如何使用1M的内存排序100万个8位数
这篇讲的是如何在仅有1MB内存的约束下,对100万个8位整数进行排序的经典算法难题。问题最初源于Stack Overflow,看似无解——毕竟100万个数直接存储就需要超过1MB的空间。文章介绍了一种巧妙的解法核心:不直接存储排序后的每个数字本身,而是利用它们已排序这一特性,转而记录相邻数字之间的差值。由于这些差值平均很小,理论上可以用大约7位(bit)来表示一个差值,总计约0.875MB,从而在1MB内存内完成编码存储。实现上采用了高效的归并排序,并利用算数编码或哈夫曼编码对差值进行压缩编码。作者还分享了完整的339行实战代码,并提到了其他程序员的不同解题思路,展现了算法在极端约束下化不可能为可能的魅力。
一个故事告诉你比特币的原理及运作机制
这是一篇通过虚构故事来讲解比特币核心原理的科普文章。作者以“比特村”的货币演变史为线索,从以物易物、实物货币、符号货币到中央虚拟货币,逐步揭示出中心化记账的弊端——依赖个人信用、存在单点故障。在故事的关键转折点,一位名为“中本聪”的角色提出了比特币这套分布式解决方案。 文章的重点不在于深入技术细节,而是生动地拆解了比特币系统的基础构件:将公开账本作为公共数据库,通过“保密印章”与“印章扫描器”的比喻形象解释了公钥加密的身份认证与数字签名机制。核心部分则聚焦于“矿工组织”如何通过共识工作(即“挖矿”)来共同维护和验证这个分布式账本,包括收集交易、填写账簿、解决哈希难题(比喻为“寻找幸运数字”)并竞争记账权。 作者将复杂的区块链、工作量证明等概念,巧妙地转化为村民合作记账、防止作弊的日常场景。这种叙事方式清晰地勾勒出去中心化网络如何通过密码学与经济学激励,建立起无需信任第三方的价值传输体系,适合想快速建立比特币宏观认知的读者。
基于用户尺度评价的人物角色分类方法与实践
这篇讲的是一种基于用户关注度的人物角色分类实践,以1688网站的供应商信息调研为具体案例。 文章从“用户关注什么”这一核心目标出发,通过一份覆盖3032名有效用户的问卷,收集他们对17项供应商信息的5级关注度评分。接着,作者运用项目分析、信度检验和因子分析,将纷杂的信息项收敛为四个关键的评价维度:基本信息、客户满意度、供应能力和交易历史。 基于这四个维度的因子得分,研究进一步对用户样本进行聚类,最终识别出三类典型角色:高度关注所有信息的“全面考察型”(占42.5%)、尤为看重满意度的“口碑驱动型”(占41.9%)以及关注度普遍较低的“轻度浏览型”(占15.7%)。这种划分直接揭示了不同用户群体在决策时的信息需求重心。 文章的价值在于,它展示了一套从量化数据到设计洞察的完整流程。这些发现不仅为1688重构供应商信息页面的布局逻辑(如聚合关联信息)提供了依据,也说明了基于用户行为的分类如何辅助设计师识别核心用户,并理解其行为背后的动机,让设计决策更有据可依。
如何让玩家相信游戏是公平的
这篇文章从经典赌场骰子游戏的公平性争议出发,探讨了将游戏搬到线上后,如何用技术手段建立玩家信任。作者指出,许多争议源于游戏实现者的贪心而非规则缺陷,并由此引出一个关键问题:如何证明骰子结果在下注前就已确定,而非根据玩家行为动态调整? 文章提出了一套基于MD5哈希的简易验证方案。核心思路是:系统在每局开始前,先生成三个包含随机骰子数字的字符串,计算并公开其MD5值;玩家下注后,系统再公布原文,玩家可自行校验MD5是否匹配。由于MD5的不可逆性,这能在逻辑上保证结果未被篡改。文中进一步探讨了MD5碰撞攻击的可行性,指出单区块碰撞的计算复杂度(约2^50次运算)远超普通设备能力,并建议通过链入上局数据来进一步增强安全性。 整体而言,文章用通俗的案例引出了一个实用的工程信任构建方案,说明即使是复杂的公平性问题,也能通过巧妙、透明的技术设计来赢得用户认可。
