回归简单,向Django说再见
这篇讲的是作者在基于Django进行Web开发一段时间后,决定“回归简单”,即便这个过程初期可能带来更大的复杂性。文章从作者在微博上分享的一句话出发,深入探讨了现代Web框架中“batteries-included”哲学的双刃剑效应。作者可能结合了具体项目经验,指出Django虽然提供了强大的ORM、管理后台等内置功能,但这些便利在长期维护中反而导致了代码耦合度高、灵活性不足的问题,例如在需要快速迭代或微服务化时,框架的约束会拖累开发节奏。核心观点在于,追求简单并非功能缩减,而是通过精简技术栈(例如转向Flask或自定义轻量级工具),减少不必要的抽象层,从而提升代码的可读性和团队协作效率。文章还可能对比了不同框架的适用场景,强调在启动新项目时,早期选择简单架构虽需更多手动配置,却能为后期扩展预留清晰路径。对读者而言,这启发我们技术决策应着眼于长期维护成本,避免被流行工具绑架,而是根据业务需求灵活权衡复杂性。
对于PHP大型开发框架的看法
这篇是作者对PHP在大型项目中应用前景的思考。文章从PHP如何从中小站点的“好帮手”成长为支撑大型项目的技术力量讲起,核心探讨的是,当应用规模扩大后,开发者在框架选型与架构设计上会面临哪些新的挑战与考量。 作者的观点并非简单对比框架优劣,而是深入到了技术选型的本质:不同的开发范式、对性能与可维护性的不同侧重,将直接影响团队的开发效率与项目的长期健康度。文章可能会触及诸如如何平衡开发速度与运行效率、怎样设计模块以适应业务复杂度增长等实际问题。 对于正在或即将使用PHP构建复杂系统的开发者而言,这篇文章提供了一种超越工具本身的视角——不仅仅是“用什么框架”,更是思考“为什么用以及如何用好”,这对于规划技术栈和组建团队都具备参考价值。
OAuth的改变
这篇讲的是OAuth协议本身的“进化史”。作者从之前那篇概览文章出发,这次一头扎进了版本迭代的细节里,为我们梳理了OAuth从1.0到1.0a,再到2.0的完整演变脉络。 文章的核心在于对比。它没有停留在表面特性,而是深入剖析了每次改变背后的驱动因素:比如1.0a对1.0一个关键安全漏洞的紧急修复;又比如2.0为何要进行一场近乎推倒重来的设计革新,以适应现代Web和移动端的复杂授权场景。作者清晰地解释了每个版本在签名方式、流程和信任模型上的关键差异,并指出了它们各自适用的技术背景。 最让人有收获的是,作者并非简单罗列变更日志,而是像一位向导,带我们看清了协议从“能用但粗糙”到“安全且灵活”的演进逻辑。这有助于开发者理解当下OAuth 2.0规范中许多设计背后的“为什么”,而不仅仅是“怎么用”。
深入研究PHP及Zend Engine的线程安全模型
这篇讲的是作者在阅读PHP源码时的一个具体困惑:那些与线程安全相关的“TSRM”宏究竟在干什么?他没有止步于“按规则使用”,而是选择深入源码一探究竟。 文章首先厘清了PHP中线程安全(ZTS)的基本概念与背景。核心部分则聚焦于PHP线程安全机制TSRM(线程安全资源管理器)的具体实现,剖析了其关键数据结构、实现细节与运行机制。最后,作者还探讨了Zend Engine如何针对单线程与多线程环境进行选择性编译的问题。 作者从一个常见的开发困惑出发,通过源码阅读和资料整理,将相对晦涩的底层机制梳理得清晰可见。对于想理解PHP扩展为何需要特定宏,或对虚拟机内部线程安全设计感兴趣的开发者,这篇文章提供了一次扎实的内部探索。
数据驱动销售――个性化推荐引擎
