缓存算法–LRU
LRU
LRU是Least Recently Used 的缩写,翻译过来就是“最近最少使用”,也就是说,LRU缓存把最近最少使用的数据移除,让给最新读取的数据。而往往最常读取的,也是读取次数最多的,所以,利用LRU缓存,我们能够提高系统的performance.
LRU实现
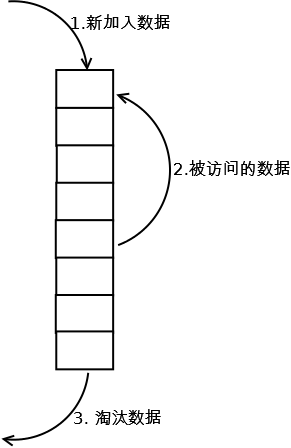
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
LRU分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
实现
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下:
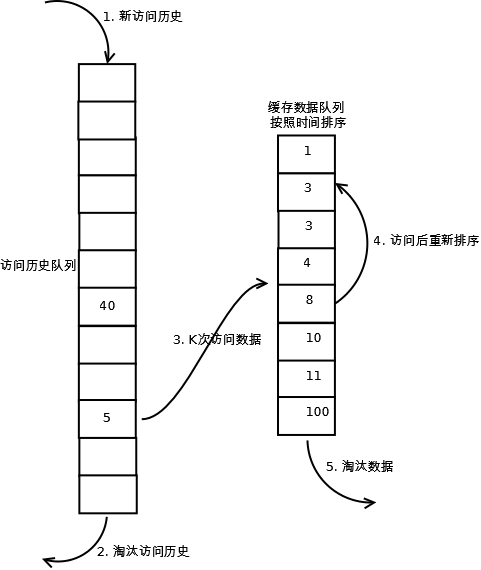
1. 数据第一次被访问,加入到访问历史列表;
2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
4. 缓存数据队列中被再次访问后,重新排序;
5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
分析
【命中率】
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】
由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU要高。
建议继续学习:
- 浅析http协议、cookies和session机制、浏览器缓存 (阅读:16706)
- 分布式缓存系统 Memcached 入门 (阅读:15575)
- 强制刷新本地 DNS 缓存记录 (阅读:10118)
- php缓存与加速分析与汇总 (阅读:7281)
- Web应用的缓存设计模式 (阅读:7032)
- 浏览器缓存机制 (阅读:6601)
- 谈冷热数据 (阅读:6536)
- 使用memc-nginx和srcache-nginx构建高效透明的缓存机制 (阅读:6466)
- 缓存设计的一些思考 (阅读:6410)
- 系统架构的一些思考 (阅读:6325)
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:Eric 来源: JavaRanger - 专注JAVA高性能程序开发、JVM、Mysql优化、算法
- 标签: LRU 缓存
- 发布时间:2015-12-13 22:12:12

-
 [927] WordPress插件开发 -- 在插件使用
[927] WordPress插件开发 -- 在插件使用 -
[126] 解决 nginx 反向代理网页首尾出现神秘字
-
[51] 如何保证一个程序在单台服务器上只有唯一实例(
-
[50] 整理了一份招PHP高级工程师的面试题
-
[48] CloudSMS:免费匿名的云短信
-
[48] Innodb分表太多或者表分区太多,会导致内
-
[48] 用 Jquery 模拟 select
-
[48] 全站换域名时利用nginx和javascri
-
[48] 海量小文件存储
-
[46] ps 命令常见用法
