您现在的位置:首页 --> 查看专题: 编码

在日常的前端开发工作中,我们会经常的与HTML、javascript、css等语言打交道,和一门真正的语言一样,计算机语言也有它的字母表、语法、词法、编码方式等,在这里我简单的谈一下前端HTML与javascript日常工作中常碰到的编码问题。在计算机中,我们储存的信息都是用二进制码表示的。我们认识的、屏幕上显示的英文、汉字等符号和储存用的二进制代码的互相转换,就是编码。
String line=value.toString();之所以会把GBK编码的输入变成乱码,很关键的一个因素是Text这个Writable类型造成的。初学时,一直认为和LongWritable对long的封装一样,Text类型是String的Writable封装。但其实Text和String还是有些区别,它是一种UTF-8格式的Writable,而Java中的String是Unicode字符。所以直接使用value.toString()方法,会默认其中的字符都是UTF-8编码过的,因而原本GBK编码的数据使用Text读入后直接使用...
最近在MacOS下用django框架做web开发,于是用MacPorts安装了MySQL5。但是测试时django的测试框架会报错,原因是UTF8数据无法插入。我们知道,MySQL安装完成后默认编码为latin1,并不适合中文应用。因此我们通常用下面的SQL语句创建数据库: CREATE DATABASE mydb DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci; 而django测试框架创建测试数据库时并不会像这样指定编码,因此创建的数据库编码为latin1,导致加载UTF8数据...
所谓BOM,全称是Byte Order Mark,它是一个Unicode字符,通常出现在文本的开头,用来标识字节序(Big/Little Endian),除此以外还可以标识编码(UTF-8/16/32),如果出现在文本中间,则解释为zero width no-break space。 注:Unicode相关知识的详细介绍请参考UTF-8, UTF-16, UTF-32 & BOM。 对于UTF-8/16/32而言,它们名字中的8/16/32指的是编码单位是多少位的,也就是说,它们的编码单位分别是8/16/32位,换算成字节就是1/2...
今天在做一个系统GBK转UTF8的编码转换,竟然发现这个系统的sql文件里的汉字都被处理成了16进制编码了。而GBK,和UTF8的16进制编码不一致,导致根本无法在utf8下正常导入数据库。
如果内容中不带汉字,那不管是什么编码都无所谓,如果内容中带汉字,需要先检测字符编码,可使用mb_detect_encoding....
环境:Linux Dist: CentOS 4.3,locale: en_US.UTF-8, .vimrc: set fencs=gbk 目标:终端使用 less/more/grep 等命令正确显示 GBK 编码文件内容,vim 正确显示 GBK 编码文件汉字 症状: 1. 系统自带 gnome-terminal 在设置终端编码为 GBK 后,能达到目标。 2. 使用 xshell 在 windows 平台上设置终端编码为 default 时,ssh 登录到 CentOS,能达到目标。 3. 在 screen 命令窗口内,无论终端还是 vim, 中文均显示为乱码,无法达到...
vim 用 termencoding 选项控制输出时的编码,这个选项默认为空,也就是不进行转换,这导致我在 GB 编码的终端下打开 UTF-8 文件,虽然能识别出来,显示却是乱码。设置终端编码当然可以,不过还是要相应设置 locale,比较麻烦。通常终端编码和 LOCALE 的设置一致,因此可以借用一下这个设置:let &termencoding = substitute($LC_ALL, "[a-zA-Z_-]*\\.", "", "")把 termencoding 设置为 locale 的值点后面的部分,比如 LC_ALL 为 zh...
公司PHP人员水平参差不齐,而且写代码的习惯不一样,导致项目维护的成本增加程序员与程序员之间的交流主要是靠代码,因此编码规范显得尤为重要,下面的PPT是我做培训用的,希望对大家有...
最近在使用django的过程中,发现之前对中文编码的理解并不怎么正确,在此记录一下。 1.在所有需要显式使用中文的地方加上#-*- coding: UTF-8 -*-标识,(包括注释中的中文和代码中字符串的中文...


