Scheme 初步
之前定了每年学习一门语言的目标,自然不能轻言放弃。今年目标:简单掌握 Scheme。
因为自己接触这门语言也不过寥寥数天,所以更多的会以引导的方式简单介绍语法,而不会 (也没有能力) 去探讨什么深入的东西。本文很多例程和图示参考了紫藤貴文的《もうひとつの Scheme 入門》这篇深入浅出的教程,这篇教程现在也有英译版和中译版。我自己是参照这篇教程入门的,一方面这篇教程可以说是能找到合适初学者学习的很好的材料,另一方面也希望能挑战一下自己的日文阅读能力 (结果对比日文和英文看下来发现果然还是日文版写的比较有趣,英文翻译版本就太严肃了,而中文版感觉是照着英文译版二次翻译的,有不少内容上的缺失和翻译生硬的问题,蛮可惜的)。因为中文的 Scheme 的资料其实很少,所以顺便把自己学习的过程和一些体会整理记录下来,算是作为备忘。本文只涉及 Scheme 里最基础的一些语法部分,要是恰好能够帮助到后来的学习者入门 Scheme,那更是再好不过。
为什么选择学 Scheme
三方面的原因。
首先是自己基本上对函数式语言的接触为零。平时工作和自己的开发中基本不使用函数式编程,大脑已经被指令式程序占满,有时候总显得不很灵光。而像 Swift 这样的语言其实引入了一些函数式编程的可能性。多接触一些函数式的语言,可能会对实际工作中解决某些问题有所帮助。而 Scheme 比起另一门常用 Lisp 方言 Common Lisp 来说,要简单不少。比较适合像我这样非科班出身,CS 功力不足的开发者。
其次,Structure and Interpretation of Computer Programs (SICP) 里的例程都是使用 Scheme 写的。虽然不太有可能有时间补习这本经典,但是如果不会一点 Scheme 的话,那就完全没有机会去读这本书了。
最后,Scheme 很酷也很好玩,虽然在实际中可能并没有鸟用,但是和别人说起来自己会一点 Scheme 的话,那种感觉还是很棒的。
其实还有一点对 hacker 们很重要,如果你喜欢使用像 Emacs 这样的基于 Lisp 的编辑器的话,使用 Scheme 就可以与它进行交互或者是扩展它的功能了。
那让我们尽快开始吧。
成为 Scheme Hacker 的第一步
成为 Scheme Hacker 的第一步,当然是安装和配置运行环境,同时这也是最难跨过去的一步。想想有多少次你决心学习一门新语言的时候,在配置好开发环境后就再也没有碰过吧。所以我们需要尽快跨过这个步骤。
最简单的开发环境点击这个链接,然后你就可以开始用 Scheme 编程了。如果你更喜欢在本地环境和终端里操作的话,可以下载 MIT/GUN Scheme。在 OS X 上解包后是一个 .app 文件,运行 .app 包里的 /Contents/Resources/mit-scheme 就可以打开一个解释器了。
Hello 1 + 1
虽然大部分语言都是从 Hello World 开始的,但是对于 Scheme 来说,计算才是它的强项。所以我们从 1 + 1 开始。计算 1 + 1 程序在 Scheme 中是这样的:
1 ]=> (+11);Value: 21 ]=>1 ]=> 是输入提示符,我们输入的内容是 (+ 1 1),得到的结果是 2。虽然语句很简单,但是这里包含了 Scheme 的最基本的语素,有三个地方值得特别注意。
成对的括号。一对括号表示的是一步计算,这里
(+ 1 1)表示的就是 1 + 1 这一步运算。紧接括号的是函数名字,再然后是函数的参数。在这里,函数名字就是 "+",两个 1 是它的参数。Scheme 中大部分的运算符其实都是函数。
使用空格,tab 或是换行符来分割函数名以及参数。
和别的很多语言一样,Scheme 在函数调用时也有计算优先级,会先对输入的参数进行计算,然后再进行函数调用。还是以上面的 1 + 1 为例。首先解释器看到加号,但是此时运算并没有开始。解释器会先计算第一个参数 1 的值 (其实就是 1),然后计算第二个参数 1 的值 (其实还是 1)。然后再用两个计算得到的值来进行加法运算。
另外,"+" 这个函数不仅可以接受两个参数,其实它是可以接受任意多个参数的。比如 (+)的结果是 0,(+ 1 2 3 4) 的结果是 10。
学会加法以后,乘法自然也不在话下了。
1 ]=> (*23);Value: 61 ]=>减法和除法稍微不同一些,因为它们并不满足交换律,所以可能会有疑问。但是只要记住参数是平等的,它们会顺次计算就可以了。举个例子:
1 ]=> (-1053);Value: 21 ]=> (/2022);Value: 5对于除法,有两个需要注意的地方。首先和我们熟悉的很多语言不同,Scheme 是默认有分数的概念的。比如在 C 系语言中,如果只是在整数范围的话,我们计算 10 / 3 的结果会是 3;如果是浮点型的话结果为 3.33333。而在 Scheme 中,结果是这样的:
1 ]=> (/103);Value: 10/3这是一个分数,就是三分之十,绝对精确!
