这篇文章是我和洪飞飞同学共同翻译的。这篇带有一点点技术的文章,帮我解决了一个很大的问题,就是我知道流量是从Google来的,但是具体是从Google的什么搜索类别来的?并且Google的Sitelinks这样的特殊链接,我怎样才能辨别它们分别贡献了多少流量给我?还有一个很大的用途——GA现在对于Google的Organic关键词几乎都已经隐藏了,我怎样才能知道这些not provided的关键词是什么?这篇来自提姆.雷斯尼克的文章给我们提供了一个新的方法——分析Google的跳转URL中的尾参字符串。
所以,我相信这个文章能够给朋友们很多知识和启发。
正文如下:
上周我举办了一个名为Mozinar的活动,在这个活动中提出了一种从Google的流量来源字符串(referral string)中抽取SERP(搜索引擎结果页)的垂直信息的方法,这些垂直信息被Google称为Universal Search(即通用搜索)。自从Mozinar抛出这个结果以来,有相当多的有自己的理论和想法的人与我取得了联系。所以我想把所有我知东西发布在SEOmoz社区中,抛砖引玉。
(译者注:所谓的SERP垂直信息,或是Universal Search,是指在Google的搜索结果中,不仅仅只是网页文本信息,还包括图片、新闻、群组、视频、社会化媒体信息等等多元的搜索结果,每一种结果被这篇文章的作者称为SERP的一类垂直信息)。
如果你不看Mozinar的话,可以访问这里(包含解说)。你也可以在Slideshare(点这里)下载或观看幻灯片。
在一步一步举例说明如何使用google的流量来源字符串(referral string)来解释你在Universal Search中的流量是从哪里来的之前,我想提出一个我们在AudienceWise就遇到的问题。2011年,马修.布朗和我建立了一个广告公司帮助新闻类网站的技术性SEO和受众开发。我们另一些工作,尤其是马修在纽约时报的工作,主要是努力解决Universal Search流量来源数据缺失的问题。直到我们的网络分析平台被关注之前,来自于网页搜索的访问(visit),News OneBox的链接,以及图像结果都被相同对待了,它们被毫无差别的称为:自然搜索流量(organic search traffic)。
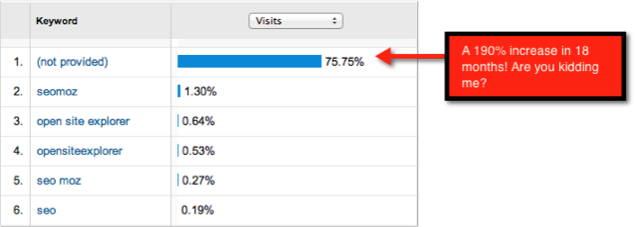
然后Google安全搜索出现,流量源数据变得更加不透明了。除了不知道流量来源于通用引擎的哪个具体垂直领域,还有约10%的情况下,我们甚至连流量来源于哪个关键词都不知道。一直困扰我们大家的问题是:如果我们完全不知道为什么客户得到了上述所谓的搜索流量,我们还怎么帮助客户的内容策略呢?不幸的是,安全搜索的范围现在已经极大扩展并占据了google流量的巨大比例。比如这里有SEOmoz最新的未知关键词占比。天啊,超过75%了……
