关于“浏览器无法拦截的弹出窗口”、IE、Firefox弹出新窗口
这篇讲的是一个看似简单却让很多开发者头疼的问题:如何让JS打开的新窗口不被现代浏览器拦截。 作者从朋友的实际问题出发,梳理了两种常见但均已失效的“万全之策”。一种是通过脚本模拟点击隐藏的``标签,但这只在IE有效;另一种是模拟提交隐藏的`
本机暂存
采集自各技术站点的近期文章。
这篇讲的是一个看似简单却让很多开发者头疼的问题:如何让JS打开的新窗口不被现代浏览器拦截。 作者从朋友的实际问题出发,梳理了两种常见但均已失效的“万全之策”。一种是通过脚本模拟点击隐藏的``标签,但这只在IE有效;另一种是模拟提交隐藏的`
这篇是一位前端开发者为新手整理的 jQuery 学习路径指南。作者从三个具体资源切入:推荐《15天学会jQuery》作为入门,强调其基础全面;建议用jQuery 1.4.2的帮助文档反复练习常用函数,做到熟练掌握;进阶则可研读《悟透Javascript》深入理解本质。 文章特别指出,jQuery 只是 JavaScript 的一个函数库,想成为优秀的前端工程师,扎实的 JavaScript 基础才是根本,这能帮助开发者看清新技术不过是已有技术的延伸与组合。 除了资源,作者更分享了学习心态:编程如练武,需要“三十年磨一剑”的耐心,反对浮躁与急于求成。他认为,踏踏实实地积累三年,掌握 jQuery 的核心设计与源码思路,进入腾讯、百度等公司并非难事。全文贯穿着“大道至简”的务实哲学,将技术学习归于扎实的基础与长期的坚持。
这篇讲的是HBase的Block Cache——RegionServer中负责读缓存的核心模块。它从HBase的读写内存分工切入,解释了读请求如何依次查询Memstore、BlockCache和磁盘,并最终将结果缓存的完整链路。 文章重点剖析了BlockCache的“三级缓存”设计:新访问的Block放入Single队列,多次访问则升至Multi队列,而Meta表等关键数据则放入InMemory队列。这种分级策略既保护了关键元数据,又避免了全表扫描对热点数据的冲击。默认的内存分配比例(Single:Multi:InMemory = 0.25:0.50:0.25)和LRU淘汰策略,是其在内存限制下平衡命中率的关键。 作者还深入到了HBase 0.94.1的源码层面,以`LruBlockCache`类为例,展示了缓存Block时的类型判定逻辑,以及触发后台淘汰线程`EvictionThread`的阈值条件。从整体内存布局到具体的优先级队列实现,文章清晰地拆解了HBase在保证高并发读性能时,所采用的这套精巧的缓存管理思路。
这篇技术博客从实战角度出发,深入剖析了HBase客户端的Write Buffer机制。文章指出,每次单条Put都会引发一次网络往返(RTT),在数据量小、RTT较高的场景下,这个开销会成为性能瓶颈。通过开启Write Buffer进行批量提交,可以将N次RTT降低为一次,从而显著提升写入吞吐。 作者没有停留在概念介绍,而是结合HBase源码,揭示了底层实现细节:客户端会先按Region Server将Put对象分组打包,再统一发起RPC请求。文章还详细拆解了Write Buffer的触发条件(如autoFlush设置、缓冲区满),并给出了单个Put对象大小的预估公式 `((50~60) + L1) * N + L2 bytes`,帮助开发者根据自身数据特征(列数N、RowKey长度L1、Value长度L2)来预估并合理配置缓冲区大小。 最终,文章清晰地划分了适用场景:对于KB级别的小数据写入,调整Write Buffer收益明显;而对于MB级别的大记录,由于数据传输时间占主导,则不建议依赖此机制。这种从原理到源码再到实践的分析路径,为调优HBase写入性能提供了扎实的依据。
