使用python/casperjs编写终极爬虫-客户端App的抓取
1.缘起
随着移动互联网的发展,现在写web和我三年前刚开始写爬虫的时候已经改变了太多。特别是在node以及javascript/ruby社区的努力下,以往“服务器端”做的事情都慢慢搬到了“浏览器”来实现,最极端的例子可能是meteor了 ,写web程序无需划分前端后端的时代已经到来了。。。
在这一方面,Google一向是最激进的。纵观Google目前的产品线,社交的Google Plus,网站分析的Google Analytics,Google目前赖以生存的Google Adwords等,如果想下载源码,用ElementTree来解析网页,那什么都得不到,因为Google的数据都是通过Ajax调用经过数据混淆处理的数据,然后用JavaScript进行解析渲染到页面上的。
本来这种事情也不算太多,忍一忍就行了,不过最近因业务需要,经常需要上Google的Keyword Tools来分析特定关键字的搜索量
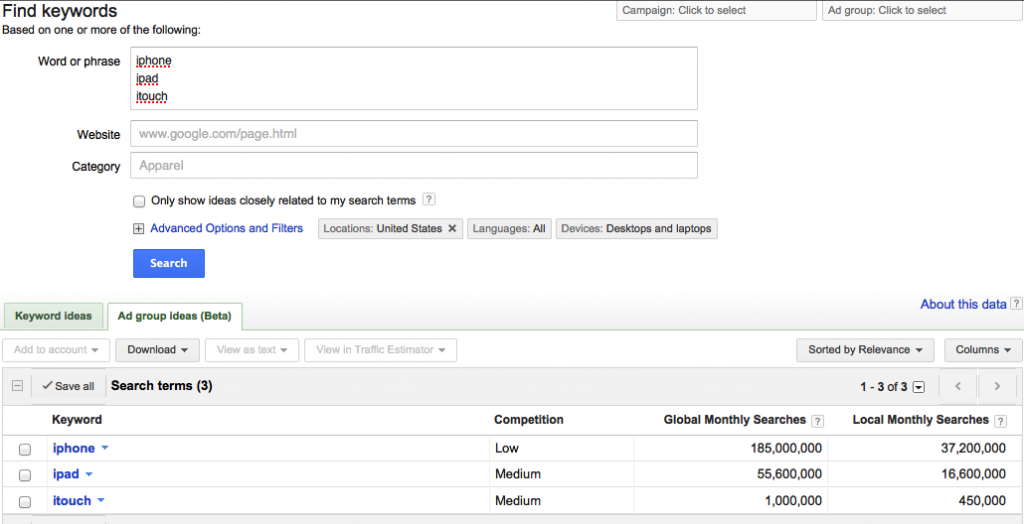
图为关键字搜索的截图

图为Google经过混淆处理的Ajax返回结果。
要把这么费劲的事情自动化倒也不难,因为Google也提供了API来做,Adwords项目的TargetingIdeaService就是来做这个的,问题是Google的API调用需要花钱,而如果能用爬虫技术来爬取这个结果,就能省去不必要的额外开销。
2. Selenium WebDriver
由于要解析执行复杂的JavaScript,必须有一个Full Stack的浏览器JavaScript环境,这种环境三年前的话,可能只能诉诸于于selenium,selenium是一款多语言的浏览器Driver,它最大的优点在于,提供了从命令行统一操控多种不同浏览器的方法,这极大地方便了web产品的兼容性自动化测试。
2.1 在没有图形界面的服务器上安装和使用Selenium
安装selenium非常简单,pip install selenium 即可,但是要让firefox/chrome工作,没有图形界面的话,还是要费一番功夫的。
推荐的做法是
apt-get install xvfb Xvfb :99 -ac -screen 0 1024x768x8& export DISPLAY=:99 |
Selenium的安装和配置在此就不多说了,值得注意的是,如果是Ubuntu用户,并且要使用Chrome的话,必须额外下载一个chromedriver,并且把安装的chromium-browser链接到/usr/bin/google-chrome,否则将无法运行。
2.2 爬取Keywords
先总结一下Adwords的使用方法吧,要能正常使用Adwords,必须要有一个开通Adwords的Google Account,这倒不是很难,只要访问 http://adwords.google.com ,Google会协助创建账号,如果还没有的话,其次就是登陆了。
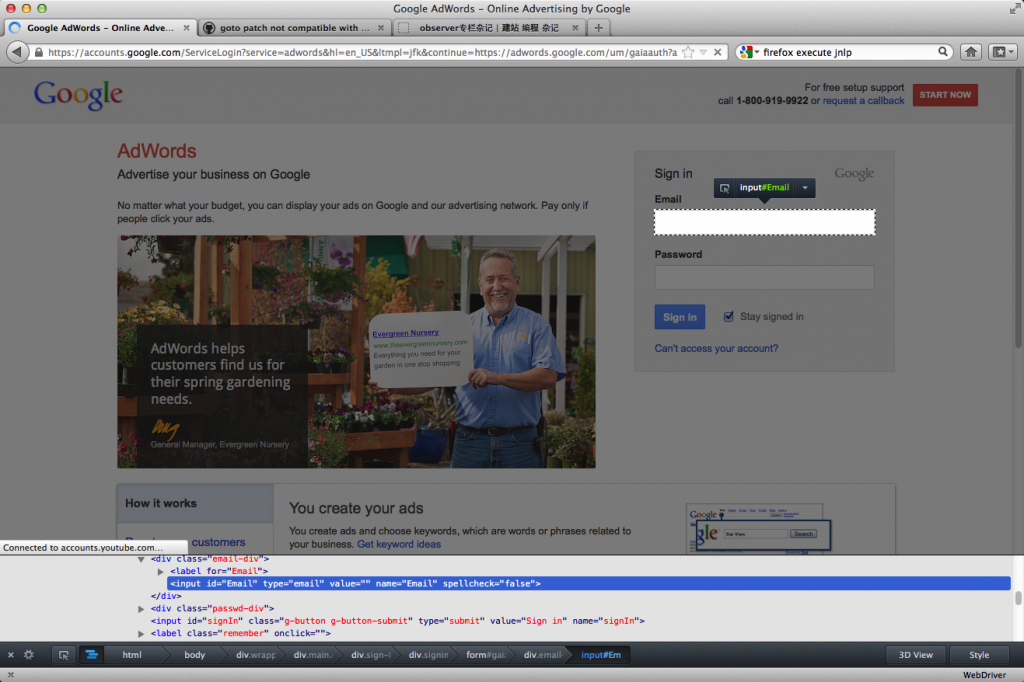
通过分析登陆页面,我们可以看到需要在id为Email的一个input框内输入email,然后在id为Passwd的密码框内输入密码,然后点击Sign in提交这个页面内唯一的form。
首先别忘了开一个浏览器先
from selenium import webdriver driver = webdriver.Firefox() |
driver.find_element_by_id("Email").send_keys(email)
driver.find_element_by_id("Passwd").send_keys(passwd)
driver.find_element_by_id('signIn').submit() |
登陆后,我们发现需要访问一个类似 https://adwords.google.com/o/Targeting/Explorer 的网页才能跳转到关键字工具,于是我们手动生成一下这个网页
