取得当前script元素的src(path)
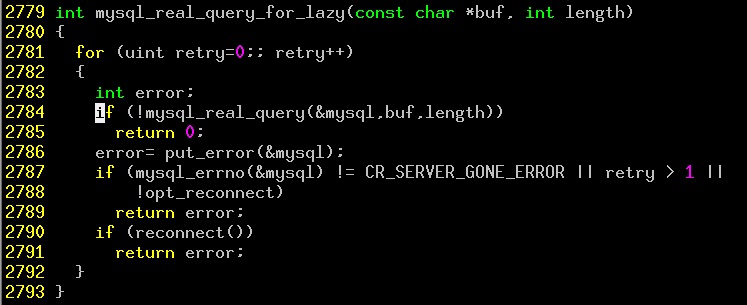
这篇讲的是如何在浏览器中准确获取当前正在执行的 script 元素的路径。作者从标准方案切入,介绍了 document.currentScript 这一便捷的 API,它不仅能拿到 src,还能区分脚本是同步还是异步加载。 不过,文章的重点落在了 IE 浏览器的“坑”上。当通过 document.write 动态插入多个 script 标签时,IE 下的 script readyState 状态与标准浏览器不同。例如,在一个由 a.js 动态写入 a.a.js 和 a.b.js 的场景中,a.a.js 通过 readyState 查找可能意外获取到 a.b.js 的路径,而其他浏览器则能正确识别自身。这揭示了 IE 独特的加载与执行机制:即便脚本已下载完成(loaded),其执行流程仍可能保持阻塞。 因此,作者提供了一个兼容函数,通过检查 document.currentScript 是否存在来降级,并针对 IE 实现了基于 readyState 的回退逻辑。文章通过这个具体的细节对比,点明了不同浏览器在脚本加载行为上的核心差异,对处理动态脚本场景的开发者有很强的实操参考意义。
本机暂存