这篇讲的是淘宝搜索背后的个性化实时分析系统pora。文章从实际业务痛点出发:为了实现“千人千面”的搜索结果,原先依赖隔天跑批的用户属性计算存在延迟,无法捕捉用户当下的兴趣变化。核心方案是构建一个实时系统,通过Storm处理来自TimeTunnel的实时日志流,并与HBase中的离线全量计算结果合并,最终快速更新用户标签到在线存储中。 作者详细拆解了系统架构与拓扑设计。其亮点在于采用了“框架+插件”的分析模式,让算法逻辑可以灵活插拔;同时,在Joiner和Analyzer环节设计了可配置的微批处理,巧妙地在延迟和HBase的访问性能之间做了平衡。系统最终每天稳定处理几十亿条日志,将用户行为从产生到属性更新的延迟控制在了秒级。 文章末尾分享的经验教训尤为实在,比如为HBase表做预分区、Storm中emit tuple时避免修改list对象等,这些都是经过线上锤炼的宝贵实践。
这篇讲的是谷歌服务曾经历的一次全球性短暂宕机,作者作为一名CloudFlare网络工程师,从亲身参与修复的角度,带读者深入了一次真实的网络故障现场。 故事从发现谷歌所有服务(甚至包括其公共DNS 8.8.8.8)无法访问开始。作者通过追踪发现,本应由谷歌自己管理的IP地址,其BGP路由路径却诡异地指向了印度尼西亚的运营商Moratel。这揭示了问题的根源:一家ISP可能因操作失误(“胖手指”),错误地向其上游提供商(电讯盈科)宣告了本属于谷歌的IP地址,而后者信任了这一宣告,导致错误路由像涟漪般扩散至全球互联网。 文章核心观点在于阐释互联网如何建立在BGP协议的相互信任机制之上,而这种信任一旦被错误信息打破,即便是谷歌这样的巨头也可能服务中断。作者最终通过业界人脉直接联系Moratel公司才得以修复问题。这给我们的启发是:可靠的网络运维不仅关乎技术,也关乎全球协作网络与及时响应能力——即使你控制不了外部路由,也必须有团队时刻监控和管理你与世界的连接。

这篇讲的是一个关于MySQL触发器的有趣发现:它通常只用来做简单的表间更新,但有人用它在批量生成测试数据方面取得了意想不到的高性能效果。 文章作者首先用存储过程作为基准方案,在单线程下为一张包含1000万行记录的表造数据,耗时8分20秒,相当于每秒插入约2万条记录。这个速度本身已经不错。 但作者想测试触发器是否能做得更好。这里有个小限制:MySQL触发器不支持对同一张表进行自我插入,所以他额外创建了一张中转表tb3。核心方案是,为tb3创建一个`AFTER INSERT`触发器,当向tb3插入一条记录时,触发器会立即在目标表tb2中循环插入1000万条随机数据。 最终结果很亮眼:整个过程耗时5分14秒,相当于每秒插入超过3万条记录,比纯存储过程方案的速度提升了约60%。作者用“很HAPPY”来形容这个结果,因为通过一个简单的触发器设计,就显著优化了数据生成的吞吐量,为需要快速填充测试环境的场景提供了一个高效思路。
这篇讲的是产品设计中如何建立信任感——作者从快捷酒店管家的实际经历出发,复盘了几个关键的设计决策。 最初,产品因名称“酒店管家”与实际服务范围(仅快捷酒店)不符,导致用户产生预期落差。改成“快捷酒店管家”后,第一印象的误导问题得以解决。在预订按钮的文案上,从“官方直订”调整为“官网直销”,用更准确的术语明确了“酒店直供库存”的模式,缓解了用户对OTA的混淆感。流程上,他们在预订表单顶部保留用户已选的酒店和房型信息,让跳转不再突兀,增强了操作的连贯性。 更关键的是对“双向信任”的思考。作者坚持在首次预订时要求用户完成姓名、身份证和手机号验证,尽管早期引来抱怨,但这道门槛有效筛选了真实用户,也向合作酒店证明了平台的可靠性。此外,团队坚持由产品经理亲自处理客服,通过“活人”的响应传递团队的真实感。 文章最后也提到,某些安全产品会通过制造紧迫感(如“系统有严重漏洞”)来间接建立信任。整篇的核心在于:信任不是抽象的感受,而是可以通过产品细节——从命名、文案、流程到互动——一步步具体构建起来的。
