从淘汰Oracle数据库的事情说起
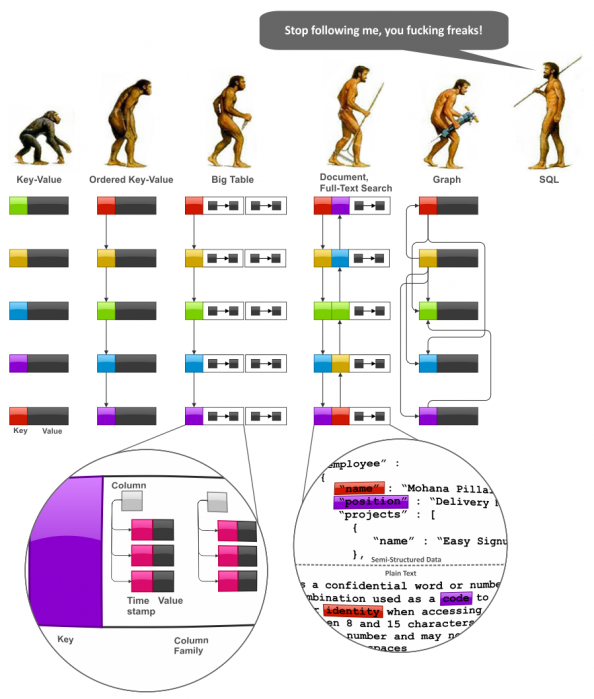
作者从公司淘汰Oracle数据库的内部实践说起,类比国内“去IOE”浪潮,点明核心动因是高昂的维护成本与扩展性瓶颈。但他指出,这绝非简单地将Oracle换为MySQL或上云,而是一场有计划的架构演进——部分业务数据已迁移至DynamoDB等NoSQL,甚至落盘至S3,计算层则由Hadoop或Spark接管。 由此引出一个关键问题:NoSQL的兴起是否意味着SQL将过时?作者的回答是“恰恰相反”。他通过两个实例佐证:一是团队将复杂的Scala逻辑重写为Spark SQL,让更熟悉SQL的数据分析师能直接参与;二是基础设施团队通过Hive等工具,在底层从数据库切换至MapReduce后,依然对上层提供稳定的SQL接口。SQL作为一种数据抽象和思维范式,其生命力反而在增强。 文章还反思了关系型数据库自身“被成功到滥用”的问题,例如在不适宜的高并发场景硬用Oracle。最后,作者将话题从技术延伸到人与技能,指出诸如DBA等纯粹依赖维护的岗位将面临挑战,而真正的核心技术价值在于解决那些不易被工具或新平台简单替代的根本问题。整篇文章从一次具体的架构迁移,引发了对技术演进逻辑和工程师核心能力的深层思考。