在一篇文章《动态调整的基础 —— 配置中心》中我们聊了关于Native App动态化的问题。无疑Native的动态化能力较Web要弱很多,很多操作是依赖版本节奏的。这就导致在Native App上许多决策无法快速验证,对存在不足的逻辑没办法快速修正。受到这些条件的限制,那个唯快不破的铁律在Native App上遭遇到了尴尬。每一个产品决策会变得异常谨慎,因为一个错误的决策要持续整个版本周期可能被修复。慢慢的我们就会发现,不出错会成为做出决策的重要因素,而有意义却退居二线。
所以具备快速验证和及时修正这两个能力就显得非常重要,打造这样的能力需要一个完整的解决方案。我们认为,这个方案是一个以A/B测试为核心,结合周边多个系统能力,共同组成的一个试错平台。在这个平台上,我们的团队,不管是业务方还是工程师,都可以快速应变,不畏惧出错,变得灵动起来。
A/B测试
说到A/B测试,这到底是个什么东西?我个人的理解是:狭隘的说,A/B测试是以分桶为核心,以依据分桶结果执行不同逻辑为基本原理,以获取最优解为目的一种测试方案。
一般认为,A/B测试的主要场景有两种:对比实验和灰度发布。
对比实验
所谓对比实验,就是同一时间执行两套甚至多套方案,通过对比反馈数据,对这些方案作出评价。
灰度发布
灰度发布则是,某个新功能或版本正式发布前,先圈一部分人作为小白鼠,试用这个功能或版本。我们从稳定性,业务效果等多方面观察这部分试用者的反应,对这个新功能或版本作出评价。
不管是对比实验还是灰度发布,最终目的都是期望只是发布带来的效果最大化。