这篇讲的是电商企业如何利用数据驱动销售增长。在信息爆炸的时代,单纯依靠经验做决策已经行不通了。作者指出,高效处理海量数据并从中挖掘潜在商业价值,正成为电商的核心竞争力。 文章重点聚焦于个性化推荐引擎的构建。它不只是简单地说“要个性化”,而是具体拆解了如何通过算法,将用户行为数据(比如浏览、购买记录)实时转化为精准的推荐结果。核心思路在于建立动态用户画像,并结合实时场景(比如当前购物车、会话行为)进行模型迭代,从而实现“千人千面”的商品推送。 从给出的效果来看,这种数据驱动的方式能显著提升转化率和客单价,将数据分析能力直接转化为实际的销售额增长。它为企业提供了一个从海量数据中提取价值、并快速作用于业务的清晰路径。
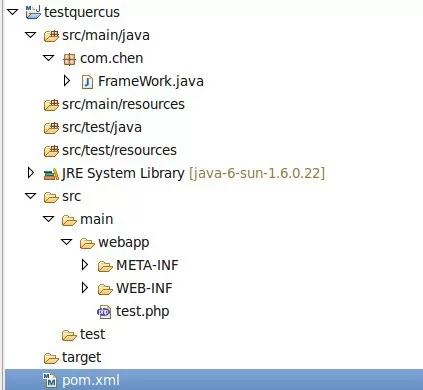
quercus记录:php和java的混合型项目建立手记
这篇文章讲的是创业公司里常见的PHP与Java技术栈之争,以及如何用Quercus搭建一个混合项目来化解这种协作困境。作者从实际团队背景出发——成员技术栈多元、工程师之间互相不太认可——提出了一条务实的技术整合路径。 Quercus作为一个在JVM上运行PHP的引擎,让项目可以同时利用Java的稳定性和生态,以及PHP的灵活与快速迭代。文章手把手记录了从环境搭建到具体配置的混合项目创建过程,比如如何让Java类在PHP代码中被直接调用,如何处理两者之间的数据类型转换等关键步骤。这种整合不是简单地把两套代码放一起,而是通过Quercus这座桥梁,让它们能在同一个运行时里协同工作。 对于面临类似技术融合挑战的团队,这篇手记提供了一种可落地的解决方案。它没有停留在理论对比,而是给出了具体步骤和潜在注意事项,帮助读者评估这种混合架构是否适合自己的场景。
结对编程实践
这篇讲的是结对编程在实际项目中的应用与价值。 作者从一个常见的开发痛点出发:很多程序员习惯抱怨“代码太烂”,却难以具体指出何处需要改进。他坦诚自己也有类似问题,并提出了一个核心观点——个人写出好代码往往是偶然,写得不好却是常态,因此必须借助团队的力量来发现问题。 在项目业务编码临近尾声时,作者没有选择停滞,而是与业务开发人员结对,从测试代码入手展开质量改善工作。他们通过结对协作,相互审查与讨论,共同定位代码中的坏味道,并以此为契机优化业务流程。这不仅仅是一次代码层面的重构,更是一种团队协作模式的实践,将质量改进融入日常开发节奏中。 文章没有停留在理论层面,而是展示了如何将结对编程落地为具体的“代码体检”与协作改进流程,为团队在项目后期如何持续提升代码质量提供了可操作的思路。这种从测试代码切入、以协作为驱动的实践方式,对日常开发中的质量保障有直接的借鉴意义。
软件架构模式的种类
这篇文章直接把常见的软件架构模式摊开来讲,从经典的单体、分层、微服务,到管道过滤器、事件驱动、黑板系统等,几乎覆盖了你在实际项目中会遇到的大部分选择。 作者没有停留在罗列定义,而是着力对比了每种模式的结构特征、核心优缺点。比如,分层架构(Layered)如何通过隔离关注点来简化管理,但又可能因调用链过长影响性能;微服务如何实现高内聚、松耦合和独立部署,却又带来了分布式事务与运维复杂度的挑战。对于像管道过滤器这种在数据处理场景下大放异彩的模式,文章也指出了它并不适合需要复杂状态共享的业务。 最有价值的部分在于,作者从可维护性、可扩展性、团队结构、技术栈等多个维度,给出了一个“架构选择”的思考框架。它提醒读者,没有完美的架构,只有最适合当前业务阶段、团队能力和性能要求的架构。比如,初期项目可能分层架构足矣,而业务爆炸式增长后,拆分微服务才是出路。这种基于具体场景的权衡分析,比单纯知道一种模式是什么要有用得多。