search = re.compile(r'(\?[^#]*)#').search(driver.current_url).group(1) kwurl='https://adwords.google.com/o/Targeting/Explorer'+search+'&__o=cues&ideaRequestType=KEYWORD_IDEAS' |
到了工具主页以后,事情就变得Tricky起来了。因为整个关键字工具都是个客户端App,在全部文件载入完成以后,页面不会直接渲染完毕,而是要经过复杂的JavaScript运算后页面才会完整显示。然而Selenium WebDriver并不知道这一点,所以我们要让他知道。
在这里,我们要等待Search按钮在浏览器中出现以后,才能确认网页加载完毕,Selenium WebDriver有两种方式可以实现这一点,我偷懒用了全局的默认等待机制:
driver.implicitly_wait(30) |
于是Selenium就会在找不到页面元素的时候自动等候不超过30秒
接下来,等待输入框和Search按钮出现后提交搜索iphone关键字的请求
driver.find_element_by_class_name("sEAB").send_keys("iphone")
find_element_by_css_selector("button.gwt-Button").click() |
然后我们继续等待class为sLNB的table的出现,并解析结果
result = {}
texts = driver.find_elements_by_xpath('//table[@class="sLNB"]')\
[0].text.split()
for i in range(1, len(texts)/4):
result[ texts[i*4] ] = (texts[i*4+2], texts[i*4+3]) |
这里我们使用了xpath来提取网页特征,这也算是写爬虫的必备吧。
完整的例子见: https://gist.github.com/3798896 替换email和passwd后直接就能用了
3. JavaScript Headless解决方案
随着Node以及随之而来的JavaScript社区的进化,如今的我们就幸福多了。远的我们有phantomjs, 一个Headless的WebKit Driver,意味着可以无需GUI,完全模拟Chrome/Safari的操作。 近的有casperjs(基于phantomjs的好用封装),zombie(相比phantomjs的优势是可以和node集成)等。
其中非常可惜地是,zombiejs似乎对富JavaScript网站支持得有问题,所以后来我还是只能用casperjs来进行测试。Headless的方案因为不需要渲染GUI,执行速度约为Selenium方案的三倍。
另外由于这是纯JavaScript的方案,于是我们可以直接在例如Chrome的Console模式下写代码控制浏览器,不存在如Selenium那样还需要语义转换,非常简洁直观。例如利用W3C Selectors API Level 1所提供的querySelector来快速选取元素,对表单进行submit,对按钮进行click,甚至可以执行自定义JavaScript脚本以便按一定规律对页面进行操控。
但是casperjs或者说phantomjs的弱点是不支持除了文件读写和浏览器操作以外的一切*nix IPC惯用伎俩,socket神马的统统不支持,1.4版本以后才加入了一个webserver用于和外界通信,但是用httpserver来和外界通信?我有点抵触就是了。
废话不说了,casperjs的代码看起来就是这样,登陆:
var casper = require('casper').create({verbose:true,logLevel:"debug"});