体系
一个单一的A/B测试框架并不能帮助我们达成目的,还需要诸多周边能力辅助。要实现丰富的分桶条件,需要设备和用户的信息收集机制;要实现线上逻辑实时调整,要Native逻辑动态化方案;要实现动态调整分桶逻辑,需要分桶条件下发系统;实现观察对比实验结果,需要数据收集和分析平台,等等。
在天猫,我们整合各方能力搭建了一个称为AirTrack的试错平台。在AirTrack平台上动态实验条件,实时运算SDK和数据收集和反馈平台三部分是重中之重。
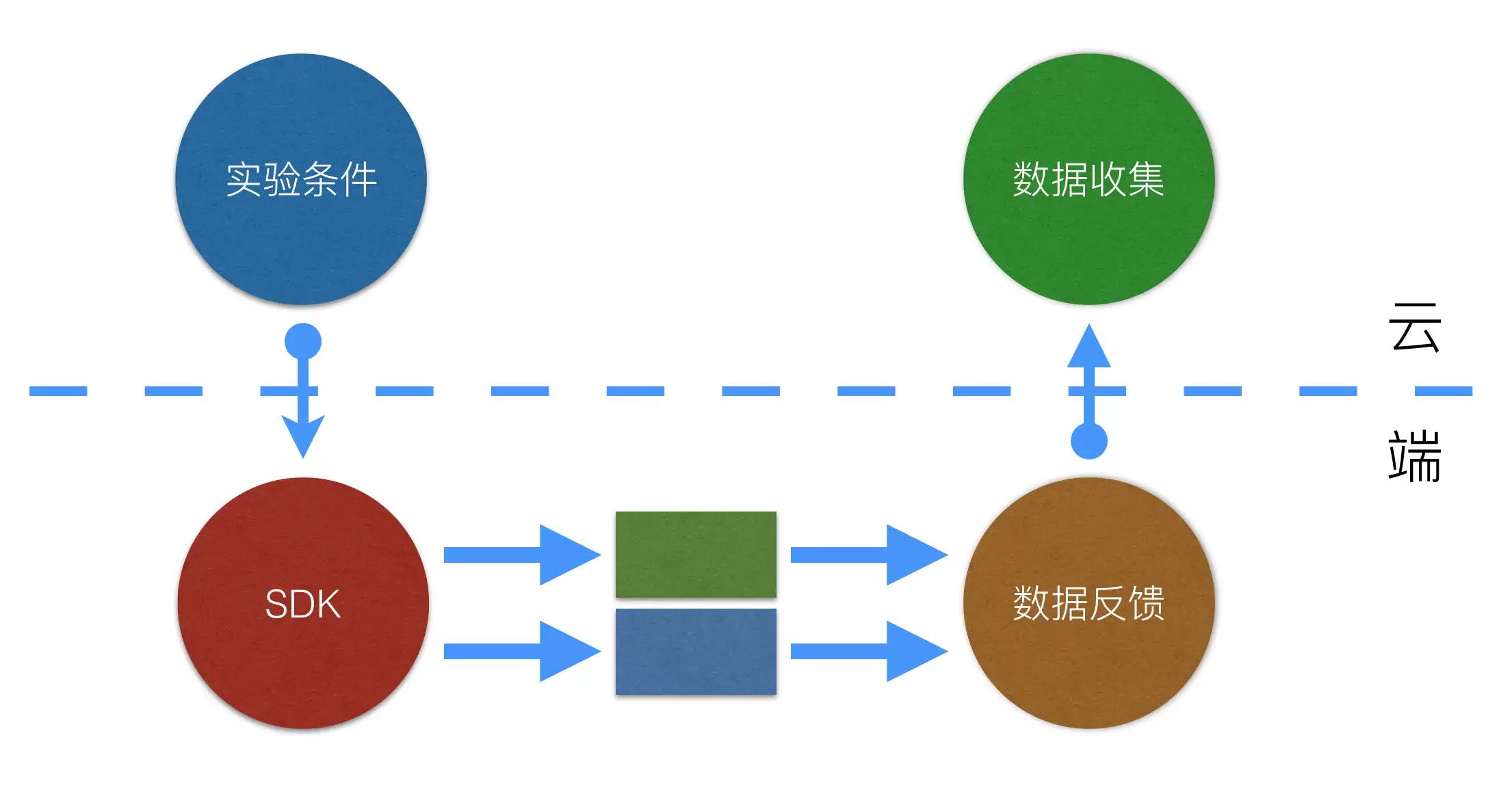
动态实验条件
在传统的Web A/B测试中,实验条件的计算和分桶逻辑执行都在后端完成,具有非常好的动态性,可以随时发布随时生效。在Mobile场景下,很多时候我们惯性的延续这种思路,把这些逻辑放在后端,通过API吐出不同的数据来控制App端的不同形态。这种方式固然有很好的动态性,但一个致命问题在于,这样的设计依赖数据API,只能用于数据层面的实验。
我们认为数据API在Mobile场景中仅仅占一小部分,而我们要建设的是一个代码级别的A/B测试框架,必然不能依赖数据API,而是要具备在端上完成此前后端承担的全部工作。具体的说,就是我们需要在App端实时运算实验条件和执行分桶逻辑。所有的逻辑都在App端,那么动态化的问题怎么解决?幸好我们具有成熟的基础设施建设,可以通过配置中心实现实验条件动态化。
我们把实验条件的数据结构设计为一棵树。根节点是运算起点,非叶子节点是一个逻辑表达式,叶子节点都是实验条件运算的结果。
