折腾 Python logging 的一些记录
Python 自己有成熟的日志模块 logging,使用中遇到一些原生组件无法满足的功能,或有一些使用方式上的坑,记录一下
0. 复习一下 logging 的实现
Python 官网对 logger flow 的定义如下图(来源 https://docs.python.org/3/howto/logging.html)
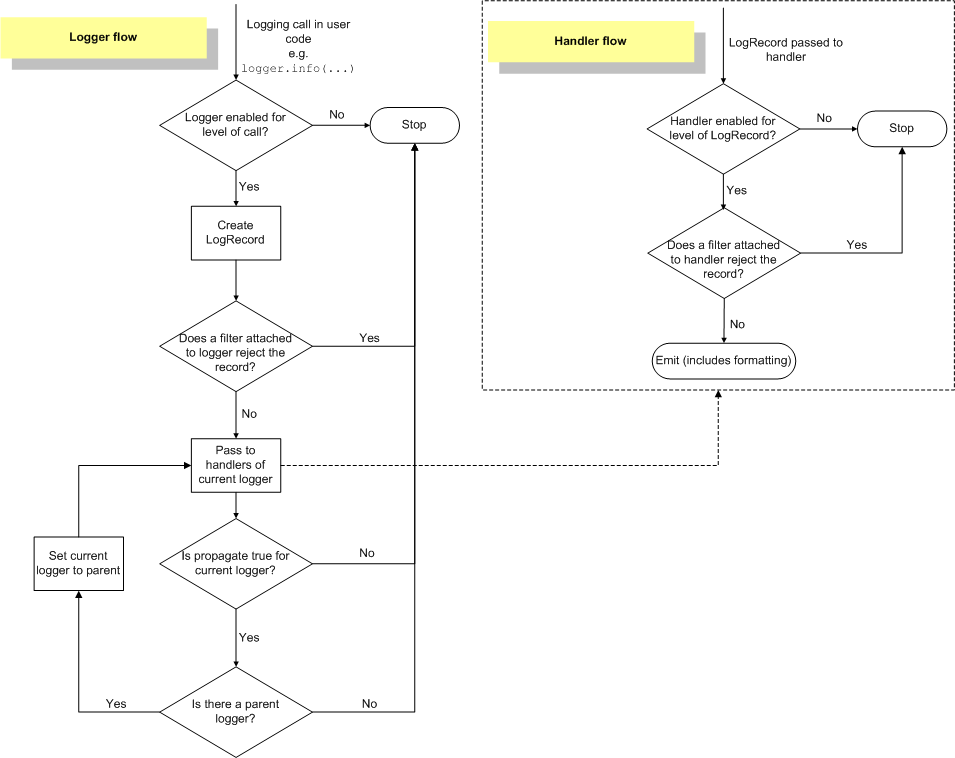
源码在 python 自己的 lib/logging/ 下,主要内容都在 __init__.py 里,先注意下几个定义
Logger,可以挂载若干个Handler,可以挂载若干个Filter,定义要响应的命名空间,和日志级别 (1)Handler,可以挂载一个Formatter,可以挂载若干个Filter,定义了要响应日志级别 (2),和输出方式(流、文件等)Filter,过滤器(其实也可以在里面搞更多事情)Formatter,最终日志的格式化字符串LogRecord,单条日志的结构体,所有信息都会存在这里
然后对着流程图来说,主流程如下
日志打印请求到
Logger后,先判当前Logger是否要处理这个级别,不处理的直接扔掉(级别控制 1)生成一条
LogRecord,会把包括调用来源等信息都一起打包好,传给Logger挂载的Filter挨个过滤如果有
Filter返回是False,则丢弃这条日志否则传给
Logger挂载的Handler挨个处理(右上角子图)如果开启了日志往上传递(
propagate,不知道怎么翻译更精准),则判断当前Logger是否有父Logger,如果有的话,直接将当前LogRecord传给父Logger从 4 开始处理(跳过 1/2/3,注意此处级别控制 1 会不生效,绑定在父Logger上的Filter也不执行)
右上角的子图是 Handler 内部的流程
判当前
Handler是否要处理这个级别,不处理的直接扔掉(级别控制 2)把收到的
LogRecord交给挂载的Filter挨个过滤如果
Filter没有阻止,按挂载的Formatter格式化输出
这里面有一些比较好玩的地方
0.1 LogRecord 的生成
在生成之前其实 Logger 先干了两件事,一是找到原始的调用源(文件名 filename,方法名 funcName,行号 lineno),二是根据参数决定是否需要获取运行信息 exc_info
找原始调用源就是在 Python 的调用栈里一层一层往上找,直到找到调用文件不是当前文件(**/lib/logging/__init__.py)退出。印象中 C/C++ 的日志是直接编译时把当前的 __line__ 什么的展开得到,在 Python 里这么做应该还是因为 Python 是解析性语言。另外可能要注意的是这里的 filename 其实是文件绝对路径,传到 LogRecord 里后会变成 pathname,再分割得到文件名 filename 和模块名 module(这个就是 filename 去掉后缀)
生成好 LogRecord 后还会把传入的 extra 字典也挂上去,这里会限制 extra 里的字段不能和 LogRecord 原生字段冲突,否则会直接报错
0.2 不要被名字骗了的 Filter
从名字上看,Filter 应该就是一个过滤器,对输入的 LogRecord 做判断,返回 True/False 来决定挂载的 Logger 或 Handler 是否要处理当前日志,但是,这个东西不仅可以读 LogRecord,还可以改写,这里就有很多好玩的事情发生了(后面的很多事情都是在这里做的),而且只要被 Filter 改过的 LogRecord,都还会继续往后传递给其他的 Filter/Handler/Logger
0.3 没有被提到过的 adapter