这篇讲的是Shell里那些常被忽略但极其实用的“冷知识”和高效命令。作者从Shell的历史冷知识切入——它比所有流行的Linux内核都要年长,是先有Shell再有Kernel;并且在全球编程语言排名中,shell家族稳居前列,在GitHub上的项目数占比高达8%,与Java相当,印证了它在实战工程中的“宝刀不老”。 文章的核心部分分享了一系列能显著提升效率的命令行技巧。比如用“!$”快速引用上一条命令的最后一个参数,用“sudo !!”一键重跑上条命令并提权,或是用“cd -”在前后两个目录间快速切换。此外,还有像“^old^new”替换历史命令字符串、查看ASCII码表、远程执行脚本等数十个具体用法,每一个都配有清晰的使用场景。 这些技巧并非教科书上的基础内容,而是能立即应用于日常开发、运维工作的“甜点”。无论是想提升命令行效率的新手,还是希望查漏补缺的老手,都能从中找到立刻上手尝试的实用技巧。
这篇讲的是编程世界里那些被奉为圭臬、却常常断章取义的“神谕”,如何反过来成为技术债和团队协作的障碍。 文章以两句广为流传的名言为靶子:一句是 Donald Knuth 的“过早优化是万恶之源”,另一句是 Steve McConnell 的“好代码本身就是最好的文档”。作者指出,大家往往只记住了前半句的教诲,却忽略了其完整的、带有条件的上下文。这导致这些名言在实践中被异化成了逃避责任的借口。 比如,在“过早优化”的庇护下,一些工程师对明显的资源浪费视而不见。作者列举了公司内部的真实案例:一个模块因自建内存池管理不当,导致服务器周期性内存泄漏宕机;一个仅加载几KB配置的代码,竟因使用了巨大的固定数组而占用超过1GB内存;甚至一个公共日志库,无论是否开启日志,都会无谓地执行系统调用。在这些基础性问题面前,谈论“避免过早优化”显然为时过早。 而对于“代码即文档”的断章取义,则助长了不写注释的风气。作者犀利地指出,多数人的代码清晰度远未达到能自我解释的程度。当接手那些传说中的“大神”留下的、成百上千行无注释的代码时,带来的不是敬仰,而是维护的噩梦。因此,作者在团队中旗帜鲜明地主张:注释是不可省略的,甚至是应该强制执行的。 这些被简化的“神谕”,反而让开发者忽视了最基础的编码规范和资源意识。文章提醒我们,在引用任何原则之前,都需理解其全貌,否则它们可能从指引明灯,变成阻碍进步的绊脚石。
文章从实际业务需求出发,对比了三种点击日志记录方案。第一种是通过URL参数传递信息,在服务器端(如Nginx)记录请求日志;第二种是通过中间服务器进行跳转并记录,数据最完整,Google、百度等搜索引擎均采用此方式,百度每天十亿级网页搜索请求用约50台服务器即可承载;第三种是前端JavaScript监控上报,能记录悬浮、滚动等丰富行为,但普遍存在15%-20%的数据丢失率。 文章重点剖析了JS方案丢数据的根本原因:前端无法为每个事件立即发送请求,必须将行为缓存后批量上报。如果用户在上报触发前关闭浏览器或发生崩溃,这部分缓存数据就会丢失。这本质上是用户体验流畅度与数据完备性之间的权衡——上报越频繁,体验越卡顿但数据越完整;反之则数据丢失风险增加。同时,高频上报也会给日志服务器带来巨大压力。对于追求数据完整性的核心场景,跳转记录是更可靠的选择;而JS方案更适合需要采集丰富交互行为、对少量丢失可容忍的分析场景。
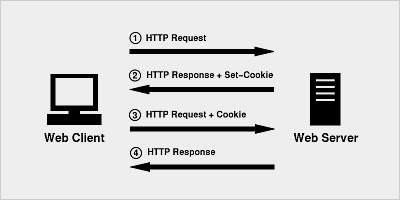
