您现在的位置:首页
--> 其他
以前在Windows上面做过一些工作,那个时候还没有维基百科全书,很多计算机相关的概念由于是刚刚发展出来,身处其外的人往往不知道正确的含义。微软的技术那时候是最受开发人员关注的,当时也只有在Windows上做一些软件才可以赚钱,回想一下,微软没有推出App Store绝对是个极大的失策。微软的各种技术图书和开发工具涉及到很多的原创缩写词汇,让人不知所以,现在有个WIKI的归类总结我们才能真正的理解这些名词。下面列举一些例子: VBX:这个是我们在早期的VB乃至Delphi上面设计GUI的时候使用的控制。基于控件开发是当时的热潮,有公司专门出售这些控件,也有盗版光盘包含了很多的控件集合。试用各种控件也是学校生活的一部分。记得毕业实习的时候,用VB开发一个企业管理软件,有些高级表格需求windows自带控件无法实现,公司也是满世界去找。

缘起 随着移动互联网的发展,现在写web和我三年前刚开始写爬虫的时候已经改变了太多。特别是在node以及javascript/ruby社区的努力下,以往“服务器端”做的事情都慢慢搬到了“浏览器”来实现,最极端的例子可能是meteor了 ,写web程序无需划分前端后端的时代已经到来了。。。 在这一方面,Google一向是最激进的。纵观Google目前的产品线,社交的Google Plus,网站分析的Google Analytics,Google目前赖以生存的Google Adwords等,如果想下载源码,用ElementTree来解析网页,那什么都得不到,因为Google的数据都是通过Ajax调用经过数据混淆处理的数据,然后用JavaScript进行解析渲染到页面上的。
• 垂直搜索新问题
当大家都在关注搜索的速度的时候,往往伴随业务的快速发展,数据服务质量成为了实时搜索或者垂直搜索中的新问题。实时搜索和垂直搜索是不一样的问题,下面的问题就是垂直场景下得实时搜索问题。也可以理解垂直搜索都不实时,其他的实时先排队吧。问题比较抽象,只谈总体上的现象,对于具体如何解绝问题的细节,不做说明。有些不具有通用性,有些和场景相关,很难有最佳方式,不代表没有解决方法。首先是有问题意识,然后自然有解决方法。 问题: (1)个性化排序 伴随业务发展需要,同时细分用户群体,为了最大程度优化服务质量、满足更大群体的具体业务场景,个性化的排序越来越引起高度重视。传统的文本相关性只是第一维的参考,针对业务多维度综合得分的二维排序最终影响排序。而一个平台上面临的服务群体、服务场景多种多样,有行业属性、地域属性、技术属性、运营属性等,很难完全统一,完全归一化到一个计算公式中去。
最早是10年听baidu的一位老师讲信息检索课程,那一次对离散数学中的“二部图”的使用场景,有了一个真真切切的认识。然后这个概念一直伴随着自己,到现在,并且在不同场所的听课中,去询问个一些讲师,貌似都很“吃惊”“不清楚”“没有做过”。我才知道这就是技术的差距。 应用中,二部图就是语义推荐使用,系统是搜索引擎,数据是二部图结构,参数是“全部海归的7-8个博士、顶级专业人才”。。。。然后带着当时的疑惑,来到这里,四处打听相关技术,然后慢慢理解了,“曾经这是一家运营公司”“曾经这是一家数据库公司” “曾经这家公司都不怎么用技术的”。。。。 自语语言学+领域学知识+社会学知识构成了“有效推荐”的三大基石。 自语语言初级:分词、词性标注 中级:本体、语料 高级:领域、主体的关联和聚合 领域学:领域热点、核心、焦点价值、商业模式 社会学:用户行为、思考、互动等。