另一个需要注意的是,如果 / 只有一个输入的话,它的意思是取倒数。
1 ]=> (/2);Value: 1/2如果你需要一个浮点数而不是分数的话,可以使用 exact->inexact 方法,将精确值转为非精确值:
1 ]=> (exact->inexact(/103));Value: 3.3333333333333335Scheme 也内建定义了一些其他的数学运算符号,如果你感兴趣,可以查看 R6RS 的相关章节。
R6RS (Revisedn Report on the Algorithmic Language Scheme, Version 6) 是当前的 Scheme 标准。
定义变量和方法,Hello World
通过简单的 1 + 1 运算我们可以大概知道 Scheme 中的奇怪的括号开头的意思了。有了这个作为基础,我们可以来看看如何定义变量和方法了。
Scheme 中通过 define 来定义变量和方法:
; s 是一个变量,值为 "Hello World"(define s "Hello World"); f 是一个函数,它不接受参数,调用时返回 "Hello World"(define f (lambda()"Hello World"))上面的 lambda 可以生成一个闭包,它接受两个参数,第一个是一个空的列表 (),表示这个闭包不接受参数;第二个是 "Hello World" 这个字符串。在解释器中定义好两者之后,就可以进行调用了:
1 ]=> (define s "Hello World");Value: s1 ]=> (define f (lambda()"Hello World"));Value: f1 ]=> s;Value 24: "Hello World"1 ]=> f;Value 25: #[compound-procedure 25 f]1 ]=> (f);Value 26: "Hello World"既然我们已经知道了 lambda 的意义和用法,那么定义一个接受参数的函数也就不是什么难事了。比如上面的 f,我们想要定义一个接受名字的函数的话:
1 ]=> (define hello (lambda(name)(string-append"Hello " name "!") ) );Value: hello1 ]=> (hello"onevcat");Value 27: "Hello onevcat!"很简单,对吧?其实甚至可以更简单,define 的第一个参数可以是一个列表,其中第一个元素是函数名名字,之后的是参数列表。
用专业一点的术语来说的话,就是 define 的第一个参数是一个 cons cell 的话,它的 car 是函数名,cdr 是参数。关于这些概念我们稍后再仔细说说。
于是上面的方法可以简单地写作:
1 ]=> (define(hello name)(string-append"Hello " name "!"));Value: hello1 ]=> (hello"onevcat");Value 28: "Hello onevcat!"光说不练假把式,所以留个小练习给大家吧,用 define 来定义一个函数,让其为输入的数字 +1。如果你无压力地搞定了的话,我们就可以继续看看 Scheme 里的条件语句怎么写了。
条件分支和布尔逻辑
不论是什么编程语言,条件分支或者类似的概念应该都是不可缺少的部分。在 Scheme 中,使用 if 可以进行条件分支的处理。和其他很多语言不一样的地方在于,函数式语言中函数才是一等公民,if 的行为也和一个其他的普通函数很相似,是作为一个函数来使用的。它的语法是:
(if condition ture_action false_action)与普通函数先进行输入的取值不同,if 将会先对 condition 运算式进行取值判断。如果结果是 true (在 Scheme 中用 #t 代表 true,#f 代表 false),则再对 ture_action 进行取值,否则就执行 false_action。比如我们可以实现一个 abs 函数来返回输入的绝对值:
1 ]=> (define(abs input)(if(< input 0)(- input) input));Value: abs1 ]=> (abs100);Value: 1001 ]=> (abs-100);Value: 100也许你已经猜到了,Scheme 的布尔逻辑也是遵循函数式的,最常用的就是 and 和 or 两种了。和常见 C 系语言类似的是,and 和 or 都会将参数从左到右取值,一旦遇到满足停止条件的值就会停止。但是和传统 C 系语言不同,布尔逻辑的函数返回的不一定就是 #t 或者 #f,而有可能是输入值,这和很多脚本语言的行为是比较一致的:and 会返回最后一个非 #f 的值,而 or 则返回第一个非 #f 的值:
1 ]=> (and#f0);Value: #f1 ]=> (and12"Hello");Value 13: "Hello"1 ]=> (or#f0);Value: 01 ]=> (or12"Hello");Value: 11 ]=> (or#f#f#f);Value: #f在很多时候,Scheme 中的 and 和 or 并不全是用来做条件的组合,而是用来简化一些代码的写法,以及为了顺次执行一些代码的。比如说下面的函数在三个输入都为正数的情况下返回它们的乘积,可以想象和对比一下在指令式编程中同样功能的实现。
(define(pro3and a b c)(and(positive? a)(positive? b)(positive? c)(* a b c) ))除了 if 之外,在 C 系语言里另一种常见的条件分支语句是 switch。Scheme 里对应的函数是 cond。cond 接受多个二元列表作为输入,从上至下依次判断列表的第一项是否满足,如果满足则返回第二项的求值结果并结束,否则一直继续到最后的 else:
(cond(predicate_1 clauses_1)(predicate_2 clauses_2) ...... (predicate_n clauses_n)(else clauses_else))在新版的 Scheme 中,标准里加入了更多的流程控制的函数,它们包括 begin,when 和 unless 等。
begin 将顺次执行一系列语句:
(define(foo)(begin(display"hello")(newline)(display"world") ))when 当条件满足时执行一系列代码,而 unless 在条件不满足时执行一系列代码。这些改动可以看出一些现代脚本语言的特色,但是新的标准据说也在 Scheme 社区造成了不小争论。虽然结合使用 if,and 和 or 肯定是可以写出等效的代码的,但是这些额外的分支控制语句确实增加了语言的便利性。
循环
一门完备的编程语言必须的三个要素就是赋值,分支和循环。前两个我们已经看到了,现在来看看循环吧:
do
1 ]=> (do((i0(+ i 1))); 初始值和 step 条件((> i 4)); 停止条件,取值为 #f 时停止(display i); 循环主体 (命令) )01234;Value: #t唯一要解释的是这里的条件是停止条件,而不是我们习惯的进入循环主体的条件。
递归
可以看出其实 do 写起来还是比较繁琐的。在 Scheme 中,一种更贴合语言特点的写法是使用递归的方式来完成循环:
1 ]=> (define(count n)(and(display(-4 n))(if(= n 0)#t(count(- n 1))) ) );Value: count1 ]=> (count4)01234;Value: #t列表和递归
也许你会说,用递归的方式看起来一点也不简单,甚至代码要比上面的 do 的版本更难理解。现在看来确实是这样的,那是因为我们还没有接触 Scheme 里一些很独特的概念,cons cell 和 list。我们在上面介绍 define 的时候曾经提到过,cons cell 的 car 和 cdr。结合这个数据结构,Scheme 里的递归就会变得非常好用。
那么什么是 cons cell 呢?其实没有什么特别的,cons cell 就是一种数据结构,它对应了内存的两个地址,每个地址指向一个值。
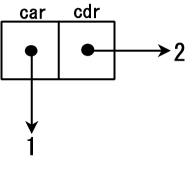
要初始化一个上面图示的 cons cell,可以使用 cons 函数:
1 ]=> (cons12);Value 13: (1 . 2)我们可以使用 car 和 cdr 来取得一个 cons cell 的两部分内容 (car 是 "Contents of Address part of Register" 的缩写,cdr 是 "Contents of Decrement part of Register"):
1 ]=> (car(cons12));Value: 11 ]=> (cdr(cons12));Value: 2cons cell 每个节点的内容可以是任意的数据类型。一种最常见的结构是 car 中是数据,而 cdr 指向另一个 cons cell:
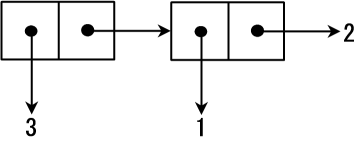
上面这样的数据结构对应的生成代码为:
1 ]=> (cons3(cons12));Value 14: (3 1 . 2)有一种特殊的 cons cell 链,其最后一个 cons cell 的 cdr 为空列表 '(),这类数据结构就是 Scheme 中的列表。
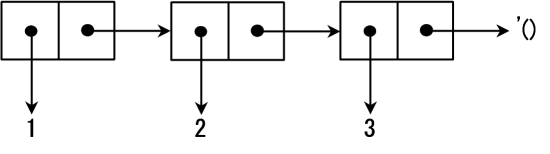
对于列表,我们有一种更简单的创建方式,就是类似 '(1 2 3) 这样。对于列表来说,它的 cdr 值是一个子列表:
1 ]=> '(123);Value 15: (1 2 3)1 ]=> (car '(123));Value: 11 ]=> (cdr '(123));Value 16: (2 3)而循环其实质就是对一列数据进行处理的过程,结合 Scheme 列表的特性,我们意识到如果把列表运用在递归中的话,car 就是遍历的当前项,而 cdr 就是下一次递归的输入。Scheme 和递归调用可以说能配合得天衣无缝。