在 Python 官方的 logging Cookbook 里,提到加上下文信息已开始推荐的是用 logging.LoggerAdapter 来做,这个东西其实是对 Logger 多了层封装,多包了一个 extra 字典进去,并且接管了 Logger 的 process 方法,实际用起来这个东西并不好用,所以在前面定义部分没说这个,官方的图也没提这块
0.4 为什么 log 还是要用 % 来格式化
Python 新一点的版本都支持 {} 格式化字符串,到 Python3.6 里更是有 literal template 这种不要太方便的字符串输出,那为什么 log 里还是坚持要用 % 加 args 的方式来处理呢?而且 pylint 等也都会对其他格式化方法报警告
没有太细究,大概想了下可能是因为这一整套 Logger 机制其实不仅仅是 Python 在用,其他语言也有在用,那么保持一致性是一个原因。另外还有查到说法是如果这条日志的等级不需要被处理,或者 Filter 直接就拦掉了,那么就不会走到 Formatter 那一步,可以减少格式化开销,不过这个原因也有站不住脚的地方,如果某条日志确定要被多个 Handler 处理,在用户端格式化就只用做一次,在 Formatter 里格式化就每个 Handler 都要重复做一次了
1. 对 logging 增加功能
1.1 增加相对路径
原生 LogRecord 里只有 filename (文件名)和 pathname (绝对路径),然而 filename 太短,我们可能在不同的目录下都有同名文件,而绝对路径又太长,把一堆有的没的都带上来,所以我们想打印出相对于项目的相对路径
一开始用了各种人肉魔改,包括接管整个 Logger 来自己做,后来发现可以简单加一个 logging.Filter 来解决。前面提到过 Filter 不仅可以过滤决定是否要输出日志,还可以改传入的 LogRecord,这样就很简单了,在我们的 Filter 里,记录下项目的根路径(这个很容易通过当前文件的 __file__ 往上指定层推出来),然后在 LogRecord 添加一个 relpath 的属性,取 LogRecord.pathname 截断掉前面非项目的部分就行了
1.2 自定义的 Filter 进配置
有了自定义 Filter 后,还需要能挂载到对应的 Handler 或 Logger 上
这里略坑的是 logging.config.fileConfig 这样的文件配置并不支持自定义 Filter,只能用 dictConfig。那么配置要么写 Python 变成原生 dict,要么用 json 写,在初始化配置的地方 json.load 读进来变成 dict。从「配置文件归配置文件」的角度说,用 json 会更合适,如果考虑到不同的环境用不同配置,用基类加继承微调的方式,可能写 Python 原生字典会更方便
1.3 保证 Formatter 匹配 Filter
增加的 relpath 可以直接在 Formatter 里用 %(relpath)s 的方式输出,但是这里也得保证,有 relpath 的 Formatter 拿到的一定是被处理过的 LogRecord,不然就崩了
考虑到 Formatter 是一一绑定在 Handler 上的,所以我个人认为比较好的方法是在 Handler 里配置 Filter,保证如果用了自定义字段的 Formatter,一定要加上对应的 Filter,就算这个 Filter 在多个 Handler 上被多次执行,最多增加点性能开销,并不会对结果产生改变
1.4 打印 Flask 请求 ID
对于 Flask 应用,我们希望对一次请求所打的日志能有一个统一的 request_id 把所有日志串起来,方便追查。那么在 Web 请求的 app.before_request 里先加了个 g.request_id,把 request.path 拼上一个随机串记到上下文 g 里,然后在 logging.Filter 里判断是否有 app 上下文,有的话去取这个字段,并追加到 LogRecord 里,后面在 Formatter 里直接写 %(request_id)s 就可以输出了