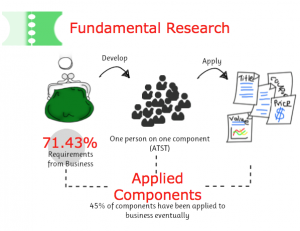
对于一个长期在研发领域的人来说,经常需要思考研发的意义、工程与研究的关系、产品型的公司应当做何种程度的研究等问题。理想情况下,我们期望每一项研发工作都能得到组织、同事以及社区的高度认可。因此不管你处于工程领域还是研究领域,工程与研究的关系会让你不断思考甚至困扰。最近看到的Google’s hybrid Approach to research (English 中文) 一文或许会让你豁然开朗。 研究领域的现状 根据技术领域的差异,大部分产品开发可以依赖已有成熟的工程技术完成,进一步通过研究来提升产品能力的空间并不大(比如提升空间在10%以下)。互联网企业偏重产品开发能力,关注点主要在开发效率、研发流程等交付能力上。偏实用主义驱动方式,很难对相关领域的工程技术进行升华。因此研究的驱动力、研究的空间及取得成果的可能性较低。
题目虽然看起来比较晦涩,而且有堆砌关键词的嫌疑,但是我相信还是比较贴切的。相信现在业界都还是认为白盒测试是比较高级的一种测试,因为他会涉及到开发的具体逻辑,需要测试人员有读代码的能力。我也部分同意这种看法,但是我认为,黑盒测试在某种意义上,尤其是自动化测试上,是非常具有意义的。为什么这么说?我们来讲一个案例。一个电子商务的网站的同事向我描述了他目前的测试任务,问我如何快速的,健康的测试。




最近做了一系列的单元测试相关的工作,除了各种规范及测试框架以外,讨论比较多的就是关于代码覆盖率的产生,c/c++与其他的一些高级语言或者脚本语言相比较而言,例如 Java、.Net和php/python/perl/shell等,由于没有这些高级语言和脚本语言的反射的特性,其代码覆盖率的产生过程会稍微复杂一些。发现许多同学对C++的覆盖率如何产生在都不太清楚,这里做一个简单的介绍。
前两天在一淘数据测试中启动了一个测试人员成长项目,叫做测试技术革新,其实就是一个系列培训计划。主要目的是为了帮助我们的测试人员成长,让他们可以更加胜任未来的自动化测试需要。在为测试技术革新项目挑选合适的主题的时候,我想到了测试驱动的开发过程。原因是这个过程既让测试人员可以了解一种好的开发过程,而又和测试本职工作相关,而且也比较容易理解。所以下面就是我对于测试驱动开发的一个过程介绍。什么是测试驱动开发?测试驱动开发(test driven development (TDD))是一个测试结果导向,可迭代的开发过程。我们直接从一个实例开始对测试驱动开发的讲解。假设,你被要求开发一个函数,lz_array_merge($new, $old),这个函数的目的是将$new数组里面的每一个内容,都覆盖给$old数组。第一个版本不考虑迭代,但是不排除迭代的可能性。
Pipes是hadoop提供的c++接口,但是在官网上找不到pipes的文档,只能从例子开始一点点摸索。实验环境是debian 6 amd64,hadoop 1.0.3。hadoop的安装目录是$HOME/hadoop,安装和配置过程在上一篇安装笔记中有提到。
记录一下hadoop集群的搭建过程,一共3台机器,操作系统都是debian 6,hadoop版本是1.0.3,jre是源里的openjdk-6。hadoop官网的说明挺详细,就是不能快速搭建出一个能跑的环境。在网上找到一篇文章(见参考资料[1]),虽然文章中用的是0.20版本,但是在1.0.3上也适用。这里使用master,slave1和slave2分别作为三台机器的主机名。为了操作方便,每台机器上都有一个用户hadoop,密码都一样。以下的配置操作都在master上进行。