贝尔实验室的历史
这篇讲的是那个诞生了Unix、C语言和晶体管的传奇实验室——贝尔实验室的完整身世。 作者从自己学习Go语言时产生的困惑出发:电话发明者贝尔和实验室到底是什么关系?实验室在AT&T、朗讯、阿朗等不同名字间辗转,其本质是什么?文章沿着电话发明者亚历山大·贝尔1876年创立贝尔电话公司这条线索,一路梳理了其后继者AT&T公司的发展,并重点追踪了隶属于AT&T的贝尔实验室如何成为“科技圣地”,最终在产业变革中被拆分重组的历史脉络。 它理清了从贝尔个人发明到庞大研发机构,再到被并购拆分的完整演变路径。对于想弄明白“贝尔实验室”这个闪耀又复杂的名字背后究竟是一段怎样的公司史与科技史的读者,这篇梳理提供了一个清晰的时间线与故事框架。
生成特定分布随机数的方法
这篇讲的是如何用均匀分布的随机数,生成高斯、指数等特定概率分布的随机数。作者从最基本的算法出发,深入剖析了Inverse Transform Method(逆变换法)和Acceptance-Rejection Method(接受-拒绝法)这两种经典方法的原理。 逆变换法的核心思想很巧妙:如果你能求出目标分布累积分布函数(CDF)的逆函数解析式,那么只需对一个均匀分布随机数进行逆变换,就能直接得到目标分布的随机数。文章以指数分布为例,清晰地展示了从CDF推导到Python实现的完整过程。 但逆变换法有局限,当CDF逆函数难以求解时怎么办?这就引出了接受-拒绝法。它的思路是先生成一个容易处理的提议分布,再通过一个“筛选”步骤,以一定的概率接受或拒绝样本,最终得到目标分布的样本。这种方法只需要知道目标分布的概率密度函数(PDF),适用范围更广。 除了这两种基础算法,文章还探讨了组合算法以及如何生成具有相关性的随机数等衍生方法,构建了一个较为完整的知识框架。
在2048里能够得到的最大的数是多少?
这篇讲的是2048游戏的一个数学极限问题。作者从Michael Brand的一个谜题出发,探讨了在这个著名的合并数字游戏中,理论上能得到的最大数字究竟是多少。 文章首先简明地解释了游戏规则,然后切入核心证明:为什么2¹⁸ (262144) 这个数字在4×4的棋盘上永远无法得到。作者通过一个巧妙的二进制分析指出,棋盘上所有数的总和的二进制表示中,“1”的个数不可能超过棋盘格子数16。而要产生一个2¹⁸,其总和的前一步必然是一个二进制“1”个数达到16的状态,这意味着棋盘恰好被2²到2¹⁷这16个不同数字块完全填满,无任何合并空间,游戏直接结束。 由此,131072 (2¹⁷) 成为理论上限。但作者进一步指出,这个数字本身能否达成仍是一个开放问题。尽管有玩家声称成功,但缺乏完整演示过程。文章留下了两种可能性:要么找到一种确定的构造方法来达成131072,要么给出一个更严密的证明来否定它。这使得一个看似简单的游戏,引向了一个关于数学构造与边界的有趣思考。
用牛顿迭代法求整数的平方根
这篇文章讲解了如何用牛顿迭代法解决一个经典的编程面试题:求整数的平方根。作者直接给出了一个基于 double 类型的 C++ 实现,并解释了其核心思路——利用迭代公式不断逼近平方根值,当相邻两次迭代结果差值小于1时即终止,最终取整。 文章的巧妙之处在于指出了实际实现中的几个关键细节。例如,代码对输入为0和1的情况做了预处理,并在最后通过 `floor` 和条件判断确保结果严格是小于等于原始整数的最大整数。作者也坦诚分享了一个尝试:他曾想用有理数运算避免浮点误差,但发现迭代次数增多后分子分母极易溢出,此路不通。 最后,作者点明这段代码的定位:它足以应对面试考察,但在生产环境中,面对性能要求时,可能存在更优的方案(如打表预计算)。这提醒读者,算法选择需结合具体场景,在理论正确性与工程实用性之间做好权衡。