马修和我意识到取回部分缺失数据的唯一方式就是开始看看其他来源。幸运的是,马修懂一点西班牙语并且偶然发现了这个博客。博客的作者假设google来源字符串中的ved参数对搜索结果的垂直位置起着神奇的作用。通过进行一些快速研究并查看结果中的“href”的值,他似乎有所发现。我们立刻建立了Google Analytics中报告profile的过滤器,在一个每天从google上接收30万个各种Universal Search流量的客户那里提取这个参数。两个小时后,我们拿着足够的数据开始验证作者的一些理论并提出我们自己的一些理论。我会列出所有我们发现的,给出建立GA过滤器的每个步骤,并就如何使用这些数据举几个例子。
首先,我们来看一下哪里可以找到这个参数。

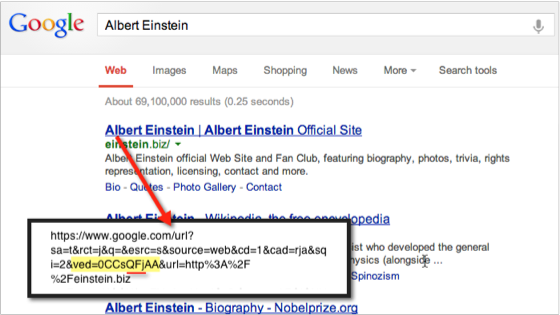
简单来说,Google流量源字符串就是在一组搜索结果中分配给每个URL的“href”的值。当用户点击上述搜索结果,在到达最终结果页面之前会被重新定向到一个google的URL,在这个例子中是Radiohead.com。Google这么做非常可能是为了集成它的内部数据,也许集成的就是与搜索引擎结果页相关的数据。我们应该并不能从这些数据中了解我们的流量来自哪里,但Google却必须利用这些数据。
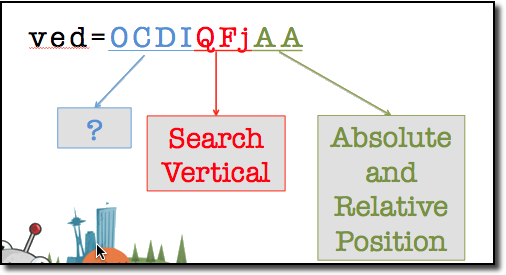
在这里我要强调两个参数:‘cd’ 和 ‘ved’。 ‘cd’参数我以前的文章中已经提及,它告诉了我们搜索结果在搜索结果集合中的位置。而‘ved’参数则据我所知,被分成了三部分,分别告诉我们搜索结果属于哪个Universal Search垂直类别(图中的Search Vertical),在这个垂直类别中的位置(相对位置,图中的Relative Position)和在整体的搜索结果中的位置(绝对位置,图中的Absolute)。接下来我将聚焦在这个帖子关于Universal Search垂直类别的部分,并在之后详述相对位置和绝对位置的情况。
我们来看几个例子。
当结果中‘ved’参数包含QFJ时才是一个标准的网页搜索结果,例如:
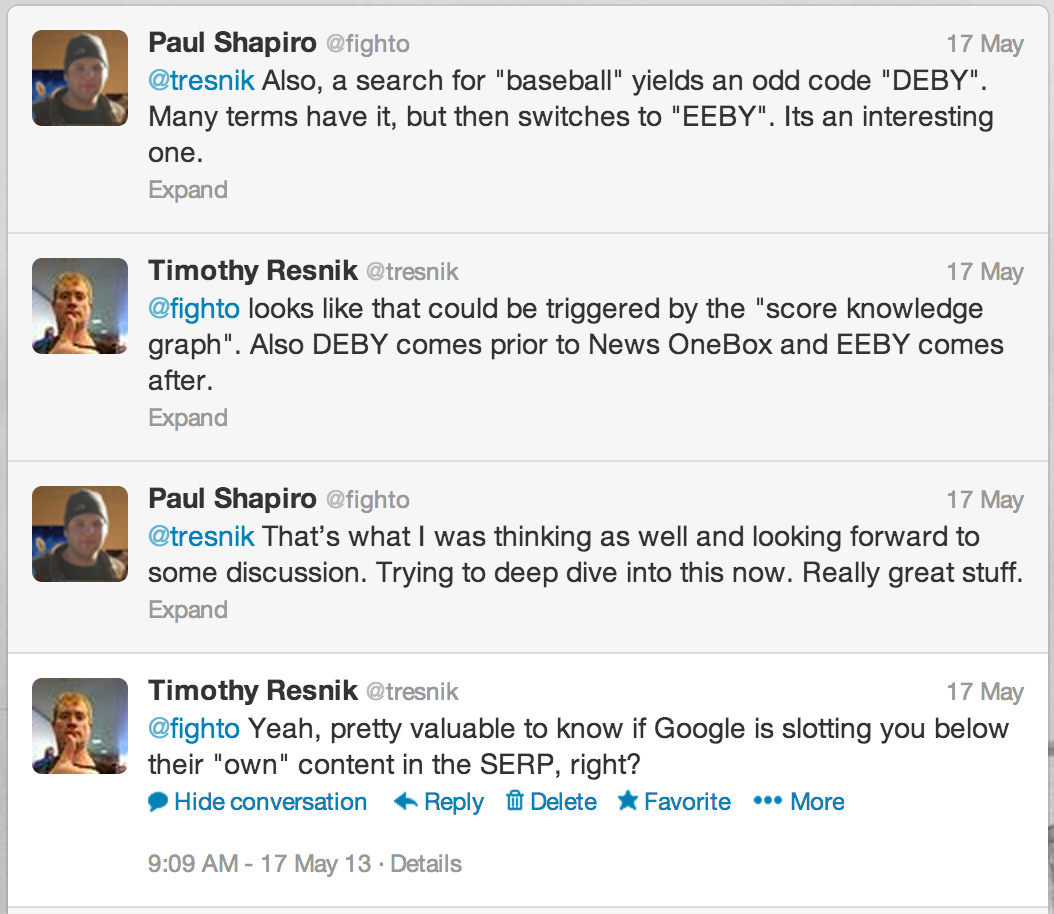
Mozinar的一个参会者敏锐地观察到了网页搜索中‘ved’的特殊变化。
上图从上到下依次是:
Paul Shapiro:而且,搜索‘baseball’产生一个奇怪的代码‘DEBY’。许多词条都有这个代码,但接着就转换成了‘EEBY’。这是很有意思的一个例子。
Timothy Resnik:看起来应该是由得分知识图引起的。同样DEBY在News OneBox之前而EEBY则在其后。
Paul Shapiro:我也是那么想的并期待更多讨论。现在尝试深入了解这个,真是极好的东西。
Timothy Resnik:是的,知道谷歌是否在搜索结果页面里面他们自己的内容下面跟踪你是很有价值的,对吧?