之前在朋友的介绍下,我开始尝试使用酷盘这个网络同步,感觉非常的好,不管是从UI还是从功能,都非常符合我的需求。 但是今天我意外的发现了一个问题,让我决定撤离国内云存储,亦或是自建云同步。 是这样的...
我一直使用 MogileFS 存视频这样的大文件来做源站.也用来存海量的小文件. MogileFS 本身对大文件支持也是相当不错的,另外要知道大文件它查询数据库的次数就更加少. 在这需要提醒一下大家.需要注意在大文件上传的时候(平时我多大的都有大点的 4G 以上), 需要 MogileFS::Client 加上特别的参数,来分片上传,这样存放速度在 MogileFS 中就会快多了. 我们在使用 new_file 的方法来上传的时候,只需要加入可选参数中的 largefile => 1 .这个时候内部的 MogileFS::Client 中就会使用另一个上传的模块,不在使用默认的 MogileFS::NewHTTPFile.但功能基本一样,只是支持 chunked 和 partial (Content-Range) HTTP/1.1 PUT .




在绘制业务流程图前,思考如何精美,如何交互,使用什么工具,都不应该是重点。 真正重点的是将业务流程图的关键要素给搜集一番。请试图回答清楚以下几个问题,否则不要开始绘制流程图:整个流程的起始点是什么?整个流程的终结点是什么?在整个流程中,涉及到的角色都是谁?在整个流程中,都需要做什么事情?(可是是一个会议,可以是一个任务) 这些会议和任务是可选还是必选的?分别产出什么文档?这有点像一个头脑风暴,能够帮助你将所需用到的原材料获取到,有了这些“米”和“水”,那就不愁去如何烹饪了。
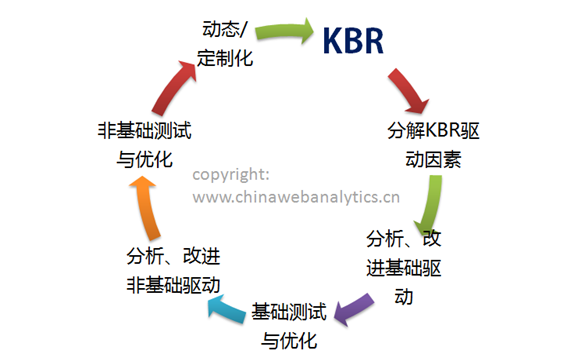
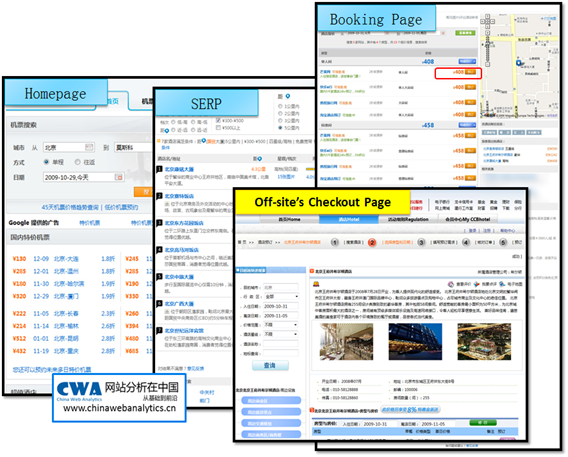
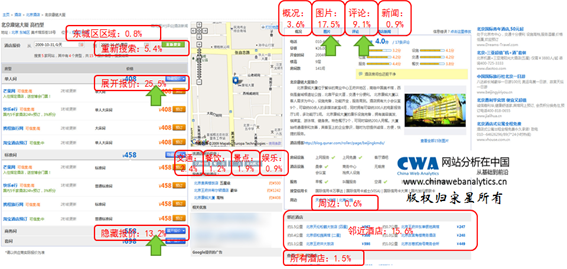
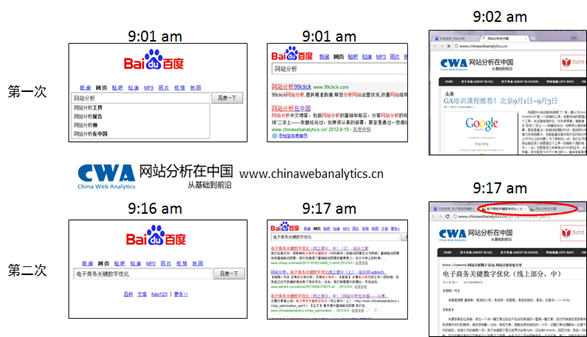
还记得我们前文谈到的优化路径吗?在这个路径中,我们强调从定义KBR开始,然后分解影响KBR绩效的驱动因素,然后再确定这些驱动因素中哪些是基础驱动因素,哪些是非基础驱动因素,再尝试分析基础驱动因素并着手改进,同样,尝试分析非基础驱动因素并着手改进,这之后测试你的这些改进是否有效并固定有效的改进(优化)。由于优化不可能是针对所有人群和兴趣的,所以最后你要在优化的基础上进行动态处理(定制化)。
老婆单位有时候有一些很大的 Excel 统计报表需要处理,其中最恶心的是跨表的 JOIN 查询。他们通常采取的做法是,把多个 Excel 工作簿合成一个工作簿的多个表格,然后再跑函数(VLOOKUP之类)去查。因为用的函数效率很低,在 CPU 打满的情况下还要跑几个小时。 然后我就看不过去了,我也不懂 Excel,不知道如何优化,但我想用 Python+SQLite 总归是能够实现的。于是就尝试了一把,效果还不错,一分钟以内完成统计很轻松,其中大部分时间主要花在读 Excel 内容上。