这篇讲的是PHP中Session的本质与安全陷阱。作者从HTTP协议无状态性这一底层特性切入,解释了为什么我们需要Session来维持应用状态。他详细拆解了Cookie作为HTTP扩展的工作原理,以及Session ID如何在客户端与服务器之间传递——无论是通过自动的Set-Cookie头,还是通过URL参数或POST数据。 文章特别强调,许多开发者误以为PHP内置的Session机制自动提供了安全性,但事实并非如此。作者通过一个具体的会话劫持攻击示例(攻击者窃取并重放PHPSESSID),清晰地展示了如果仅依赖默认机制,会话数据将面临风险。他指出,安全必须由开发者主动加固,而非框架自动保障。 整体上,这篇文章像一份面向PHP开发者的安全指南,从协议基础讲到实战风险,核心观点是:理解Session背后的网络交互细节,是构建安全会话管理的第一步。
这篇文章深入剖析了Oracle数据库中`CREATION_TIME`字段的底层存储机制,解答了“数据文件时间戳从何而来”这一问题。作者从`v$datafile.CREATION_TIME`与`v$datafile_header.CREATION_TIME`必须一致才能启动数据库这一现象切入,指出后者的值实际来源于数据文件头块中的`kcvfhcrt`字段。 核心在于,这个十六进制的`kcvfhcrt`值,是Oracle以1988年1月1日00:00:00为基准点,按“每月固定31天”的简化规则,累计计算出的秒数。文章详细演示了双向转换的算法:既如何将一个具体的日期时间(如2011-03-05 05:26:52)拆解计算为对应的十六进制值`0x2c67319c`,也展示了如何通过一系列除法和取模运算,将该十六进制值反向推导为准确的年、月、日、时、分、秒。 这套算法不仅是Oracle内部的一个实现细节,对于需要手动修复或验证数据文件头信息的DBA来说,也是一个非常实用的底层知识。文章通过具体的数值计算实例,将抽象的转换过程清晰地展现了出来。
这篇讲的是设计中潜藏的逻辑脉络。作者从逻辑的本源出发,结合自身经验,提炼出五种影响设计决策的思维模式。 文章首先介绍了经典的“古腾堡图表”阅读逻辑,即人的视线习惯于从左上角移向右下角,并通过一系列品牌海报案例,展示了如何利用这一规律引导用户视觉焦点。接着,阐述了“直线式逻辑”如产品详情页般自上而下、环环相扣的严谨性,以及“金字塔式逻辑”在网站架构中构建清晰层级关系的应用。 更有趣的是对“曲线式逻辑”的探讨。作者类比奢侈品市场中“越贵越买”的非理性消费现象,提出当产品的领先性与用户强烈欲望相结合时,也能形成一种突破常规但有效的设计推力,苹果产品就是例证。最后,文章回归到设计的基础——“网格”,强调它既是保持页面稳定、赋予元素秩序的框架,也是设计师在合理运用后可以灵活打破以创造惊喜的工具。 作者并未将设计逻辑视为刻板的教条,而是作为理解视觉沟通、平衡规范与创新的透镜。文章通过具体的模型和案例,为设计师提供了审视自身工作的多维视角。
这篇讲的是前端性能优化中一个核心但容易被忽略的话题:浏览器的重绘与重排。 文章从交互评审中常见的前端质疑切入,解释了浏览器从解析HTML到渲染页面的复杂流程。它清晰地区分了重绘与重排:重绘只是外观改变,不影响布局;而重排则意味着渲染树需要重新计算,性能代价高昂。例如,table布局可能需要三倍于普通元素的计算时间。 文章进一步剖析了触发重排的常见操作,比如改变几何属性、增减DOM节点,甚至获取某些特定属性值(如offsetTop)都会强制浏览器重排,使优化失效。对此,作者给出了具体的优化策略,包括将多次样式修改合并为一次CSS类切换、对动画元素使用绝对定位脱离文档流、在内存中操作完节点后再插入DOM,以及缓存那些会引发重排的属性值。 这些策略都指向一个目标:减少重排次数并缩小其影响范围。文章甚至提到,在前端面试中,实现一个考虑了重排优化的表格排序方案会是很好的加分项。
