限流系统是对资源调用的控制组件,主要涵盖授权、限流、降级、调用统计等功能模块。限流系统有两个基础概念:资源和策略,对特定的资源采取不同的控制策略,起到保障应用稳定性的作用。限流系统提供了多个默认切入点覆盖了大部分使用场景,保证对应用的低侵入性;同时也支持硬编码或者自定义aop的方式来支持特定的使用需求。限流系统提供了全面的运行状态监控,实时监控资源的调用情况(qps、rt、限流降级等信息)。
如何利用限流系统的特性,来统计热点呢?在这里,我们主要介绍一下,限流系统是如何来判断热点的,它的工作原理是什么,它的性能如何;它目前已经在哪些场景里面使用。
1. 热点的特性
a) 海量的统计基数
可能的热点分为两种,一种是事前已知的(例如营销人员的已经整理出秒杀商品的列表),另外一种是突发的,不可以预计的(例如被刷单的商品,或者是黑马产品)。对于前面一种,只需要计算这些已知的列表即可,但是对于后者,由于基数是海量的,举个例子,如果有一个方法,它传入的参数是商品id, 这个商品的id以淘宝的规模来说,是上亿的。如果把所有的商品id都记录统计起来,再进行排序,统计出热点,这对于实时的工具来说,是不可行的。所以为了解决热点统计,我们必须找到一个好的数据结构,这个结构能够仅保存最常常被访问的一定数量商品id,并且可以控制结构的大小,统计量。这是非常重要的一个步骤。
b) 统计热点的单位时间的维度
这里有一个必须强调的概念: 单位时间而不是总访问量。 打个比方,一个商品,在一小时以内被访问了3600次,但是它很均匀的每秒被访问一次,那么这个商品可能在系统的承受范围之内,并会对系统带来损伤;而另外一个商品,它一小时被访问了60次,但都落在同一秒,那么这个商品可能就是一个热点商品。对于”单位时间”的定义,是决策一个参数是否成为热点的一个重要的因素;如果太粗,必然会带来毛刺,导致系统性能不平滑;如果太细,会给性能带来挑战。
c) 在分布式系统给统计带来的挑战
热点的统计范围可能是单机,也可能是集群。如何能快速的在集群中统计,并且让限流规则在单机上生效,是非常重要的。
2. 如何解决上述问题
2.1 首先,找到一个可行的数据结构
这个结构必须满足访问修改快速,并发性好,占用内存空间少,存储的个数大小可控制,并且可以驱逐访问量少的entry,从而可以达到实时统计热点的查询数字。
其实,业界有一个现成的好结构。它就是google团队用于guava里的ConcurrentLinkedHashMap (http://code.google.com/p/concurrentlinkedhashmap)。
2.1.a 支持并发。它是实现了ConcurrentMap接口的。基本上它的实现是遵循concurrentMap的思想的。这里就不多赘述。
2.1.b 它把我们普通concurrenthashmap的segments用一个额外的双链表维护起来,通过操作这个链表,里面的entry可以在O(1)的时间之类删除或者重新排序。当一个entry被访问,则被移动到表头;当这个map的容量超过预设,则移除位于链表尾的entry。这样就可以保证表头是最新被使用的entry,表尾是最近最少被使用的entry
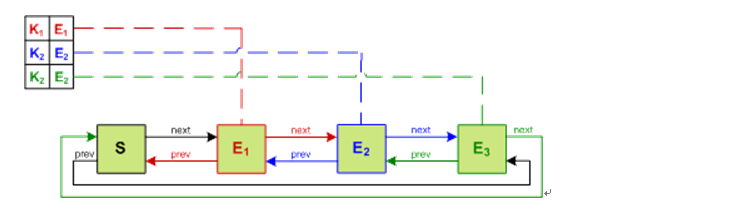
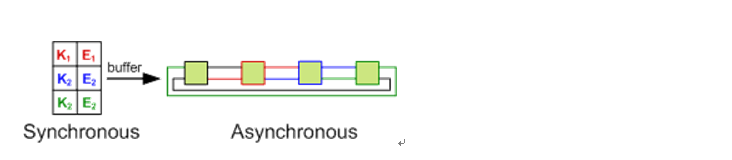