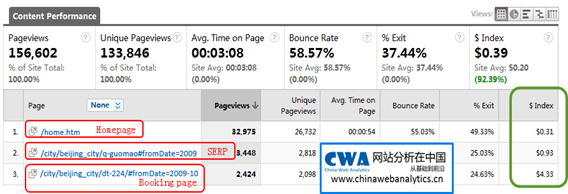
Visit这个度量是网站分析的基石。但即使是这样基本的一个度量,Google Analytics对它的定义其实都不是完全一成不变的。为了适应新的浏览器变化和人们访问网站习惯的变化,Google Analytics在基本度量上甚至都在不断进化。哦,这或许也是Google Analytics的可怕之处,她已经达到了这样的高度,还比别人爬的快。在本文中,你将学到什么: GA定义visit的重大改变;特殊情况下GA如何处理visit的定义; Visit关联属性的变化(过去和现在);为什么大部分页面的visit会远小于这些页面的访问者(visitor)数量。




“好奇号”火星车上的软件究竟是个什么样的构造?我们已经知道,好奇号上的软件大部分都是用C语言写成的,这些代码加起来大概有250万行。
Windows下用stat函数得到的文件size可能不准,获取文件大小之前最好先读一下这个文件。
我最近开发了我的第一个网页游戏:一个HTML5的视频智力游戏。开发的过程很有趣,我喜欢编程,但当实现了游戏逻辑后,我有了一个有趣的想法:为什么不想个办法把代码隐藏起来?
原本打算收集一些 WordPress 奇技淫巧,不过精力有限维护不过来,予以关站处理。这里就将之前的文章综合整理下,供各位博友尽情收藏。
近3天十大热文
-
 [136] Go Reflect 性能
[136] Go Reflect 性能 -
[19] [译]Google Chrome中的高性能网
-
[17] 在FreeNAS/BSD搭建基于Nginx+
-
[16] 关于Linux的文件系统cache
-
[14] 最近总结的一些技巧(vim,python,s
-
[14] Linux常用系统信息查看命令
-
[12] PHP加速器 eaccelerator 缓存
-
[11] 精于图片处理的10款jQuery插件
-
[11] 什么是DNS劫持和DNS污染?
-
[10] base64_encode 和 urlenc
赞助商广告
