支持持久化。最后,文章还探讨了实现细节,比如如何高效地对对象进行二分,以及是否需要动态调整树结构,给出了倾向于静态构建、按需重建的设计观点。
Raft 为什么不能直接 commit 前任的日志?
这篇讲的是 Raft 共识协议中一个容易被忽略但至关重要的设计细节:为什么 Leader 不能直接提交前任任期的日志,而必须通过提交本任期的新日志来“隐式”提交。 作者从 Raft 的几项基本原则出发,进行逻辑推演。他指出,一旦日志被 commit,对状态机的影响就不可撤销;而未 commit 的日志则可能被同一 index 不同 term 的新日志替换。核心目标是让所有节点最终提交相同的日志。 问题在多个 Leader 交替时浮现。例如,前两任 Leader 针对同一 index 产生的日志均未形成多数派,第三任 Leader 可能继承其中任一个,这就会导致另一条日志被替换。文章强调,只有 commit 自己任期的日志才能确保它“永不丢失”。这是因为现任 Leader 永远不会撤销自己任期的日志,且新当选的 Leader 一定包含上一个任期多数派中的最新日志。因此,确认本任期日志已复制到多数节点,就能保证它被所有后续 Leader 继承。 这个推理解释了 Raft 论文中反例背后的深层原理,揭示了“隐式提交”机制是如何在日志可能被覆盖的复杂场景下,依然坚定地维护日志一致性的。
位运算技巧整理
这篇讲的是位运算(&、|、^、~)的基础规则与实用技巧的整理。作者从最基本的四种操作讲起,但真正的亮点在于后续展示的几招“组合技”:比如,利用“一个数和自己异或结果为0”的特性,可以高效找出数组中唯一一个出现奇数次数的数字;再如,当除数是2的幂次方时,用 `num & (len-1)` 来取余数,比直接用取模运算符 `%` 的效率更高。 文章还系统梳理了十进制与二进制之间的手工转换方法,补全了从原理到实践的理解链条。这些技巧并非炫技,在底层优化、嵌入式开发或算法面试中都有实实在在的应用。文章将零散的位运算知识串联成了可直接使用的“工具包”,对于想深入理解计算机底层运算的开发者来说,是一份清晰的备忘录。
淘宝用户增长的5+1个策略
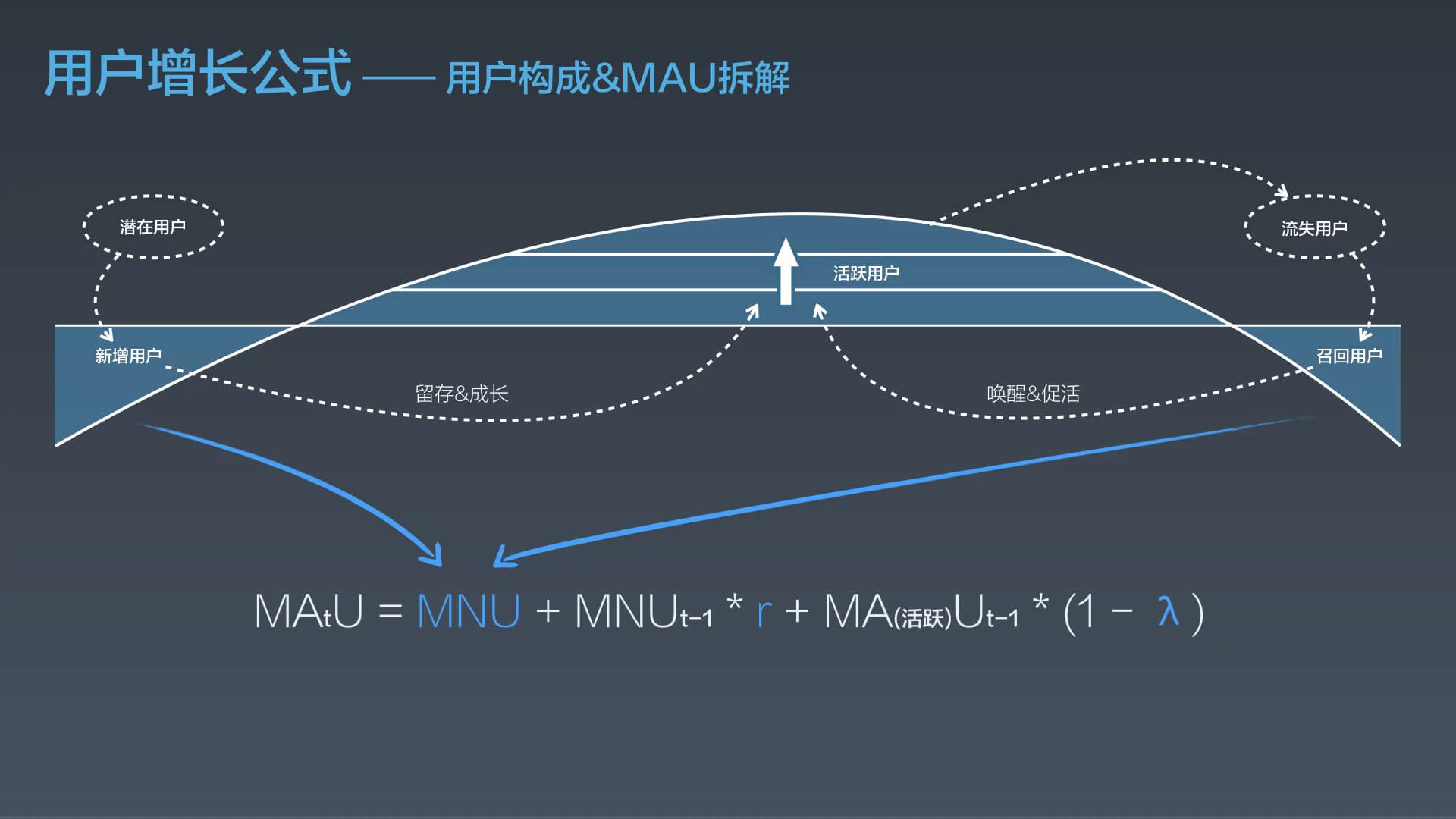
这篇讲的是淘宝如何拆解和制定用户增长策略。作者没有陷入实现细节,而是从平台视角出发,首先构建了一个清晰的用户增长公式:MAU由上月留存、未流失用户以及本月新增(MNU)构成。增长抓手的核心,就聚焦在MNU的引入上。 围绕MNU引入,文章分享了淘宝的流量引入体系——一个“三纵两横”的架构。具体策略上,智能投放的核心是“对人”和“对素材”的深刻理解。通过建立离在线人群服务为渠道提供精准流量筛选,再结合海量素材库与个性化推荐算法,能将广告曝光点击率从行业普遍的2%以下提升至10%以上。另一个重点策略“拉承一体”,则巧妙解决了用户引入后在登录环节大量流失的痛点。通过封装链接SDK统一入口,并借助“用户信息总线服务”跨域传递用户行为数据,让运营得以在用户激活的瞬间进行个性化承接,填补了引流与用户成长之间的空白。 整体而言,文章的价值不在于具体的技术实现,而在于其展现的系统化思考框架:如何用公式量化增长目标,如何构建体系化的流量引入路径,以及如何通过技术手段将运营抓手前置和深化。这对所有从事用户增长工作的人都有很强的借鉴意义。