纯属偶然——我和正则表达式的缘份
这篇讲的是作者如何因一系列偶然,与正则表达式结下不解之缘。他从一个毫无项目经验的职场新人说起,接到从HTML抓取信息的任务后束手无策,直到项目经理点拨“查查正则表达式”,才在那个周五下午找到了解题的钥匙。 从偶然使用到主动深入,他通读了《精通正则表达式》,又因一次偶然机会获得了翻译此书的宝贵机会。作者反思,这背后是大学时练习的翻译技能、热心前辈的指点、公司提供的实践任务以及善用Google的自学能力共同作用的结果。 文章最终指向一个朴素的思考:他认为真正的“价值”在于掌握自己认定的重要工具与技能,并在生活中不断运用智慧。就像计算机科学中用更优算法解决复杂问题一样,在一切事务上施展智慧,才是他所认定的价值所在。这段技术与个人成长交织的经历,或许能给初入行或正感到迷茫的技术人一些共鸣与启发。
面试总结[2014.06]
最近,一位工作7年的程序员分享了他密集面试百度、阿里、小米、美团、雅虎等多家公司的详细总结与思考。文章从一次略带遗憾的求职经历切入,深入剖析了国内技术面试的几个核心考察维度。 作者对面试环节的观察颇为犀利。他认为,当前面试对“编码能力”的实际考察不足,而对“算法”考察的侧重点(如是否追求标准答案)值得商榷。在“概念知识”与“项目经验”环节,他指出面试容易陷入“你知不知道”和“销售能力”的比拼,而非真正评估解决问题的能力。相比之下,雅虎面试新技术广度,阿里考察底层深度,小米采用类似谷歌的“基础能力优先”招聘风格,都给他留下了较好印象。 文章不仅分享了各家公司的面试风格差异与薪酬职级对比,更抛出了一个核心观点:面试官如何设计问题,才能公平且有效地甄别出候选人的真实能力与潜力?作者对面试体系的反思,或许能为同行带来一些启发。
用三段 140 字符以内的代码生成一张 1024×1024 的图片
这篇讲的是 StackExchange 上一个名为 “Tweetable Mathematical Art” 的硬核编程挑战。参赛者需要仅用三段不超过 140 字符(相当于一条推文长度)的 C++ 代码,生成一张 1024×1024 像素的彩色图片。规则是实现 RD、GR、BL 三个函数,分别对应红、绿、蓝三原色通道,通过数学计算为每个像素点赋值。 文章的核心亮点在于展示了极简代码如何创造出令人惊叹的视觉艺术。例如,Martin Büttner 的作品仅用寥寥几个三角函数就生成了绚丽的渐变图案;而排名第一的作品更是利用随机数和递归,在极短的代码内实现了类似分形的纹理效果。文章还列举了用极简代码绘制 Mandelbrot 分形集的实例,颠覆了人们对复杂图形生成代码量的认知。 这些参赛代码巧妙利用数学公式、随机种子甚至静态变量,在字符限制内实现了图像算法的核心逻辑。文章不仅分享了有趣的代码片段,更展现了在极限约束下编程的创造力和美学,对于理解图形学原理和代码压缩技巧都很有启发。
文明上网,普及科学,传播价值
针对VPN连接不稳、频繁断开影响技术工作的痛点,作者从自身实践出发,分享了一套基于GRE隧道和策略路由的自建“科学上网”方案。核心思路是在国内服务器与海外服务器之间建立一条稳定的GRE隧道,并通过`iproute`策略路由,实现国内流量直接从国内网关出去、国际流量则经隧道从海外出去,从而在保障访问Google等资源速度的同时,避免了所有流量绕行海外的低效问题。 文章详细列出了从建立隧道、配置双向路由规则、通过APNIC数据自动生成中国IP路由表,到设置NAT和调整MTU以确保稳定的完整操作步骤。这套方案相比依赖第三方VPN,显著提升了连接的可靠性和上网速度,为有类似需求的读者提供了一套思路清晰、可落地的实现参考。