API设计新思维:用流畅接口构造内部DSL
这篇讲的是如何让API设计突破传统思维的局限,探索一种更贴近领域语言、更具表达力的全新方式。作者从实际开发中遇到的痛点出发——传统的API调用往往显得生硬、可读性差,尤其在构建复杂业务逻辑时,代码容易与领域知识脱节。 文章提出的核心方案,是利用流畅接口(Fluent Interface)模式来构造内部的领域特定语言(Internal DSL)。具体来说,通过精心设计的方法链和上下文传递,让API的调用序列本身就能形成一段近乎自然语言的表达。例如,不再是枯燥的函数调用堆砌,而是写出类似“创建用户,设置姓名,关联部门,并保存”这样连贯的指令流。 作者通过对比传统API与流畅接口的代码示例,清晰地展示了后者在可读性、可维护性和业务语义表达上的显著优势。这种设计不仅让代码自身成为了更好的文档,也使得封装复杂操作、减少认知负担成为可能。文章最终落脚于:好的API不应只是功能的暴露,更应是与开发者思维对齐的对话界面,而流畅接口正是实现这一目标的关键工具之一。
Yaf的性能对比测试
这篇讲的是Yaf框架的性能基准测试,作者从自己长期“偷懒”没做横向对比切入,终于补上了这块空白。文章将Yaf与其他主流PHP框架放在相同环境下进行跑分,核心对比集中在启动速度、内存占用和请求处理效率这几个关键指标上。通过具体的测试数据可以看到,Yaf在轻量级场景下展现出显著优势,其C扩展实现的底层设计让它在启动开销上远低于纯PHP框架;但在复杂业务逻辑或需要大量ORM操作的场景中,差异则会缩小。作者也指出,性能并非唯一选型标准,Yaf更适合对吞吐量有极致要求、且团队具备一定C语言调试能力的API网关或微服务项目,而功能丰富的全栈框架可能更适合快速迭代的Web应用。这种基于实测的对比,为技术选型提供了直接的数据参考。
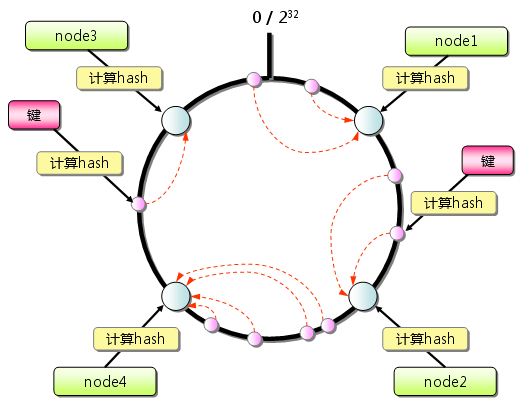
一种以ID特征为依据的数据分片(Sharding)策略
这篇讲的是在分布式系统中如何给数据做分片。作者从一个具体痛点出发:用雪花算法生成的ID虽然全局唯一,但它们自带时间属性。如果简单地按ID范围或时间范围做分库分表,很容易导致数据分布不均,最新的请求和数据会集中打在同一个分片上,形成热点。 文章提出的核心策略是“以ID特征为依据”。它深入分析了雪花ID的二进制结构——其中包含了时间位、自增位和机器位。方案的关键思路不是直接利用时间位,而是巧妙地利用了每台机器在毫秒内生成的自增序列位。通过对ID进行位运算或取模,将数据相对均匀地分散到各个分片中。这样即使ID有时间趋势,实际的写入压力也能被有效打散。 这种策略的结论很直接:它在不引入复杂路由算法的前提下,实现了数据的均匀分布,有效避免了热点问题,同时保留了ID本身的有序性。对于使用雪花ID且面临分片压力的系统,这提供了一种直接、高效的优化思路。
【外刊IT评论网】关于node.js语言的讨论
这篇讲的是Node.js被调侃为"Node on nails"(服务器上的Node)背后的技术现实与常见误解。作者并没有从语法细节入手,而是直接切入其核心运行模型——单线程事件循环。 文章剖析了Node.js如何通过非阻塞I/O处理高并发请求,同时也坦率指出其瓶颈所在:一旦遭遇CPU密集型计算,单线程模型会立刻成为性能的"钉子"。作者用具体场景说明,比如图像处理或加密操作,这类任务会阻塞整个事件循环,拖慢所有请求的响应。 核心观点在于,Node.js的威力与其限制同源。它天生适合I/O密集型的网络应用,能用较少资源支撑惊人吞吐量;但若用错地方,比如硬扛重计算任务,其表现反而不如传统多线程语言。这篇讨论为开发者提供了清晰的选型边界:理解工具的特性,才能把它用在真正合适的地方。