视频的容器与格式
这篇梳理视频格式领域的基础文章,从“编码”与“容器”两个核心维度展开。作者将视频编码(如H.264、H.265)比作内容的“压缩标准”,决定了画面质量与文件大小;而容器(如MP4、MKV)则是装载这些内容的“打包盒子”。文章依次介绍了从经典的MPEG-1/2到目前主流的H.264、代表趋势的H.265等编码技术的演进与特点,并对比了MOV、AVI、MKV等主流容器的优劣——例如MKV因其超强的包容性而被称为“万能容器”,能封装几乎任何格式的音视频流。 对于需要处理或选择视频格式的开发者、创作者而言,文章提供了清晰的脉络:H.264+MP4是当下兼容性最广的选择,而H.265则代表了在同等画质下更高效压缩的未来方向。无论是理解DVDRip中的MPEG-2,还是分辨RMVB文件背后的RealVideo编码,这篇文章都给出了直观的解答。
增长二三事
这篇讲的是作者在听了Hola Group增长负责人Daisy的分享后,对“增长”这件事梳理出的几点核心认知。文章没有停留在理论,而是直面增长中的现实矛盾与动态规律。 作者开篇就挑战了一个常见误解:获客成本(CAC)并非越低越好,而是随着拉新规模的扩大必然上升。为此,他用了一个很直观的45度线上升曲线来比喻。接着,他将用户划分为铁杆粉丝、中需求群体等不同圈层,指出每个圈层的用户终身价值(LTV)、CAC和数量(N)都不同,这构成了增长公式 MAX[(LTV - CAC) * N] 的动态变量。文中以抖音从垂类泛化到全民产品的过程为例,说明了清晰计算各圈层模型、用商业化能力覆盖不同CAC水平的重要性。 文章进一步探讨了“努力”的意义——在CAC必然上升的趋势下,精细化的运营(如裂变、广告优化)能像压弹簧一样,在同一圈层内尽可能降低CAC。作者还强调了流量的季节性波动、留存问题的复杂性(可能源于渠道不匹配或短期活动),以及流量红利载体(从App到小程序、共享设备)的快速变迁。最后,他提出了一个评估流量价值的双维视角:用户交互时长与支付金额,并回归到产品市场契合度(PMF)与增长公式的结合,才是驱动增长的王道。 对于运营者或产品经理而言,这篇文章最大的启发或许在于:增长不是套用单一公式,而是持续、动态地计算不同用户群的商业模型,并敏锐捕捉变化中的流量机会。
风投是如何进行投资判断的
从腾讯投资部转身投入一线创业公司,资深投资人 Annie 的职业选择背后,藏着一个被无数创业者追问的问题:风投机构究竟如何判断一个项目?这篇文章借由她的亲身观察,为我们拆解了投资决策中那些“看不见的标尺”。 Annie 在普林斯顿大学的学术背景与在腾讯投资部的实战经验,让她练就了一套犀利的评估框架。当她深入猿辅导这家数据表现堪称优异的公司后,她发现投资判断远非数据报表那么简单。