当QqQIw(是大写的“i”不是小写的“L”)出现时表示它是Google News OneBox里的一个通用搜索结果。当QpwI出现时表示是Google News OneBox里的一个缩略图:
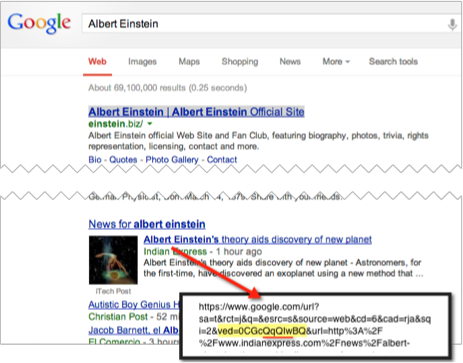
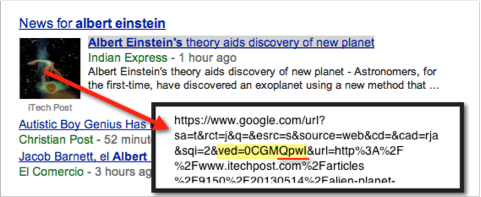
现在你们明白了。‘ved’参数中还有一些其他的值。我怀疑还有更多并且很好奇想看看这里的参会者还有那些发现可以在这里分享。
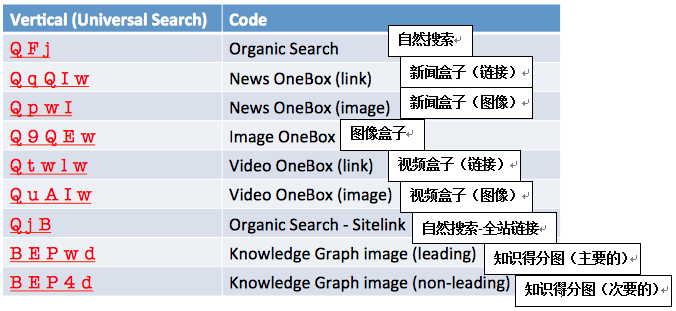
建立GA过滤器
你们现在应该充分了解了上面信息的潜在力量。我有提到过即使GA的关键词报告中显示“(未提供)”(“(not provided)”)仍然是有用的吗?我们有可能通过比较‘ved’参数来解析出关键词。有人准备好迎接这个挑战了吗?下面我给出一个例子。在GA的流量源(referral)数据中似乎只有50%的安全搜索引用中出现了‘ved’参数。如果有人可以解释这个,那么在场所有参会者都将为你竖起大拇指。
第一步:建立一个GA Profile的过滤器
在用户管理界面选择“New Profile”(“新的配置文件”),我建议不要把过滤器建立在已经现存的profile文件中,因为那样会覆盖你本来需要的数据。我把这个新的profile称为我的‘Universal Search’。
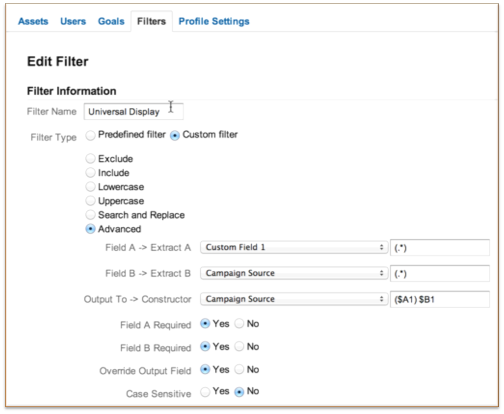
接下来,需要建立两个高级过滤器,一个用来从谷歌流量源字符串中提取‘ved’和‘cd’参数,另一个用来显示谷歌分析的数据。如下图:
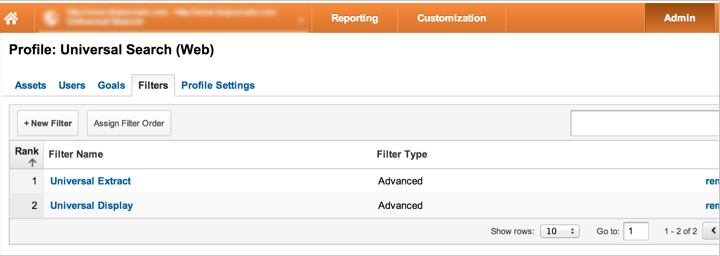
垂直搜索结果的提取

下面是我用的正则表达式的内容:
Field A (\?|&)(ved)=([^&]*)
Field B (\?|&)(cd)=([^&]*)
垂直搜索结果的显示
方法很多,我决定覆盖campaign的来源维度,因为我要在这个维度中检查我的自然搜索流量来源。