2.1.c 从另外一个角度来说,可以把ConcurrentLinkedHashMap 分成两个view. 一个是同步的,一个是异步的。Hashtable对于调用方来说是同步的,链表对于调用方式不透明的,异步的。
2.1.d 性能和concurrenthashmap的比较, 肯定比concurrenthashmap差,但是属于可以忍受的范围。下面是官方给出的数据
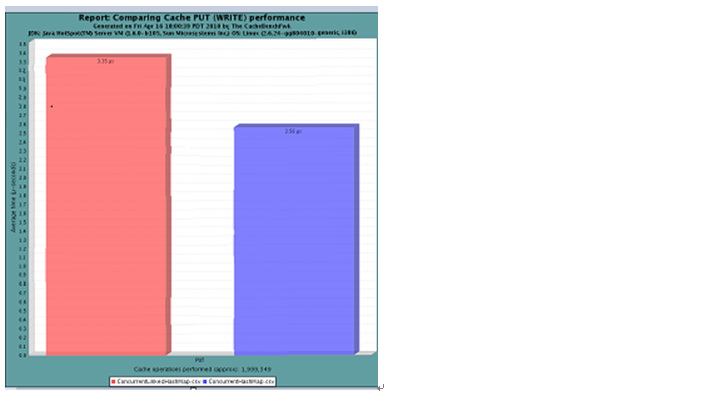
综上所述,我们可以利用这个LRU concurrent map link,保证我们在单位时间内,仅保存有限数量访问量较高的key, 最近比较少访问的key,我们则可以认为它不是热点,当map的Size达到上限之后,清除这个key
2.2 统计单位时间的维度
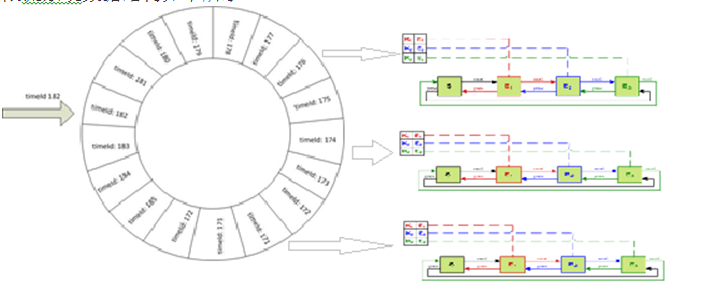
现在我们来看第二个问题,如何统计单位时间的key的qps. 其实这个正是限流系统的拿手好戏,用动态滑动窗口平滑的统计qps.
简单的说,限流系统为每个簇点(可以简单的理解为需要统计的方法),做了一个滑动窗口。更具体的说,即限流系统把采样窗口长度设为2秒,这个采样窗口又被分割为20个格子。通过用一定的算法来统计这20个格子的平均滑动窗口累积平均值来进行决策。
为什么采用平均滑动窗口累计平均值是为了削平毛刺qps(在某个点突发的qps)对整体的影响。该公式如下:

更具体的说明在: http://en.wikipedia.org/wiki/Moving_average#Exponential_moving_average 可以查到。
说到这里,聪明的读者应该早就猜到了,限流系统通过把两个利器结合起来,即滑动窗口和google concurrent link hashmap,可以统计在固定的时间,最常常使用的参数的值。
限流系统数据结构如下所示:
具体的代码在: http://gitlab.alibaba-inc.com/middleware-asp/限流系统 欢迎大家来指正
2.3 如何解决集群的挑战
2.3.1 幸运的是,限流系统天生自带获取簇点qps的功能
使用过限流系统的人都会发现,8719这个端口是被限流系统占用了的。通过这个端口,我们可以用获取到簇点的qps统计信息。有了这个“后门”,我们就可以轻松快速的获取到qps的信息了
2.3.2 如何在大集群里汇总这些qps的信息
接下来要解决的问题就是,如何在上千台机器里面快速汇总这些信息。还好之前我们在做2.0.7的集群统计的时候,有了一定的经验。 这个算法后来也用在了预案分配巨大的url task中。简单的说,就是用一个队列来放任务,多个线程来执行任务,一个线程来merge取回的结果。通过使用这个方法,一个比较大的集群,例如buy等,2秒可以返回统计结果。
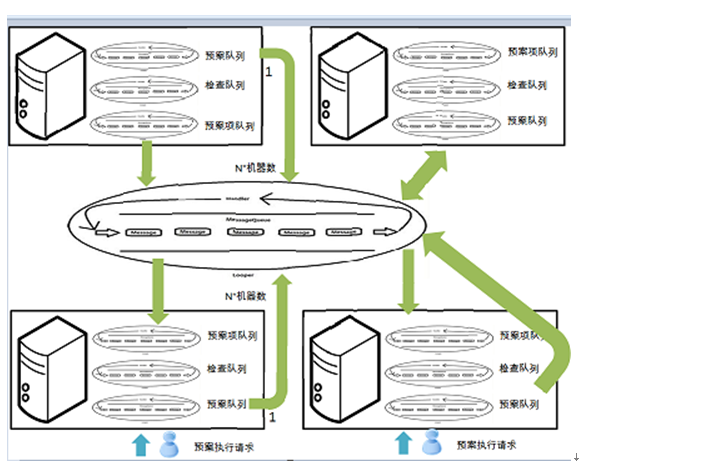
有了集群的总体汇总信息之后,我们再将这个信息利用diamond来推广到具体的机器上去。这样的延迟大概是2-3s左右。
3 总结以及限流系统性能报告:
简单的说,存放一个这样的结构,大概大小是8k. 它的默认参数是每个簇点的存放2s的滑动窗口,20个格子,每个格子最多可以保存200个参数,那么在最坏的情况下,这个结构的大小将会是8k+4000个参数大小。
吞吐量在我的日常机器上是29W,在生产机上应该会更好。