文章的核心观点在于,顶尖风投的决策往往是理性计算与感性洞察的结合体——既会严谨分析公司的增长曲线、单位经济模型与市场天花板,也会深度拷问创始团队的愿景、韧性与进化能力。 这对读者最大的启发在于,无论是创业者准备融资,还是从业者想理解资本逻辑,都不能只停留在“把故事讲好”或“把数据做漂亮”的层面。真正打动投资人的,往往是团队对业务本质的深刻理解,以及在不确定性中持续找到正确方向的证明。投资判断的本质,是在当下数据与未来可能性之间做出一道高风险的权衡题。
阿里面试题:为什么Map桶中个数超过8才转为红黑树
这篇讲的是一个经典的Java面试题:为什么HashMap的桶中链表长度达到8才转为红黑树?作者从一个好友的阿里面试经历切入,直接打开了源码中的注释,发现它只记录了阈值,却未解释原因。 文章的核心在于对源码“Implementation notes”的深入解读。作者指出,红黑树节点占用的空间是普通节点的两倍,因此转换是一种空间与时间的权衡。更关键的是,文章引用了源码中一段关于泊松分布的注释:在随机哈希算法下,桶中节点数量遵循特定的概率分布,链表长度达到8的概率极低(仅约千万分之六)。这从统计学角度证明了阈值8的选取并非随意,而是经过严谨计算的。 此外,文章也驳斥了一种常见但不够严谨的“性能对比”解释,强调了设计背后的科学性。通过剖析源码与概率模型,这篇文章将一个常见面试考点还原成了其严谨的设计思想,适合所有想理解Java集合框架底层优化的开发者。
一些不常见但是很重要的数据结构
这篇源自Stack Overflow高赞讨论的整理,系统梳理了那些在日常编程中不常被提及、却在特定领域发挥关键作用的数据结构。文章并非泛泛而谈,而是紧扣具体应用:比如Bloom filter如何在BigTable、Cassandra中用于快速存在性检查,Skip list作为Redis有序集合的底层实现原理,以及Rope数据结构如何通过高效的字符串拼接操作,在Java等语言中胜任繁重的文本处理任务。 作者将这些结构与经典方案对比着介绍,突出了各自的核心价值:Splay tree的简洁与良好性能,Suffix tree用于字符串搜索的O(n)构建优势,以及Cuckoo Hashing利用多哈希函数提升空间利用率的巧妙思路。同时,文章也涵盖了并查集、Merkle tree、无锁数据结构等并发与特定场景下的利器,甚至提及了缓存参数无关、左偏红黑树等更前沿的方向。 整篇文章更像一份精心挑选的“数据结构工具箱”清单,它不仅扩充了开发者的知识库,更揭示了在解决特定性能或规模问题时,超越常规选择的可能性。对于想夯实基础、或寻找更优解方案的技术读者,这份清单提供了明确的索引和深入探索的起点。

美团面试经历,贡献出来一起学习