casper.start('http://adwords.google.com');
casper.thenEvaluate(function login(email, passwd) {
document.querySelector('#Email').setAttribute('value', email);
document.querySelector('#Passwd').setAttribute('value', passwd);
document.querySelector('form').submit();
}, {email:email, passwd:passwd});
casper.waitForSelector(".aw-cues-item", function() {
kwurl = this.evaluate(function(){
var search = document.location.search;
return 'https://adwords.google.com/o/Targeting/Explorer'+search+'&__o=cues&ideaRequestType=KEYWORD_IDEAS';
})
}); |
与Selenium类似,因为页面都是Ajax调用的,我们需要明确地“等待某个元素出现”,即:waitForSelector,casperjs的文档既简洁又漂亮,不妨多逛逛。
值得一提的是,casperjs一定要调用casper.run方法,之前的start, then等方法,只是把步骤封装到了this._steps里面,只有在run的时候才会真正执行,所以casperjs设计流程的时候会很痛苦,for/each之类的手法有时并不好用。
这个时候需要用JavaScript编程比较常用的递归化的方法,参见https://github.com/n1k0/casperjs/blob/master/samples/dynamic.js 这个例子。我在完整的casperjs代码里面也是这么做的。
具体逻辑的实现和selenium类似,我就不废话了,完整的例子参见: https://gist.github.com/3798922
4. 综上
介绍了selenium和casperjs两种不同的终极爬虫写法,但是其实这篇文写来只是太久没更新了,写点东西更新一下而已:)
建议继续学习:
- 使用python爬虫抓站的一些技巧总结:进阶篇 (阅读:12753)
- 使用python/casperjs编写终极爬虫-客户端App的抓取 (阅读:10352)
- 使用python爬虫抓站的一些技巧总结:进阶篇 (阅读:7162)
- 简析搜索引擎中网络爬虫的搜索策略 (阅读:6805)
- 聚焦爬虫:定向抓取系统的实现方法 (阅读:5492)
- 定向抓取漫谈 (阅读:5068)
- 互联网网站的反爬虫策略浅析 (阅读:4720)
- 对爬虫的限制 (阅读:2550)
- Google 网页爬虫报告无法连接站点解决办法 (阅读:1821)
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:observer 来源: observer专栏杂记
- 标签: casperjs 爬虫
- 发布时间:2012-09-30 15:11:50

-
 [930] WordPress插件开发 -- 在插件使用
[930] WordPress插件开发 -- 在插件使用 -
[130] 解决 nginx 反向代理网页首尾出现神秘字
-
[51] 如何保证一个程序在单台服务器上只有唯一实例(
-
[51] 海量小文件存储
-
[50] 整理了一份招PHP高级工程师的面试题
-
[49] CloudSMS:免费匿名的云短信
-
[48] 全站换域名时利用nginx和javascri
-
[48] 用 Jquery 模拟 select
-
[47] Innodb分表太多或者表分区太多,会导致内
-
[46] ps 命令常见用法
