pre: 感谢 九任 对我的支持~
情况回放:
上周预发机器出了一个问题,CPU不定时会近100%满负载运行。重启以后就会恢复,之后又会到达100%,而且不会自恢复。
首先想到的是程序出现了死循环,于是用jstack把栈打印出来,发现业务线程都停在了regex相关的代码上,有死循环的样子。
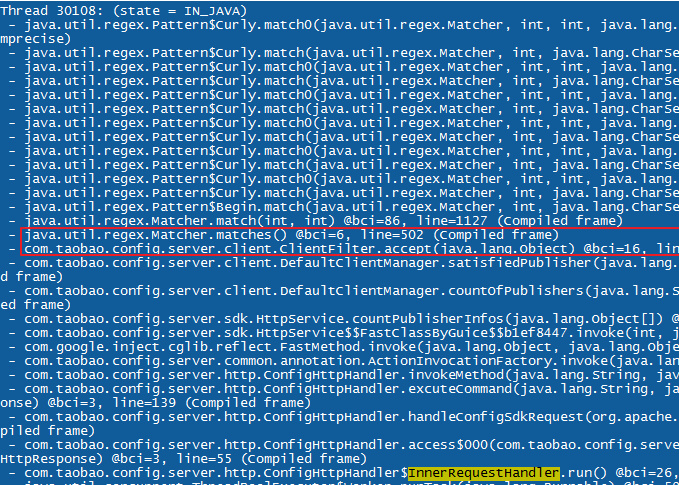
查看栈,发现一切都是由ClientFilter这个类开始,其使用了matcher.matches()方法。这样一来,就很可能是由于输入了不规范的正则导致的了。于是查看输入日志,发现这么一个输入:
![]()
也就是说输入的正则表达式为:******Deliver …,我们的代码会将这种代码规范成:.*.*.*.*.*.*.*Deliver。在java试了一下,试着匹配
“sssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssss”,果然会假死。
那么问题是:为什么输入这种正则会导致假死?
这里的原因是:java使用的是greedy模式来匹配 .*。为了让分析简单,我们将输入改成:.*.*.*.*D,正则需要匹配的字符串为:abcdefghijklmnopqrstuvwxyz0123456789,共36个字符。首先,我们将正则转换成 ”有限自动机(Finite-State Machine)“
那么greedy模式(可参看:java.util.regex.Pattern.Curly.match0(…),另两个是possessive与lazy,分别对应 + 与 ?)的意思就是:最大可能的匹配当前状态(优先匹配粗的路径),当不能匹配时再回溯配置下一个(虚线所示),直到,回溯到cmin个匹配(对于 .* 这个cmin为0)。比如说
.*D,如果想匹配 testDdev,那么Java首先将 .* 转成 .{0, MAX}(这里的MAX应该是2亿多,具体可以看代码),那么 .{0, MAX} 得到的匹配是(java会自动在string后加上一个终止字符,这个字符只能java.util.regex.Pattern.LastNode匹配):
testDev$
RED: 已匹配的部分
当到最后时,java会调用 next.match(matcher, i, seq)
testDev$
RED: 已匹配的部分
BLUE:回溯部分
显然这里 D 不匹配,所以又需要回溯
testDev$
RED: 已匹配的部分
BLUE:回溯部分
显然这里 e 也不匹配,所以还需要回溯,直到回溯到 D,才会正式进入到下一个状态:
testDev$
RED: {0 MAX} 配置的部分
BLUE:回溯部分
GREEN: D 配置的部分
testDdev
RED: 已匹配的部分
如下面的代码所示(java.util.regex.Pattern.Curly.match0(…)):

看了上面的示例我想大家应该有点头绪了。现在我们回到 .*.*.*.*D 这里,其在java内经过Pattern.compile之后是这个样子:
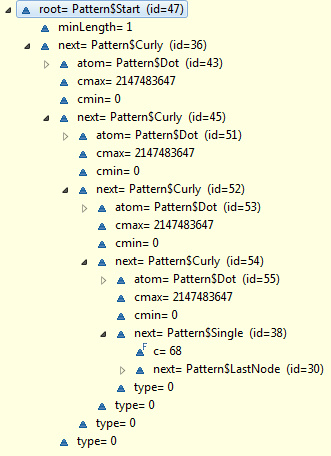
type=0,表示使用的就是greedy方式。那么这里面有4个curly,我们用C1-4代表之。首先是C1满匹配:
abcdefghijklmnopqrstuvwxyz0123456789$
我们省略前面几步,看看回溯到5字符有什么特别
abcdefghijklmnopqrstuvwxyz0123456789$
这时候,C1释放出了5个字符,那么这里就相当于 用 .*.*.*D 去配置6789$,那么老样子C2会首先满匹配
abcdefghijklmnopqrstuvwxyz0123456789$
然后next.match(matcher, i, seq),不匹配,再next.match(matcher, i, seq),‘D’也不匹配。只能回溯,我们看看回溯4个字符是什么样子
abcdefghijklmnopqrstuvwxyz0123456789$
这时就相当于用 .*.*D 去匹配 789$ 了,又满匹配,next又不匹配,再回溯,如下:
abcdefghijklmnopqrstuvwxyz0123456789$
就成了用 .*.*D 去match 89$,当 C2-4 都失败后,C1才会再退一个字符,再进行递归:
abcdefghijklmnopqrstuvwxyz0123456789$
我们到底需要多少步才能将这些数字match完?