这篇讲的是一位程序媛分享她应聘美团大数据研发实习生的四轮技术面试经历。文章按时间顺序,详细还原了从简历筛选到最终HR面的完整过程,像一份真实的面试笔记。 面试内容覆盖面非常广。一面由部门主管在会议间隙进行,侧重项目架构与设计模式;二面长达一小时,深入考察了Spring机制、多线程、JVM内存与GC、MySQL优化等核心知识;三面是交叉面试,增加了在线编码环节;最后的HR面则异常“硬核”,面试官对项目细节和科研经历进行了深度追问。 作者在应对面试时有不少值得借鉴的思路。例如,面对不熟悉的问题(如服务器配置)坦诚相告;在解释Spring IOC/AOP时,用项目实例来证明理解;遇到不确定的技术点(如Java异步IO)时,坦然说明并向面试官展示自己的推理过程。文章也记录了面试官“边面试边给反馈”这类有助于候选人调整状态的细节。 文末,作者总结了对此次面试的反思:技术基础(算法、框架原理)需要扎实,面试中要主动引导节奏展示自己的知识体系,而对于高并发、分布式等工程经验,在校生只能通过理论学习先行铺垫。这为准备技术面试的读者提供了切实的参考。
哈希函数介绍 | 哈希算法
这篇讲的是哈希函数的核心概念与各类算法的应用对比。作者从哈希函数作为关键字到存储地址的“映射”本质出发,重点解析了哈希应用中需要解决的“冲突”问题。 文章的核心在于系统梳理了几类主流的加密哈希算法。它介绍了MD5、SHA-1、SHA-2、SHA-3及RIPEMD-160的基本原理,并结合Node.js代码示例,直观展示了它们的输出。关键点在于对比了它们的安全状态与适用场景:例如,MD5因碰撞问题已不适合安全用途,更多用于文件校验;SHA-1正被各大厂商逐步弃用;而SHA-2与SHA-3则代表了当前更安全的选择。 除加密算法外,文章也简要提及了用于高速查找的非加密算法,如MurmurHash,拓宽了“哈希”的应用图景。整体上,文章清晰地梳理了“为何用哈希”以及“如何根据场景选择不同哈希算法”这两个核心问题。
一维数组的聚类
这篇讲的是如何更智能地划分一维数据的区间。作者从分析订单价格分布的实际问题出发,指出简单按固定梯度(如每100元)划分可能忽视数据中天然存在的“分隔点”(比如Airbnb房价分布),导致分组不自然。 文章详细比较了三种解决一维聚类的方案。首先是将数据reshape成二维后使用通用的K-Means算法。其次是专门针对一维数据的Jenks Natural Breaks自然断点法,它通过最小化类内方差之和来寻找最佳分界点,并探讨了使用GVF指标来确定最优聚类数K的经验方法。第三种是利用核密度估计,通过寻找概率密度曲线的极值点(波峰与波谷)来自动划分数据。作者不仅阐述了原理,还提供了Python实现代码,清晰地展示了如何运用Jenks算法计算GVF值,以及如何用KDE寻找数据的自然断裂处。整个对比有助于读者根据数据特点和分析需求,选择最合适的区间划分工具。
相似度计算之兰氏距离
这篇讲的是相似度计算中的兰氏距离,也被称为堪培拉距离,它被认为是曼哈顿距离的加权版本。作者从定义公式出发,展示了兰氏距离如何通过绝对差值除以绝对值之和来计算两个向量间的距离,公式为 \( d(\mathbf{p}, \mathbf{q}) = \sum_{i=1}^{n} \frac{|p_i - q_i|}{|p_i| + |q_i|} \)。 兰氏距离有几个关键特性:它对接近于零(大于等于零)的值的变化非常敏感,这使得它在处理包含小数值的数据时特别有用。