今天遇到了一个奇怪的问题,两次ajax发送的同一个变量值,后端接收到的编码不一样……,一时间,我竟然发现自己对于编码的问题不能说的很清楚。
lisp主张代码即数据,其实我们写的代码也是数据(信息),数据的存储和传播都要就要涉及到编码的问题。就像我们向对方传递信息之前,先要问对方:can you spreak in english。
小贴士:嗨,你知道吗!windows的换行符是 \r\l,linux的是 \l,mac的是 \r,这是有意还是故意的呢……
本文会试图说清web开发过程中,如下方面的编码问题:
编码简史
文件编码
HTML编码
CSS编码
JavaScript编码
ajax编码
编码简史
如果想把编码问题说清楚,那恐怕你看到这里就会把页面关掉了,所以这里仅简要介绍下国内web开发中常用的一些编码。如果你了解或不感兴趣,可以直接跳过本部分。
ASCII/EASCII(ISO/IEC 646)
GB2312/GBK/GB18030
Unicode/UTF8/UTF16
进入数字时代,整个世界都要数字化,最先数字化的就是文字,老外的自我中心论,以为世上仅有abcd…… 26个字母,便发明了ASCII(美国标准信息交换码)。
ASCII 使用一个字节的低7位的不同组合来表示字母数字和一些其他字符,2^7 = 1287位二进制共可以代表128个字母。
后来为了表示更多的字符便将ASCII扩展为8位,称为EASCII,并等同于国际标准ISO/IEC 646。
而我们为了让汉语也能数字化,变发明了gb2312,gb2312使用两个字节16位表示汉字,为了兼容ASCII将每个字节的高8位置为1,共有14位可用,2^14 = 16384,但GB 2312标准共收录6763个汉字,后来发现不太够用,又扩展了gbk,gb18030。
终于老外发明了 Unicode,一切都解决了,Unicode有两个字节的16位的编码空间,Unicode是一个归法,比较常用的有UTF8和UTF16两种编码方式。
UTF8在web领域比较常用,是一种变长的编码方式,UTF16是一种定长方式。
最后来看一下,‘回’字的不同编码,要记住哦,后面会多次用到。
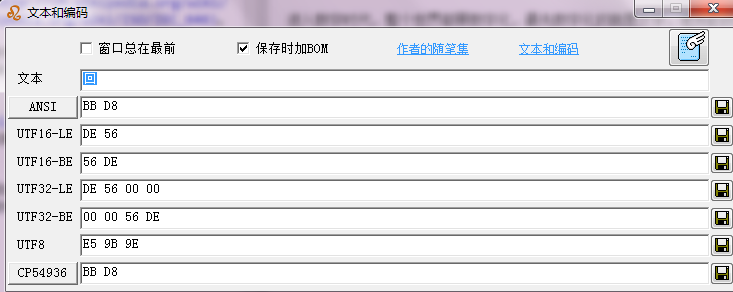
文件编码
文件编码也可以说是存储的编码。
我们写的代码,最终会以二进制的方式,持久化到计算机的存储设备中。
不同编码的文件,会以不同的规则存储到磁盘中,不同的编码要有自己独特的规则,这样才能在读取的时候不发生冲突,也就是要能识别出来自己,计算机在打开文件的时候都是靠猜测来解码的。
如果存储的编码(算法)和打开的编码(算法)不一致,就会出现乱码的情况。
文件在网络上传入要声明自己的编码,我们一定要清楚源文件的编码,然后才能进行后序工作。
对于前端而言会涉及html,css和js源文件的编码,而国内常用的编码如下:
ascii
gbk
utf-8
推荐大家用utf-8,不容易出问题,但由于历史原因,国内有很多网站的编码都是gbk,下面是BAT的网站情况:
qq.com gb2312
taobao.com gbk
baidu utf-8
百度历史比较悠久的产品线的编码也是gbk,比如百度知道。
HTML
网页中HTML的编码由哪些部分决定呢?真正运行在服务器上的HTML编码由下面几部分决定
HTTP头
meta
user-agent
上面给出的三个因素的权重是由高到低,也就是说HTTP头会覆盖meta的信息。
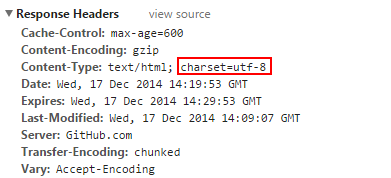
如果你还不知道什么是HTTP头那么请自行百度,HTTP头中的编码信息如下图中红色方块圈起来的部分,代表当前页面的编码是utf8。用户代理收到这个信息后,就会用utf8编码来将收到的字节流解码。
有些服务器会设置文件的默认编码信息,有些则不会,后端语言都可以自行设置页面的html编码,在php中设置http编码代码如下:
header("Content-Type:text/html; charset=utf-8");如果没有设置http头信息,或者在文件系统直接打开页面,html的meta标签就派上了用场,meta中可以设置http头信息,下面的代码和上面php的功能相同:
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">在html5中将上面的代码简化为如下形式:
<meta charset="utf-8">如果既没有设置http头,也没有meta标签,那么用户代码会使用系统的默认设置,windows下的中文环境的默认编码一般是 gb2312,所以用户代理就会用gb2312来解码页面,如果页面的编码也刚好是gb2312那么万事ok,否则就会出现乱码。
用户代理一般可以设置默认的编码是什么。比如chrome打开设置下的内容网络,会看到如下的设置界面。
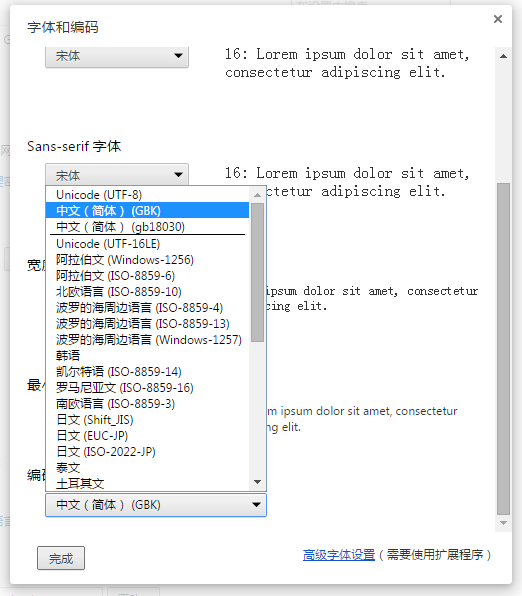
注:如果最终显示的编码和页面本身的编码不同就会出现乱码。
CSS
说完了HTML的编码再来说说CSS的编码,如果HTML文件和CSS文件的编码不一致,那么就需要单独声明才可以。
在html4中link有一个属性——charset可以用来指定引入css文件的编码,但这个属性在html5中已经废弃了,虽然废弃了但在浏览器中还是可以使用的,下面的代码显示指定css文件的编码为gbk。
<link rel="stylesheet" href="gbk-1.css" charset="gbk">然而html5废弃了这个属性那么该怎么办呢,其实废弃这个属性,是因为把这个功能代理给了css文件,css中有一个@charset指定,可以指定页面的编码,将下面的代码放在css文件的顶部,会显示声明页面的编码为utf8。
@charset utf-8那么问题来了,如果即设置了charset属性,又设置了@charset指定,结果是@charset指定会覆盖link的charset属性,charset属性已经废弃了,建议用css的@charset指令。
注:如果我们显示指定的编码和css文件的编码不一致也会导致乱码问题。
JavaScript
说清了CSS的编码,我们再来说JavaScript的编码问题,首先还是如果HTML文件的编码和JavaScript文件的编码不一致的话就会产生乱码,这时就需要我们显示声明一下js文件的编码才可以。
html中的script标签有一个charset属性,用来指定引入外部jss文件的编码(字符集)。下面的代码显示声明引入的js的编码是utf8。
<script src="***.js" charset="utf-8"></script>注:如果我们显示指定的编码和js文件的编码不一致也会导致乱码问题。
其实在JavaScript中仅支持utf16编码,其实也不是utf16,而是utf16的子集——ucs-2,这导致在js中无法表示BMP之外的文字(更多信息请看这里)。
无论js源文件的编码是什么,下面的源代码的输出结果是一样的——前提是解码js的过程正确。
'回'.charCodeAt(0)#输出 2223822238的十六进制表示是56 DE,而这正是‘回’字的utf16编码。
ajax
说ajax之前,先来说说表单提交吧,下面分别是utf8页面和gbk页面的表单提交请求,其中参数name是’回’字。可以看出表单请求的编码是由页面决定的。
http://localhost/github/webtest/charset/form.php?name=%E5%9B%9Ehttp://localhost/github/webtest/charset/form.php?name=%BB%D8ajax发送的代码也是由页面决定的,但我们在发送参数前都会encodeURIComponent一下,encodeURIComponent不管页面编码是什么,都会返回utf8编码。
让我们构造一个例子,页面A的编码为gbk,有如下的代码:
xhr.open("GET","form.php?name=" + encodeURIComponent('回') + 'namegbk=' + '回',true);我们看到发送的ajax请求如下所示:
http://localhost/github/webtest/charset/form.php?name=%E5%9B%9Enamegbk=%BB%D8这个例子巧妙的验证了上面的结论。
再来说说json,json只支持utf8编码,所以不要返回gbk编码的json。
总结
在信息交换的任何一个环节,如果编码信息和解码信息不一致都会产生乱码问题。
本文中的所有例子都可以从webtest下载。
关于编码还有很多东西可以需要学习,我强烈建议你可以阅读下参考资料里面的一些文章,同时我还建议您阅读”code“这本书。