这篇讲的是正态分布为何能在数学中占据如此核心的地位。作者没有从复杂的公式入手,而是追溯其源头,揭示出一个优美的现象:从一些简单明了的初始准则出发,数学家与物理学家们竟屡屡被引领到正态分布的门前。 文章重点介绍了高斯在1809年的一条经典推导路径:他以“误差分布导出的极大似然估计等于算术平均值”为核心准则,从一个看似合理的测量原理出发,推导出了正态分布的概率密度函数。这仅仅是四条著名“小径”中的第一条,物理学家Jaynes在其著作中总结了四条通往正态分布的不同路径。 文章穿插了高尔顿对正态分布的诗意赞美,以及数学家将其视为“概率论初恋情人”的生动比喻,将冰冷的数学定理赋予了温度与美感。它想告诉我们,正态分布之所以无处不在,或许正是因为它背后蕴含的多种深刻而简洁的原理,如同“条条曲径通正态”。阅读它,就像跟随历史上的智者,一起欣赏通往真理的“条条曲径”。
这篇文章提供了一个轻量级的shell脚本,用于实时查看服务器的网络流量情况。脚本的核心思路是通过一个无限循环,每秒捕获指定网卡(默认是eth0)的接收(RX)和发送(TX)字节数,计算与上一秒的差值得到实时速率。同时,它还会累计总流量并计算平均速率,让用户对整体网络负载一目了然。 脚本设计得很实用,它会清屏并刷新显示,形成一个动态的监控面板。输出的信息结构清晰,包含了网卡、IP、当前时间、以及三组关键数据:当前速率(KB/s)、平均速率和总流量。对于需要快速诊断网络状况或进行临时监控的运维人员来说,这个即开即用的脚本提供了一个非常便捷的解决方案。文章不仅给出了完整的脚本代码,还附带了具体的使用方法和一段示例输出,展示了监控效果。
这篇技术博客系统梳理了互联网基础设施中的核心概念——DNS及其相关配置。文章从DNS(域名系统)的底层作用讲起,解释了它如何将人类可读的域名翻译为机器所需的IP地址,并特别强调了DNS服务器数量(通常至少两个)对解析稳定性的意义。 内容重点对比了A记录、AAAA记录、CNAME记录、MX记录和TXT记录等关键DNS记录类型。例如,A记录直接将域名指向IPv4地址,而CNAME则为域名创建别名,便于管理;MX记录专用于指定邮件服务器,是搭建企业邮箱的关键;TXT记录则常用于SPF反垃圾邮件验证。文章还厘清了子域名、泛解析(覆盖所有未定义的子域名)与域名绑定(将域名关联到特定服务器空间)之间的区别与应用场景。 对于需要管理域名的开发者或运维人员而言,理解这些概念的差异和适用条件,能更精准地完成网站部署、邮件服务配置或流量调度,避免常见的配置疏漏。
这篇文章聚焦于IE浏览器中一个不太为人熟知但相当实用的属性:documentMode。作者从“如何准确获取IE文档的兼容性模式”这一具体问题出发,清晰地介绍了该属性的用法。通过一个详细的表格,文章列出了documentMode在IE6到IE10以及各版本兼容模式下的具体取值,例如在怪异模式下值为5,在标准模式下则对应版本号(如IE8为8)。同时指出,只有在文档加载完成后才能获取正确的值。 文章不仅解释了属性本身,还引申出了其实际应用场景:利用documentMode来可靠地判断IE的各个历史版本。最后给出了一段简短的检测代码,逻辑清晰,直接解决了开发中的一个痛点。对于需要处理历史IE兼容性的开发者来说,这是一篇很实用的参考。
代码重构是提升软件质量的常见手段,但盲目重构往往带来更大风险,甚至导致系统崩溃。这篇文章的核心观点是:除非必要,否则不要轻易对代码进行大刀阔斧的改动。作者明确划定了“红线”——如果你不理解代码的历史背景、逻辑过于复杂、项目时间紧迫或你是团队新人,那么重构的条件并不成熟。 相反,在分析清楚代码臃肿原因、确保有充足时间与测试资源、且修改后逻辑将显著更清晰时,重构才是合理的。文章特别强调,所有重大修改都必须与团队共同决策。 如何安全落地重构?作者给出了几条关键建议:首要任务是建立自动化回归测试,以此作为快速验证修改的“安全网”;其次,应采用短周期的开发与发布模式,并将重构代码尽可能隔离,便于问题定位。同时,一份涵盖回归、功能、性能等多维度的测试计划必不可少。 文章还提倡“小粒度重构”,即在修改现有代码时顺手优化其局部,保持代码整洁,但务必与同事讨论。最终,作者提醒我们:忍住重构不理解代码的冲动,不断学习新技术,但更应审慎思考其适用场景,避免为了用而用。