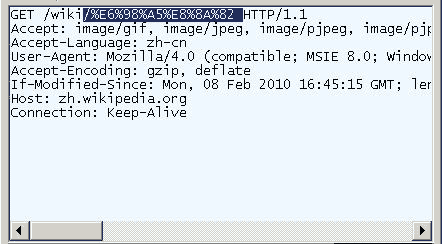

一、问题的由来URL就是网址,只要上网,就一定会用到。一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字符号。因为网络标准RFC 1738做了硬性规定:"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*\'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."“只有字母和数字[0-9a-zA-Z]、一些特...
如果你需要在Linux中操作windows下的文件,那么你可能会经常遇到文件编码转换的问题。Windows中默认的文件格式是GBK(gb2312),而Linux一般都是UTF-8。下面介绍一下,在Linux中如何查看文件的编码及如何进行对文件进行编码转换。查看文件编码在Linux中查看文件编码可以通过以下几种方式:1.在Vim中可以直接查看文件编码:set fileencoding即可显示文件编码格式。如果你只是想查看其它编码格式的文件或者想解决用Vim查看文件乱码的问...
一、利用iconv函数族进行编码转换在LINUX上进行编码转换时,既可以利用iconv函数族编程实现,也可以利用iconv命令来实现,只不过后者是针对文件的,即将指定文件从一种编码转换为另一种编码。iconv函数族的头文件是iconv.h,使用前需包含之。#include iconv函数族有三个函数,原型如下:(1) iconv_t iconv_open(const char *tocode, const char *fromcode);此函数说明将要进行哪两种编码的转换,tocode是目标编码,fromcod...
base64编码是网络传输的比较被青睐的一种编码,因为base64编码的字符集也是基本的asscii字符,所以经常会被当做安全的编码放在url里面传输,当做urlencode编码使用了,其实我们应该明白一下两点:1. base64编码里面有一个 “+” 号,在urlecode编码中 “+” 会被解码成空格,urlencode时,"+" 号肯定是由空格编码出来的,但是base64编码的结果中 "+" 不是空格编码出来的,如果将base64...
多次遇到IE调用js文件的时候两者编码不统一而出现问题了,今天又载在这个上面了,有点不爽。今天我做的网页的编码是gb2312的,而js文件的代码是utf-8的,程序写完了之后在Firefox下面和chrome下面调试都是正常的,而唯独ie下面显示“缺少对象”,调了一个下午都没搞明白,最后我就不调了,然后到处翻网页看,忽然我就想起来是编码的问题,因为遇到的次数也不少了,但是却很难想到。解决的办法是同一js文件的编码为gb2312就可以了...
字符编码问题, 对于一个在伟大天朝的程序员来说, 几乎不可能遇不到, 从我刚开始接触Coding到现在, 乱码, 编码转换问题就好像一直没有停息过. 从最初的数据库到客户端乱码,到后来不同浏览器Url编码习惯不同,再到服务器和脚本编码不同的问题等等. 朋友一直希望我能写一篇关于编码的文章, 但无奈面太广, 设计到的问题多, 所以也一直写不出来. 不过, 作为基础, 大家先看看这篇文章吧:《字符编码详解》...
本来是我另一个文章内的内容,但收集久了,这个也很长了,所以挖出来单独做成一个文件….都是有关编码操作的,时不时要用到,收集全了,就不到处乱找…有没有朋友也有好的方法,可以介绍...
[ 共37篇文章 ][ 第2页/共2页 ][ 1 ][ 2 ]
近3天十大热文
-
 [318] Go Reflect 性能
[318] Go Reflect 性能 -
[14] [译]Google Chrome中的高性能网
-
[10] Mac下.apk的反编译
-
[10] 精于图片处理的10款jQuery插件
-
[10] webapp网页调试工具Chrome Dev
-
[9] 程序中的“多线程”
-
[9] jQuery性能优化指南
-
[9] 在FreeNAS/BSD搭建基于Nginx+
-
[9] rsync同步的艺术
-
[8] Linux常用系统信息查看命令
赞助商广告