Dijkstra算法求解最短路径分析
这篇讲的是如何用Dijkstra算法在图中寻找最短路径,尤其针对无向图且边权为正的常见场景。作者通过一个清晰的六节点图示例,生动演示了算法的核心机制:从起点开始,通过一轮轮的计算,逐步确定每个节点最短距离及前驱节点,最终构建出完整的路径。例如,从节点1出发,第一轮就找到了到节点2的最短距离为7,后续轮次中不断用新发现的更短路径去更新之前节点的估计值,像“经由节点3再到节点6的距离14,优于直接到6的无穷大”这种逐步松弛的过程。 文章不仅讲解原理,还提供了算法的伪代码和一段可运行的Java实现。代码使用邻接矩阵存储图,并定义了`shortest`数组记录距离、`visited`数组标记已确定的节点。其中最核心的循环包含两个步骤:先在未确定节点中找出当前距离最小的节点,再以该节点为跳板,尝试更新其所有邻居节点的距离值。 通过这个从原理到代码的完整剖析,文章让Dijkstra算法这个经典图论问题的求解过程变得具体而易于理解,展现了算法设计的精巧逻辑。
15道使用频率极高的基础算法题
这篇讲的是程序员面试中常见的15道基础算法题的思路解析与实现。作者从链表操作、数组处理、二叉树和栈队列等经典数据结构入手,详细拆解了合并排序、删除节点、查找倒数第K个节点、反转链表等高频考点。文章不仅列出了问题,更关键的是提供了具体的解题策略,比如用双指针在O(1)时间内删除节点,通过两个栈实现队列,以及利用后序遍历构建二叉树镜像等。每道题都附有清晰的C++代码示例和关键步骤注释,将抽象的算法逻辑转化为了可运行的实现。这些题目覆盖了排序、查找、递归、位运算等多个核心算法思想,对于夯实编程基础和准备技术面试都是不错的实战参考。
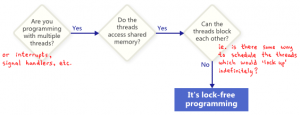
lock free的理解
这篇文章帮读者厘清了一个常见误解:很多人以为“无锁”(lock free)就是指程序不使用互斥锁,但实际上这个概念与“用不用锁”并无直接关系。作者指出,lock free的正确定义是:程序能够保证在所有线程中,至少有一个线程可以持续推进,而不会互相阻塞。这意味着即使某个线程挂掉,整个程序的执行流依然能够向前。 文章用一个典型的无锁循环代码举例——两个线程不断交替修改同一个变量,结果却可能互相卡死,这恰恰说明“不用锁”未必就是 lock free。相反,使用锁也可能实现 lock free 的特性,关键在于设计是否保证了系统整体的进展性。 最后,作者提到在实际编码中,lock free 的实现通常依赖 CAS(Compare and Swap)这类硬件支持的原子操作,从而在避免传统锁开销的同时,保障并发安全与性能。
2048-AI程序算法分析
这篇技术博客深入剖析了2048游戏背后AI程序的决策核心。作者从游戏可被抽象为信息对称双人对弈模型入手,揭示了AI以超过90%概率通关的关键,源于对经典博弈算法的巧妙运用。 文章首先用“三张纸币”的直白例子,阐释了Minimax算法的“悲观决策”思想:它假设对手完美应对,于是AI总在自身可能的最坏结果中选取最优路径。紧接着,针对Minimax随搜索深度指数级增长的计算瓶颈,文章详细拆解了Alpha-beta剪枝的工作原理。通过逐步推演搜索树的构建过程,生动展示了算法如何利用α和β两个边界值,提前裁剪掉那些“不可能更优”的分支,从而在不改变最优解的前提下,将搜索效率提升近一倍。 最后,文章分析了开发者将这套算法落地于2048的具体实现。这篇分析不仅清晰传达了核心算法的逻辑,更通过完整的决策树推演,让读者直观感受到算法如何从理论走向实践,为理解类似游戏AI的开发提供了扎实的范例。