同时,与马氏距离类似,兰氏距离对数据的量纲不敏感,无需标准化即可处理不同尺度的变量。不过,它假定变量之间相互独立,没有考虑变量间的相关性,这在某些复杂数据场景下可能限制其应用。相比之下,曼哈顿距离更简单但缺乏加权机制,而马氏距离能捕捉相关性但计算更复杂。 文章还提供了Python实现,代码简洁地通过循环累加每个维度的距离贡献,并处理了零值情况。这种实现突出了兰氏距离在实际编程中的易用性,适合快速集成到数据分析流程中。整体上,这篇文章清晰地剖析了兰氏距离的核心概念、优缺点和实际应用,帮助读者理解它在选择距离度量时的独特价值。
常见相似度计算方法回顾
这篇技术博客系统梳理了数据科学和机器学习领域常见的五种相似度度量方法,为相关从业者提供了一个清晰的快速参考。文章从基础的空间距离概念出发,依次回顾了欧几里得距离(直观的直线距离)、曼哈顿距离(各坐标轴绝对差值之和)、闵氏距离(前两者的泛化形式)、余弦相似度(衡量向量方向差异而非长度)以及杰卡德相似度(基于集合的交并比)。 每种方法都配有形象的示意图和简洁的Python实现代码,使得理论概念与实践应用得以紧密结合。作者不仅解释了各自的数学定义,还隐含了它们的应用倾向:例如,欧氏距离适用于空间聚类,余弦相似度常用于文本向量比较,而杰卡德相似度则擅长处理离散的集合数据。 整体而言,这是一篇非常实用的“备忘录式”文章。它没有深入推导公式,而是通过清晰的对比和可运行的代码,帮助读者快速重温或上手这些关键工具,尤其适合需要在不同场景下选择合适度量方法时进行查阅。
相似度计算之马氏距离
这篇讲的是马氏距离(Mahalanobis Distance)。作者首先指出了它和常见的欧氏距离的本质区别:马氏距离通过引入协方差矩阵,巧妙地“吸收”了数据各维度之间的相关性,并且不受量纲(测量单位)影响。 文章的核心在于解释它如何工作。简单说,马氏距离可以看作是将原始数据投影到由协方差矩阵定义的“标准化”空间后的欧氏距离。文中用了一个直观的图示:在椭圆形的等高线分布中,红点到黑点的欧氏距离小于绿点到黑点,但若考虑数据分布的相关性,马氏距离的结论可能正好相反。这清晰地展示了它在处理特征相关时的威力。 文章不仅梳理了方差、协方差等前置概念,给出了严谨的数学定义,还提供了完整的Python计算示例,使用的是跨国数据。最后,作者总结了马氏距离的优点(如排除相关干扰、满足距离公理)和一个潜在缺点(可能夸大微小变化变量的作用)。 从理论概念、直观图解到代码实践,这篇文章为理解这个重要的相似度度量工具提供了一个相当完整的入口。
相似度计算之切比雪夫距离
这篇讲的是相似度计算中的切比雪夫距离,文章从国际象棋中国王的走法这个生动例子切入,解释了这种距离也被称为“棋盘距离”的由来——即两点间坐标差的最大值。 作者从二维平面的定义出发,将其推广到n维向量空间,并点明了它与闵可夫斯基距离的深层联系:切比雪夫距离是p趋向无穷大时的闵可夫斯基距离。文章还提供了清晰的Python实现代码,方便读者直接上手应用。 尤为精彩的是后半部分对切比雪夫距离与曼哈顿距离的对比。两者定义看似不同,但作者通过几何直观展示了它们的相互转化关系:将代表曼哈顿距离的正方形旋转45度并缩放,即可得到代表切比雪夫距离的正方形。这种视角揭示了不同距离度量在本质上的内在关联,有助于读者更灵活地选择和使用合适的距离计算方法。