关于自动分裂的思考
这篇讲的是分布式系统中自动分裂技术的实践思考。作者从自动分裂、自动迁移和负载均衡这三个常被一起讨论的技术点出发,指出它们共同支撑着系统的可扩展性与性能。文章特别提到,像 Google 的 BigTable 和 Yahoo 的 PNUTS 这类知名系统都实现了自动分裂功能,这也曾让作者认为它应是优秀分布式系统的“标配”。 不过,文章并未止步于介绍概念。作者结合自身经验,分享了对自动分裂实际价值的反思:它虽能带来扩展性,但其复杂性和潜在的运维成本是否始终值得?在何种场景下,它才是真正的必需品而非“过度设计”?这种从“理所当然”到“审慎评估”的视角转变,为技术选型提供了更务实的参考。
记录碰到的HBase问题
这篇笔记记录了作者在实际生产环境中遇到的几个HBase典型问题。其中一个重点案例是关于Region热点:业务在写入时使用了时间戳作为RowKey前缀,导致大量写入集中在少数几个Region上,引起服务器负载不均。作者通过分析日志和监控数据定位到问题,最终调整了RowKey的设计策略,采用了加盐或反转等方法来散列写入流量,使集群负载恢复了均衡。另一个案例则涉及到了频繁的Major Compaction导致的I/O飙升,作者通过调整compaction策略和HDFS参数有效缓解了压力。 文章没有停留在现象描述,而是深入到了问题的根因分析和解决过程,包含了具体的操作步骤和参数调整思路。对于正在使用或即将使用HBase的开发者来说,这些来自一线的踩坑经验能帮助提前规避类似陷阱,或者在遇到问题时快速找到排查方向。
函数式编程很难,这正是你要学习它的原因
这篇讲的是函数式编程虽然以“难”著称,但这种难度恰恰构成了它的核心价值。作者从实际开发中的痛点切入,指出命令式编程容易让代码陷入状态管理的泥沼,导致bug频发且难以维护。而函数式编程通过强调“纯函数”和“不可变性”等原则,迫使开发者用更清晰、更可预测的方式构建程序。 文章进一步阐释,学习函数式编程的“难”,主要在于它需要一种思维范式的转变——从描述“如何做”转向定义“是什么”。这种转变虽然一开始会让人感到不适,但一旦掌握,就能从根本上提升代码的健壮性和可维护性。作者用购物清单作为生动类比,说明了声明式思维如何让逻辑更聚焦于本质。 因此,作者的结论并非让我们在所有场景都使用函数式编程,而是鼓励开发者将这种思维融入工具箱。它提供的不仅是一套语法,更是一种应对复杂系统的、更可靠的思考方式,最终让写出正确代码的过程变得更轻松。
用YAML构建数据测试DAO层
这篇讲的是如何给枯燥低效的DAO层测试“减负”。作者从开发者日常的痛点出发:测试DAO层时,总得手动拼装数据、调用方法、再肉眼核对数据库状态,这套流程繁琐又容易出错。 文章提出了一种更优雅的思路:将测试数据用YAML格式集中管理。通过预先定义好符合结构的测试数据配置,测试时程序可以自动加载这些数据并执行验证,从而用配置化、可复现的方式替代重复的人工操作。 核心方案在于将测试数据与测试逻辑解耦。YAML文件清晰描述了测试场景下的数据状态,让测试用例本身更聚焦于行为的验证。这种方法不仅能显著提升测试编写与执行的效率,也使得测试数据更易于维护和复用,确实能达到事半功倍的效果。
Varnish VS Nginx测试报告