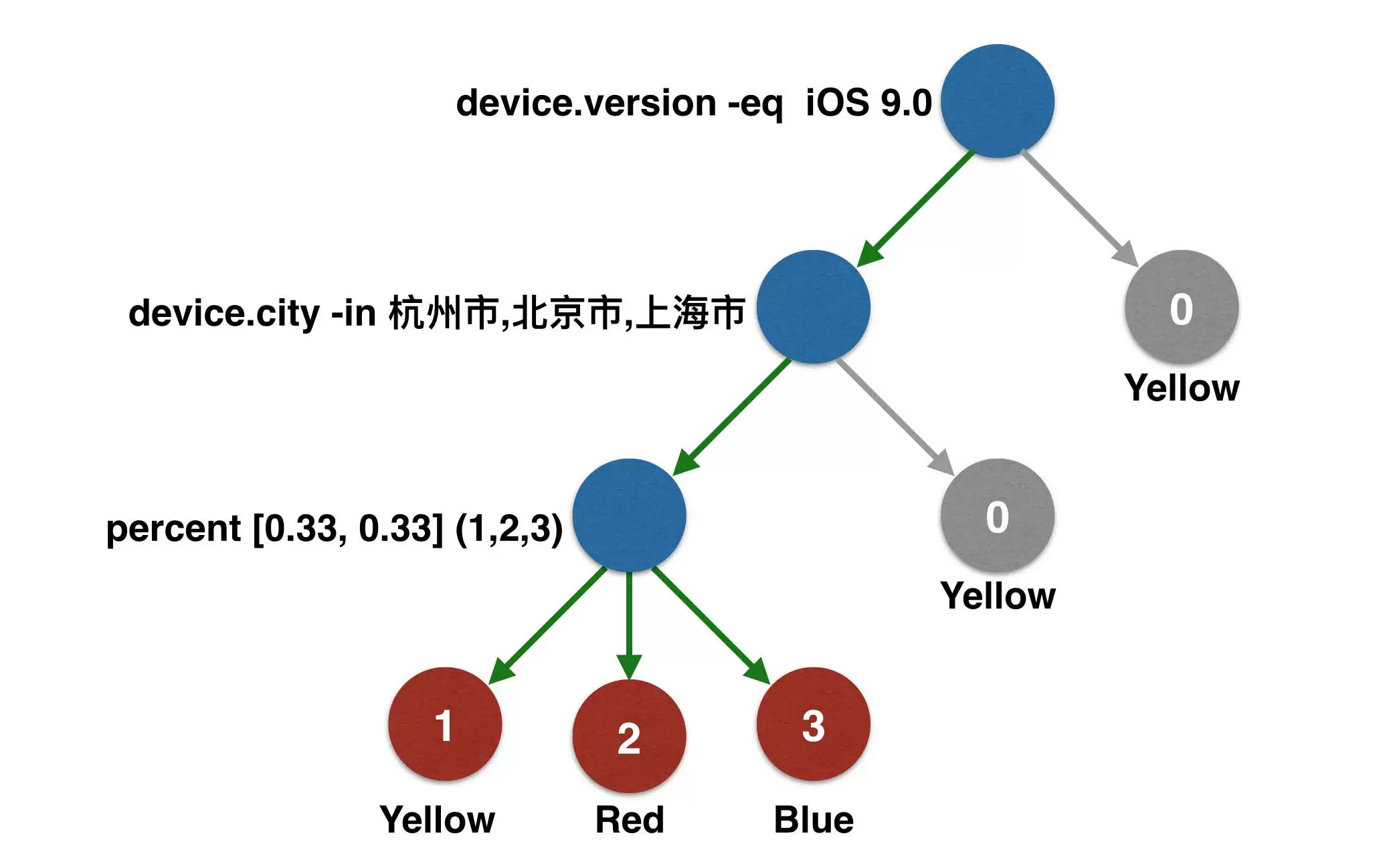
通过一段JSON描述这棵实验条件树,再利用配置中心的动态能力把数据动态下发到端,从而实现了实验条件动态化。
{ "name": "demo", "expired": 1458403200, "tree": {"prop": "device.version","op": "eq","val": "9.0","son": [ {"prop": "device.city","op": "in","val": "杭州市,北京市,上海市","son": [ {"per": [ 0.33, 0.33],"son": [ {"node": 1 }, {"node": 2 }, {"node": 3 }] }] }] }}实时运算SDK
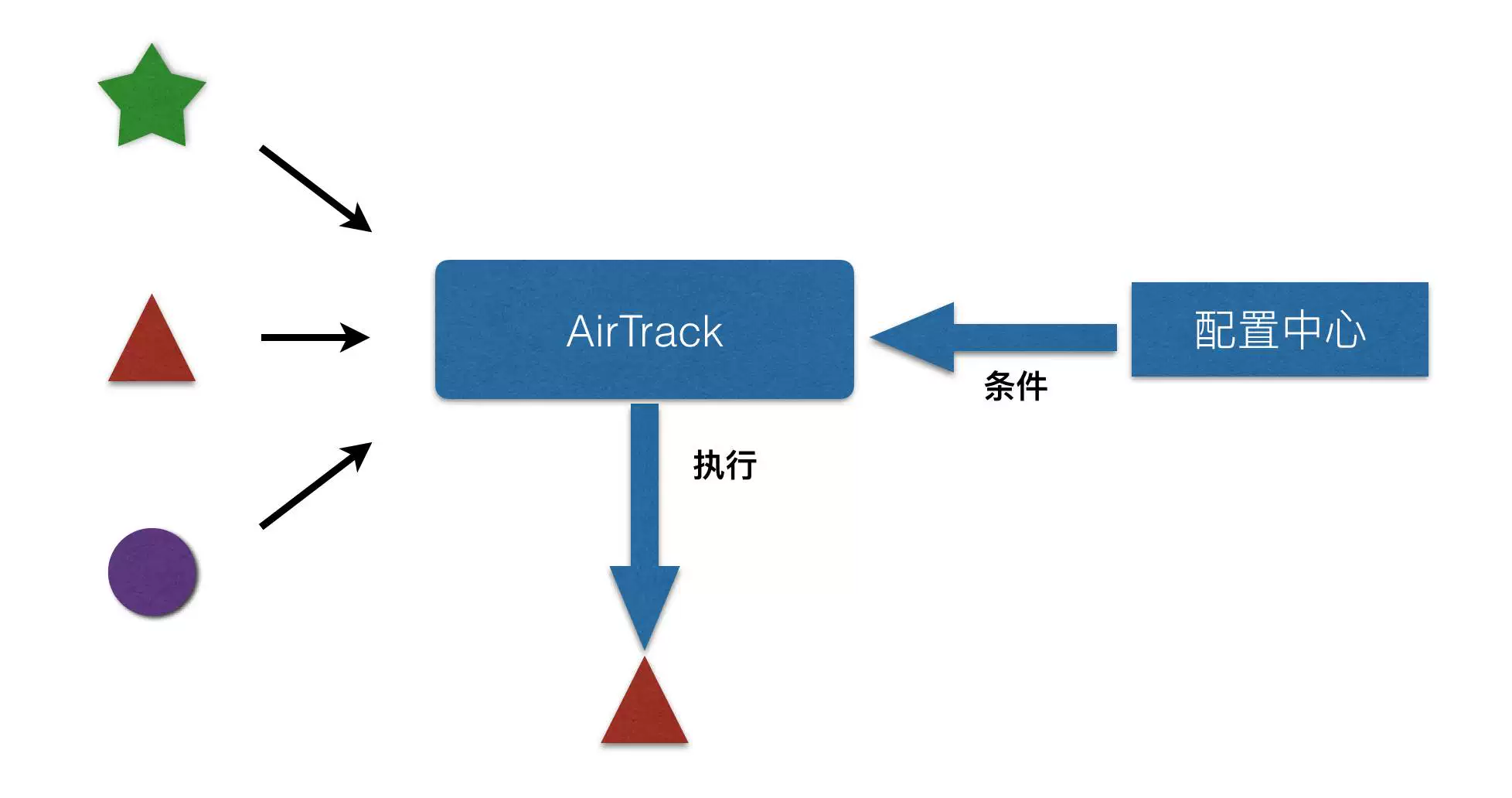
App端的业务代码调用AirTrack SDK,初始化一个AirTrack实例,指定该实例需要进行的实验名称,把需要加入实验的若干逻辑注册到这个实例中。AirTrack实例在执行阶段,根据实验名称,通过配置中心获取实验条件,从条件树的根节点开始计算,最终找到一个叶子节点,通过叶子节点中携带的信息定位到需要执行的实验逻辑,并执行该逻辑。从而完成整个实验过程。
在条件树的Demo中我们可以看到非叶子节点有两种类型
带属性的运算
哈希运算