趣题:用 k × 1 的矩形覆盖 n × n 的正方形棋盘
这篇讲的是一个有趣的棋盘覆盖问题:用 k×1 的小矩形去铺满 n×n 的大棋盘,如果无法完全盖住,那么总有一种方案能使得剩余的空格数 m(n, k) 达到最少。文章的核心结论是,这个最小的剩余格子数,无论 n 和 k 取何值,永远是一个完全平方数。
作者从问题的直观定义出发,首先处理了 n
数据可视化初体验(R语言)
这篇文章以作者初入数据可视化领域的体验为线索,分享了其核心理解与R语言实践。作者引用“图画最大价值在于迫使我们注意到从未预料到的内容”这一观点,强调可视化不仅是展示数据,更能通过图像残留增强思考,揭示隐藏规律,并以Twitter用户分布图为例加以印证。 在实践部分,作者以中国航空数据为例,展示了如何用R的ggplot包将“实体”与“联系”的逻辑转化为可视化步骤:从用直方图展示机场航线数量,到在地图上叠加点线图呈现地理位置与航线网络,最终生成GIF动画,层层递进。文章还简要提及了基于Knitr包实现可重复自动化统计报告的方法,对比了其相较于传统数据报表的优势。 整篇文章从感性认识到理性实践,结合了数据可视化的哲学思考与R语言的具体实现,为初学者提供了一个清晰的入门框架与案例。
两两接触的等粗且无限长的圆柱体
这篇文章从一个生活化的场景——多人碰杯时的接触难题——出发,引出了一个经典的几何学谜题:最多能让多少个等粗且完全相同的圆柱体实现“两两接触”?对于有顶面和底面的圆柱体,Martin Gardner 记录过5个和6个的经典构造,而 George Rybicki 等人更早指出了7个的可能性。 然而,问题的真正难点在于一个更严苛的版本:如果圆柱体是**无限长**的,无法借助任何端面进行接触,情况会如何?这个由 John Littlewood 在1968年提出的挑战,在近期由 Sándor Bozóki 等三位研究者通过数学手段攻克了。他们建立了一个包含20个未知数与20个方程的庞大方程组,并通过数值计算成功找到了两组不同的解,从而证明在无限长的情况下,7个单位半径的圆柱体依然能够实现两两接触。 这篇短文清晰梳理了该问题从有限长到无限长的探索脉络,并展示了现代数学工具如何为解决经典猜想提供新路径。当然,如文中末尾所言,关于不同高径比下的限制情况,探索或许仍在继续。
Python语言的创始人解释为什么Python数组的索引从0开始
Python的创始人自己解释了,为什么Python选择从0开始索引数组,而不是像一些语言那样从1开始。 这个问题源于Twitter上的一次提问。他回顾了对Python有重要影响的几种语言:ABC语言(Python的祖先)使用1-based索引,而C语言使用0-based索引。他自己最早接触的语言如Algol和Fortran等则各有不同。 最终决定采用0-based索引的关键原因,是Python切片语法的优雅性。在0-based索引下,`a[:n]`可以清晰地表示“取前n个元素”,`a[i:i+n]`表示“从第i位开始取n个元素”。而在1-based索引下,要表达同样的“取n个元素”操作,就需要繁琐地写成`a[i:i+n-1]`,或者改用不直观的`起始索引+长度`的表达方式。 这种设计还带来了一个巨大的好处:当进行连续切片时,索引能够自然衔接。例如,要将数组在`i`和`j`两处分割成三部分,可以非常优雅地写为`a[:i]`、`a[i:j]`和`a[j:]`。切片的终点恰好是下一段的起点,无需做任何调整。 这种对语法简洁性的追求,深刻影响了Python日常编码的体验,让数组和列表的操作直观而富有美感。