这篇技术博客直接深入了 Varnish 和 Nginx 在性能测试中的正面对决。文章并非泛泛而谈,而是从具体的配置环境出发,对两者在高并发下的响应速度、吞吐量以及资源消耗进行了细致测量。 测试结果清晰地揭示了二者的核心差异:Varnish 在处理纯静态缓存时,因其高效的内存管理和 HTTP 协议优化,表现出了惊人的冷启动效率和极高的缓存命中率;而 Nginx 则凭借其更为平衡的资源占用(尤其是更低的 CPU 消耗)和强大的动态内容处理能力,在复杂的应用场景下展现出更高的通用性与稳定性。 文章特别分析了在长时间压力测试下两者的内存表现,Varnish 的优势窗口与 Nginx 的平稳曲线形成了对比。结论并非简单地判定孰优孰劣,而是指出:对于需要极致缓存性能的 CDN 或静态资源分发场景,Varnish 是利器;而对于需要兼顾动态代理、负载均衡和静态缓存的 Web 服务器或反向代理角色,Nginx 往往是更务实的选择。这篇报告为不同技术选型提供了清晰、数据驱动的参考。
深入浅出REST
这篇文章从REST的起源和设计哲学讲起,深入解析了这种架构风格的核心约束:资源标识、统一接口、无状态和分层系统。作者通过对比传统RPC与RESTful API的设计差异,清晰指出了后者如何通过资源、URI和HTTP方法来构建更优雅、可扩展的Web服务。 文中特别拆解了REST常见的“误用”场景,例如过度设计、忽视超媒体控制(HATEOAS)等,并用电商订单接口的演进案例,具体说明了如何从简单CRUD升级到符合REST原则的版本化设计。对于想真正理解REST精髓而不仅仅是模仿其表面形式的开发者来说,这篇梳理了从理论到实践路径的文章,提供了一份清晰的路线图。
为什么我喜欢Lisp语言
这篇讲的是作者对Lisp语言的一份深厚偏爱。文章没有停留在“函数式”或“递归”这些常见标签上,而是直接切入了作者的个人体验与技术洞察。 他从Lisp语言独特的语法结构——即“代码即数据”的S-expression表示法讲起,并认为这种同像性并非晦涩的古老特性,而是构建抽象和元编程时无比强大的工具。作者很可能对比了Lisp在领域特定语言(DSL)创建上的天然优势,与一些现代语言需要复杂框架才能实现类似效果的情况。 文章的观点核心在于,Lisp给予开发者的不是某种具体功能,而是一种“自由度”。这种自由度允许程序员以最贴合问题本身的方式去塑造代码,而不是被迫适应语言强加的范式。作者通过Lisp的宏系统等细节,说明了这种自由如何将编程从“写指令”提升到“设计语法”的层面。 读下来,这篇文章不只是在介绍一门语言,更是在分享一种编程哲学:选择工具时,我们真正选择的是它所倡导的思考方式。对于那些对语言设计和编程本质感到好奇的技术人,作者的这份私人体验或许能带来新的启发。
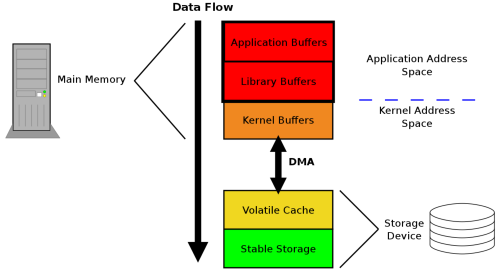
确保数据存入磁盘
这篇讲的是如何在系统设计中确保数据可靠地持久化到磁盘,避免因崩溃或异常导致的数据丢失问题。作者从常见的数据持久化挑战出发,指出许多应用场景——如数据库事务、缓存更新或分布式存储——中,数据仅保存在内存中可能因断电或进程终止而丢失。核心方案围绕操作系统级的`fsync`调用、数据库预写日志(WAL)以及分布式复制策略展开,详细对比了这些方法在可靠性与性能上的权衡。 文章具体分析了高并发环境下,异步写入结合定期同步的优化思路,强调在追求吞吐量的同时不能牺牲数据安全。例如,通过实际案例展示了忽略磁盘写入可能引发的生产事故,如订单数据丢失或日志不一致。作者还探讨了在微服务架构中,如何利用消息队列和持久化层来增强系统的容错能力。结论指出,提前在架构设计中嵌入数据持久化考量,能有效降低后期维护成本,并提升整体系统稳定性。