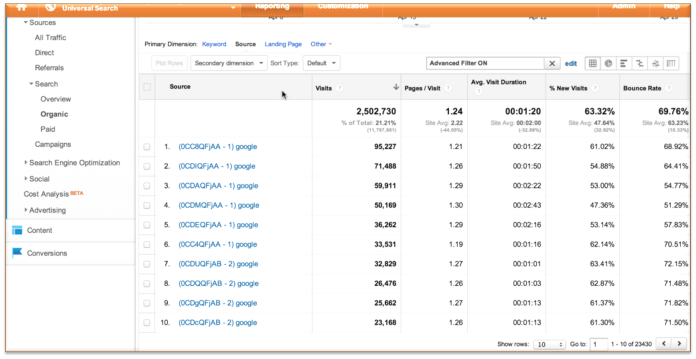
数据涌入时过滤器会工作,但结果可能并不会立即被反应出来。没关系,你只要等一天(大一点的网站一个小时左右)才能开始深挖数据。如下图:
第二步:建立高级细分
我倾向于利用Excel来做这个层级的分析,单用高级细分的功能也能让这个事情漂亮地显示在GA中。我会讲解一个,剩下的你就知道应该怎么做了。
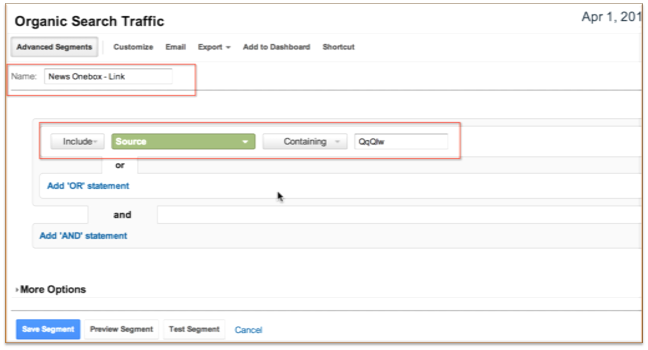
用你正在分析的Universal Search的垂直类别来命名你的高级细分比较合适。在这个例子中,我称之为Google News OneBox中的一个标准‘蓝链’结果。从那里,你要做的就是寻找所有包含你要分析分离的‘ved’的源。在这个例子中,我们正在找‘QqQIw’。
你将看到类似下面的情况:
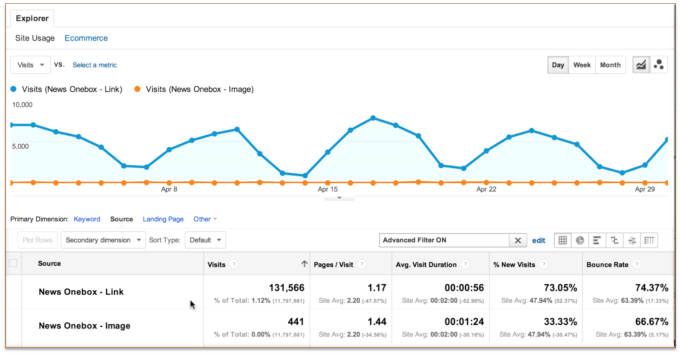
哇!正好有个可操作的结果摆在我面前。看起来这个站需要做图像的SEO优化。谷歌显然尊重这个站点的新闻权威地位,但却认为这个站的图片相当不怎么样。
另一个有用的值得去琢磨的‘ved’是Sitelinks里面的ved。(译者注:所谓的Sitelinks是指搜索结果的主条目下面还有这个网站一些内容或频道的链接。)Sitelinks是一个品牌搜索产生的结果的集合。谷歌在算法上决定应该包含哪些链接,但网站管理员有权限在网站管理工具中给链接降级。因此,‘ved’参数可以在衡量被Google记录为Sitelinks的那些页面的表现,以及我们可以做针对性的哪些行动(例如给一些没有点击流量的Sitelink页面降级)。为了搞清楚哪一条Sitelink送来的流量,需要看下流量源字符串传过来的cd参数。我们把这个功能加在了过滤器中,你的数据会如下所示:
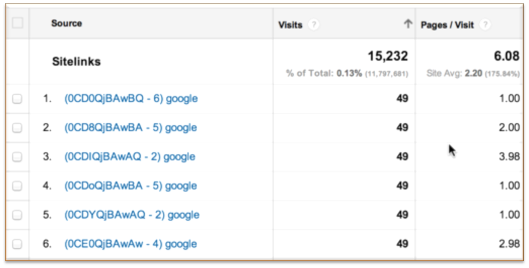
下面是cd参数的值在全站链接结果中的意义。
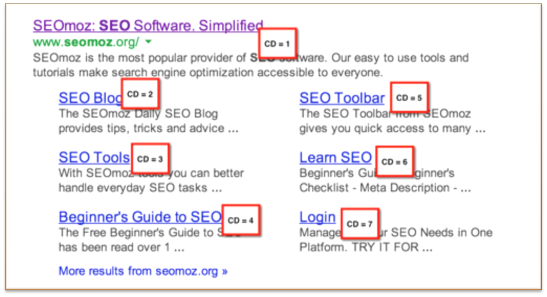
有数不清的利用上面的功能强化SEO行动的用例。我会列举几个,大家可以在评论中添加自己的。