可想而知,这里的数目有多么大。那么问题来了,我们到底需要多少步才能将这些数字match完?OK,要解决这个问题,关键是要弄清这个递归。
设字符长度为n(加上终止符),正则长度为 m(这里是有效节点,如 .* 是一个节点)。从上面的例子,我们能总结出递归的步骤为:
1、若m=1,返回 1;若m>1,步数 + n
2、回溯 i=1到n-1个字符,对于每个i 取 m=m-1, n=n-i 回1,并把所有的结果求合;
总的来说,用数学公式表示的话,就是这个样子:
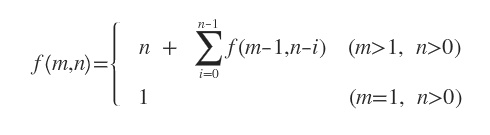
这里我写了个简单的实现:
(注:这里的 depth 并不是递归深度,而是递归次数,当时搞错了)
package com.alibaba.taobao.tinyprofiler;
import java.lang.instrument.ClassFileTransformer;
import java.lang.instrument.IllegalClassFormatException;
import java.security.ProtectionDomain;
import org.objectweb.asm.ClassAdapter;
import org.objectweb.asm.ClassReader;
import org.objectweb.asm.ClassWriter;
public class MethodCallCountTransformer implements ClassFileTransformer {
@Override
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined,
ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {
try {
if (!“java/util/regex/Pattern$CharProperty”.equals(className)
&& !“java/util/regex/Pattern$BmpCharProperty”.equals(className)) {
return classfileBuffer;
}
ClassWriter writer = new ClassWriter(ClassWriter.COMPUTE_MAXS);
ClassAdapter adapter = new MethodCallClassAdapter(writer, className);
ClassReader reader = new ClassReader(classfileBuffer);
reader.accept(adapter, 0);
// 生成新类字节码
return writer.toByteArray();
} catch (Exception e) {
e.printStackTrace();
// 返回旧类字节码
return classfileBuffer;
}
}
}
package com.alibaba.taobao.tinyprofiler;
import java.util.concurrent.atomic.AtomicInteger;
public class Counter {
private static AtomicInteger methodCallCount = new AtomicInteger(0);
public static void printAndIncCount(String className, String methodName) {
System.out.println(className + “.” + methodName + “ called, total times ” + methodCallCount.incrementAndGet());
}
}
OK,现在我们输入:
String regex = “.*.*.*D”;
String target = “22asdvasdx”;
Pattern.compile(regex).matcher(target).matches();
System.out.println(“Xuanyin’s estimated count: ” + findTotalWays(4, target.length()) + “; depth: ” + recursionDepth);
输出结果(注:这里的 depth 并不是递归深度,而是递归次数,当时搞错了):
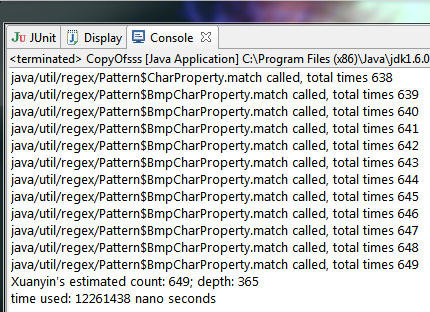
肿么样,分毫不差~OK,那么我们现在回到最开始的问题,输入 .*.*.*.*.*.*D 去匹配 com.taobao.binary.bogda.query.service.RulesInfoQueryService:1.0.0.daily
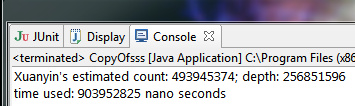
结果显示需要 5 亿 匹配, 还要进出栈近 2.5 亿次哦
这里我的机器是i7-2600K 超4.5G,结果显示需要5秒,这还是不是最差的情况哦~
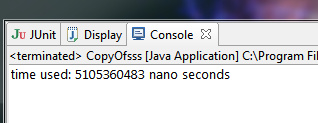
而每次用户查询要匹配近600个这样的字符串,~你说匹配得完嘛。