5. 打印 celery task id
同上,对于异步任务,celery task 自己就有个 request.id 字段,直接判断是否存在上下文,摸出来挂到 LogRecord 上就行了
2. 增加易用性
2.1 log_decorator
很多时候我们希望知道一个方法的入参和返回值,如果在每个需要处理的方法前后都人肉写,未免太不 Pythonic,很自然就想到对方法调用加上装饰器,自动打调用参数和返回结果
对于怎么写装饰器,怎么摸被修饰方法的参数名和值等,之前写的几篇关于 Python 装饰器的 blog 已经写的很详细了,此处不重复
唯一需要注意的是如果不做特殊处理,打印的日志里,文件名、行号、方法都是 log_decorator 里打日志的那行,而不是原始方法。所以在这里需要先摸到原始方法的文件路径、方法名、行号,写到 log 的参数 extra 里用于构建 LogRecord,这里还特别注意因为 MakeRecord 的时候限制了不允许覆盖 LogRecord 已有的字段,所以这里必须改个名字,等到 Filter 里再去尝试看有没有自己加的字段,如果有则替换已有的
我们在实际工程中还对这里做了一些优化,支持传入方法来对入参和返回做处理后输出,特别是对复杂结构很有必要,另外对过长的 tuple/list/set/dict 也做了截断处理
2.2 before_request / after_request
有了 log_decorator 可以对方法的入参和返回很容易记录,那么对于 Web 请求,应该也可以更容易的做调用参数和返回值的记录。对于 Flask 应用,可以在 app 或 blueprint 上往 before_request 和 after_request 里增加打日志的方法来记录入参和返回
此处暂时没有很好解决的是文件路径、方法名和行号还是记录的打日志这个方法里调 log 语句时的数据,并不是最终处理 route 的方法,暂时还没去研究是否有办法可以实现,有 request.path 可以根据路由表去查,其实也还好
2.3 sentryHandler
对于用了 sentry 的项目,除了抛异常,某些时候也希望有一些错误信息能被记录到 sentry 上。最土的方法就是生成一个 raven_client 实例,然后 captureMessage 或 captureException
其实 sentry 有提供 sentryHandler,就是一个 logging.Handler,直接配到 logging 的配置里,挂载到 rootLogger 上,初始化的时候就可以自动挂载上去,后面要用的时候直接 logger.error 打日志就是(什么?你需要只打 sentry 不打 log?你都打 sentry 了这么大的事情都不打条日志?也不是不可以,单独配个 logger 只挂 sentryHandler 就是,但还是不建议这么做)
如果需要打调用信息,在 log 时加上参数 exc_info=True,需要打堆栈就加 extra={"stack": True},比自己人肉搞不知道高到哪里去了
更详细的请见官方文档:https://docs.sentry.io/clients/python/integrations/logging/
3. 关于 Sentry 的补充
3.1 flask to sentry
在 Flask 应用里用 Sentry 可以参考官方文档 https://docs.sentry.io/clients/python/integrations/flask/ ,从 raven.contrib.flask 里 import 一个 Sentry 过来就行,实例化后在 init_app 的时候指定上对应的 sentry_dsn,这样就可以用这个 sentry 实例来 captureMessage 或 captureException