计算不同的SEO结果的投资回报率和资源配置:新闻,图像,品牌和语义标记。作为市场营销人员,定量化的价值才是真正的价值。SEO面临的挑战是证明自己的价值。虽然不能靠它最终解决问题,但却能曝光那些需要我们加强工作的地方。
优化品牌搜索的Sitelinks:据我上面所述,知道自己的流量来自哪个sitelinks是很有用的。有一个领域可以让你减少由于安全搜索导致的关键词数据缺失。当你发现关键词为“未知”并且ved = xxxxQjB时,你可以大胆相信关键词实际上就是你的品牌词。
谷歌新闻的图像优化:Google News OneBox的顶部链接通常是一个不同的源而不是图像缩略图。如果ved = xxxxQqQIw ÷ ved = xxxxQpwI(或者叫链接与图像的比例)失衡,则说明图像需要优化。新闻发布者需可以用这个数据来衡量比对优化结果和预先建立的最低预期。
优化视频缩略图:链接旁边的视频图像通常跟链接是同一个源。市场营销人员可以用上面描述的相似的比例来分析当ved = xxxxQuAIw时的点击通过率和页面分析
分析语义标记的效果:由于SERP中开始包含更多的可点击的rich-snippets和知识图表元素,很明显已经可以解析和理解使用ved参数的字符串。我已经开始只看带有rich-snippets的结果,但内部数据表明ved参数甚至可以看出我们点击的事件和片段是哪种类型的。下面是几个例子:(这是一个可以让我们的社区做更多深挖的地方)
搜索结果美化分析:如果您能抓取谷歌搜索结果页面(SERP页面),你就会知道页面上有哪个ved参数,以及每个结果的垂直搜索结果类别是什么。Href参数存在于JavaScript中,所以找到它最简单的方式就是使用一个类似PhantomJS这样的纯JAVA浏览器
事件标记:ved = xxxBE0MGM
音乐标记: ved = xxxQ6hEw
以上差不多就是我第一篇(希望会有更多)完整的关于ved的帖子。在未来几个月内,Moz会搜集各种不同关键词的大量搜索结果的引用字符串数据。我们计划使出浑身解数来找到最有用的元素。与此同时,我想把这个帖子作为讨论开始的地方,请在评论中留下你们的想法。
开始深挖吧!