带属性的运算,利用了天猫状态中心的数据能力,通过条件节点中指定的状态名称获取状态中心中的当前属性值,与给定值进行运算符指定的运算,当运算结果为真,则落入左子树,假,落入右子树。
哈希运算,则是使用设备ID,条件名称和当前节点深度三个因素组合成一个因子,并对该因子进行0-10,000的哈希,通过哈希结果可知当前设备落入那一段区间内。根据给定的子节点和比例关系决定落入哪一棵子树。
数据收集和反馈平台
在天猫App中有一套成熟的数据采集SDK,数据以界面为线索被收集并同步到后端。我们对这个收集SDK进行一些改造,在AirTrack SDK中自动调用数据采集接口,把执行结果的分桶信息写入埋点。
根据数据采集收集的日志,我们有一套完整的以页面为线索的数据分析平台。在这个平台上我们可以看到页面维度的全部信息,除了PV,UV,点击率等常规数据,该页面的入口和出口流量,转化率等等。
而我们对A/B测试数据的要求也正是这些,所以我们对数据分析平台改造支持分桶统计,可以平行看到各个分桶的数据。
实践
配置灰度发布
之前我们说A/B测试的两个主要场景之一是灰度发布,配置中心是一个典型场景。修改一份配置后,需要对这次变更进行灰度发布,以求安全稳定。
我们预先定义若干灰度方案,每一个灰度方案就是一份A/B测试的实验条件。例如,我们有一份实验条件是:
第一个20分钟生效10%
第二个20分钟生效50%
第三个20分钟生效80%
通过1个小时的灰度逐步上线。在灰度过程中,我们可以在数据监控平台上实时发现问题,随时终止灰度进程。如果一切正常,那么这个变更就会自动全量发布。
首页模块对比测试