其实这里配置好了更大的意义是在 Flask 应用抛了没有人接的异常时能往 sentry 打异常报告,这个地方一开始我配置好 sentryHandler 到 logging.rootLogger 后得意忘形的把初始化 Sentry 给去掉了,然后就捕获不到异常了,弄明白怎么回事后老老实实加回来,最后异常捕获走 raven.contrib.flask.Sentry,日志走 rootLogger.sentryHandler,各行其是
这里还发现了个特别浪的操作,既然我们在 logging.rootLogger 上已经配好了 sentry_dsn,那是不是就有现成的 raven_client 可以用呢?实际上是可以的… 参考下方代码,初始化的时候直接写 Sentry(app, client) 就行,里面会自动完成 init_app 的操作的
def getRavenClient():
_logger = logging.getLogger('')
for handler in _logger.handlers:
if isinstance(handler, SentryHandler) and handler.client.is_enabled():
return handler.client
return None3.2 celery to sentry
同样,对于 celery 异步任务,也可以参考官方文档 https://docs.sentry.io/clients/python/integrations/celery/ 来配置往 Sentry 打日志或捕获异常,因为我们已经在 logging.rootLogger 上配过 sentryHandler,所以官方文档里的 register_logger_signal 可以忽略,只要从 ravan.contrib.celery 里 import 这个 register_signal 方法并初始化就行,初始化 client 一样可以参考上面从 rootLogger 里去摸
建议继续学习:
- 配置Nginx+uwsgi更方便地部署python应用 (阅读:106241)
- 如何成为Python高手 (阅读:54348)
- python实现自动登录discuz论坛 (阅读:32304)
- python编程细节──遍历dict的两种方法比较 (阅读:19768)
- 每个程序员都应该学习使用Python或Ruby (阅读:17297)
- 30分钟3300%性能提升――python+memcached网页优化小记 (阅读:13108)
- 使用python爬虫抓站的一些技巧总结:进阶篇 (阅读:12752)
- 我的PHP,Python和Ruby之路 (阅读:12612)
- Python处理MP3的歌词和图片 (阅读:9114)
- 关于使用python开发web应用的几个库总结 (阅读:8106)
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:snoopy 来源: 笨狗又一窝
- 标签: logging python
- 发布时间:2019-03-26 09:52:05

-
 [938] WordPress插件开发 -- 在插件使用
[938] WordPress插件开发 -- 在插件使用 -
[119] 解决 nginx 反向代理网页首尾出现神秘字
-
[51] 如何保证一个程序在单台服务器上只有唯一实例(
-
[50] ps 命令常见用法
-
[49] 用 Jquery 模拟 select
-
[49] 整理了一份招PHP高级工程师的面试题
-
[49] 海量小文件存储
-
[48] find命令的一点注意事项
-
[48] Innodb分表太多或者表分区太多,会导致内
-
[47] 全站换域名时利用nginx和javascri