密度聚类算法之OPTICS
这篇讲的是密度聚类算法OPTICS。它出发点是为了解决经典DBSCAN算法对邻域半径Eps和最小点数minPts这两个参数过于敏感的痛点。OPTICS作为DBSCAN的扩展,核心优势在于让聚类过程对半径参数Eps不再敏感,只需设定好minPts,轻微的Eps变化就不会干扰最终的聚类结构。 为了达成这一点,文章解释了两个关键新定义:核心距离和可达距离。核心距离是一个点成为核心对象所需的最小半径;可达距离则结合了核心距离,决定了点在排序中的位置。算法并不直接输出簇,而是通过维护“有序队列”和“结果队列”,生成一个基于可达距离的样本点排序。这个排序信息非常丰富,从它可以推导出在不同参数设置下DBSCAN的聚类结果。 最终,我们可以将这个排序可视化:以输出次序为横轴,可达距离为纵轴绘图。图中的“山谷”代表簇,谷越深簇越紧密;平坦区域或凸起则可能对应噪声。通过设定一个距离阈值切割这个图,就能灵活提取出聚类结构。文章最后还提及了OPTICS在异常检测、子空间聚类等方向的扩展算法。
聚类算法之ISODATA
聚类算法中的K-Means虽然经典,但需要预先设定簇数K且对初始中心敏感。这篇讲的是ISODATA算法,它作为一种迭代自组织数据分析方法,核心改进在于让聚类过程能够动态调整簇的数量。 文章指出,ISODATA在K-Means基础上引入了“合并”与“分裂”两个关键操作:当两个簇中心过于接近时进行合并,而当一个簇内部样本过于分散或数量过多时则尝试将其分裂。算法需要用户提供几个关键参数,如预期的初始簇数、允许的最小样本数、方差阈值等,这些参数共同划定了簇数量最终可能变化的范围(通常在初始设定值的半倍到两倍之间)。 作者也点明了ISODATA的一个现实困境:虽然原理直观地解决了“K值设定”难题,但由于需要调整的参数较多,且部分阈值难以准确指定,这使得它在实际应用中反而不如更简单的K-Means受欢迎。文章通过对比K-Means,清晰阐述了ISODATA的机制与适用边界。
K-Means算法之K值的选择
这篇讲的是K-Means聚类中一个经典又棘手的问题:当数据维度高、无法肉眼观察时,该如何确定聚类数K? 作者从最简单的“拍脑袋法”开始,比如用样本量估算,快速过渡到更可靠的方法。重点介绍了两种实用技术:一是直观的“肘部法则”,通过绘制K值与误差平方和的关系曲线,寻找拐点来确定最佳K值;但作者也指出,当拐点不明显时,这个方法就失效了。因此,文章引入了斯坦福大学提出的“间隔统计量”方法,它通过蒙特卡洛采样构建参考分布,进行更严谨的统计推断来选择K值。 文章不仅清晰解释了原理和公式,还直接附上了两种方法的Python实现代码。整体来看,它把从经验法则到统计方法的演进路径讲得很清楚,并且提供了实操性强的工具,帮助你在面对不同数据时,做出更合理的选择。