在天猫App的首页上有很多坑位,我们会在坑位变更中,使用了对比测试方案。
在某次变更中,首先切20%的流量作为样本,把样本五五开,10%执行旧逻辑,10%执行新逻辑,在线上试运行两天。根据反馈的数据显示,我们对比两个坑位的转化率和展示效果,发现新坑位效果并没有达到预期。所以撤回新方案,并实施改造,再次上线对比实验,直至达到预期效果。
在整个决策过程中,花费了1周时间。然而这样的决策在没有试错平台的情况下,需要跨越一个甚至更多个版本。
个性化弹窗
在实施A/B测试的过程中,发现这个平台除了处理以上的两个场景,还可以有更多功能。甚至可以在常规业务中发挥效果。
大家经历过天猫App首页的红包雨,擦雾霾等功能。这是一个独立的弹窗系统支持的,然而这个系统并没有很好的解决在什么条件下出现弹窗这件事。最初的方案只是分时间段弹窗,也就是说,弹窗有一个生效队列,到了某个时间点某个界面一定会弹出某个框。
我们希望弹窗逻辑可以更加聪明,能根据设备和用户信息个性化的出现。这个需求刚好与AirTrack所提供的能力契合,A/B测试并不一定要决定好坏,做出决策,当然也可以支持个性逻辑区分。我们使用AirTrack SDK的配置,把不同的弹窗条件单做桶来看待。通过动态配置AirTrack的分桶逻辑,并指定弹窗桶号来实现了这个个性化弹窗的需求。
以上就是我们在天猫App上最主要的三个实践场景。天猫在A/B测试领域的探索刚刚开始,我们相信随着探索的深入,A/B测试一定可以在App开发和维护中衍生出更加强大的能力,起到越来越重要的作用。