比如我们定义一个将列表中的所有数都加上 1 的函数的话,可以这么处理:
(define(ins_ls ls)(if(null? ls) '()(cons(+(car ls)1)(ins_ls(cdr ls))) ))(ins_ls '(12345));=> (2 3 4 5 6)尾递归
递归存在性能上的问题,因为递归的调用需要在栈上保持,然后再层层返回,这会造成很多额外的开销。对于小型的递归来说还勉强可以接受,但是对于递归调用太深的情况来说,这显然是不可扩展的做法。于是在 Scheme 中对于大型的递归我们一般会倾向于将它写为尾递归的方式。比如上面的加 1 函数,用尾递归重写的话:
(define(ins_ls ls)(ins_ls_interal ls '()))(define(ins_ls_interal ls ls0)(if(null? ls) ls0 (ins_ls_interal(cdr ls)(cons( + (car ls)1) ls0))))(define(rev_ls ls)(rev_ls_internal ls '()))(define(rev_ls_internal ls ls0)(if(null? ls) ls0 (rev_ls_internal(cdr ls)(cons(car ls) ls0))))(rev_ls(ins_ls '(12345)));=> (2 3 4 5 6)函数式
上面介绍了 Scheme 的最基本的赋值,分支和循环。可以说用这些东西就能够写出一些基本的程序了。一开始会比较难理解 (特别是递归),但是相信随着深入下去和习惯以后就会好很多。到现在为止,除了在定义函数时,其实我们还没有直接触碰到 Scheme 的函数式特性。在 Scheme 里函数是一等公民,我们可以将一个函数作为参数传给另外的函数并进行调用,这就是高阶函数。
一个最简单的例子是排序的时候我们可以将一个返回布尔值的函数作为排序规则:
1 ]=> (sort '(7883909967292828775441795340264429582239) <);Value 13: (2239 2644 2828 2958 4179 5340 6729 7754 7883 9099)更甚于我们可以使用一个匿名函数来控制这个排序,比如按照模 100 之后的大小 (也就是数字的后两位) 进行排序:
1 ]=> (sort '(7883909967292828775441795340264429582239)(lambda(x y)(<(modulo x 100)(modulo y 100))));Value 14: (2828 6729 2239 5340 2644 7754 2958 4179 7883 9099)类似这样的特性在一些 modern 的语言里并不算罕见,但是要知道 Scheme 可是有些年头的东西了。类似的还有 map,filter 等。比如上面的 list 加 1 的例子,用 map 函数就可以非常简单地实现:
(map(lambda(x)(+ x 1)) '(12345));=> (2 3 4 5 6)接下来...
篇幅有限,再往长写的话估计没什么人会想看完了。到这里为止关于 Scheme 的一些基础内容也算差不多了,大概阅读最简单的 Scheme 程序应该也没有太大问题了。在进一步的学习中,如果出现不认识的函数或者语法的话,可以求助 SRFI 下对应的文档或是在 MIT/GNU Scheme 文档中寻找。
本文一开始提到的教程很适合入门,之后的话可以开始参看 SICP,可以对程序设计和 Scheme 的思想有更深的了解 (虽然阅读 SICP 的目的不应该是学 Scheme,Scheme 只是帮助你进行阅读和练习的工具)。因为我自己也就是个愣头青的初学者,所以无法再给出其他建议了。如果您有什么好的资源或者建议,非常欢迎在评论中提出。
另外,相比起 Scheme,如果你想要在实际的工程中使用 Lisp 家族的语言的话,Racket 也许会是更好的选择。相比于面向数学和科学计算来说,Racket 支持对象类型等概念,更注重在项目实践方面的运用。
就这样吧,我要继续去和 Scheme 过周末了。
建议继续学习:
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:OneV's Den 来源: OneV's Den
- 标签: Scheme
- 发布时间:2016-03-14 23:29:53

-
 [782] WordPress插件开发 -- 在插件使用
[782] WordPress插件开发 -- 在插件使用 -
[62] Java将Object对象转换为String
-
[61] cookie窃取和session劫持
-
[59] 学习:一个并发的Cache
-
[55] 你必须了解的Session的本质
-
[53] 再谈“我是怎么招聘程序员的”
-
[52] Linux如何统计进程的CPU利用率
-
[49] 最萌域名.cat背后的故事:加泰与西班牙政府
-
[48] 解读iPhone平台的一些优秀设计思路
-
[48] 我对技术方向的一些反思
