Oracle+Fusionio+Dataguard的高可用方案
这篇文章指出了一个老问题:Oracle的高可用和容灾往往被割裂开来。传统上,无论是双机主备还是RAC,都离不开一套共享的SAN存储,架构复杂且成本高。而DataGuard虽好,但在作为高可用方案时却面临切换不透明、数据可能丢失,以及早期版本只读无法写等现实窘境。 为了解决这些痛点,作者探讨了一种融合架构:Oracle + Fusionio + DataGuard。其核心思路是利用Fusionio提供的高性能PCIe闪存,替代传统的后端SAN存储。这样一来,数据库可以部署在本地高速闪存上,从而为DataGuard的角色切换提供了更快、更透明的基础。这个组合方案旨在打破对共享存储的依赖,让DataGuard不仅能用于容灾,也能更顺畅地承担高可用切换的任务,在性能与业务连续性之间找到一个更好的平衡点。
我为什么选择MongoDB
这篇讲的是作者在2008年前后对早期NoSQL数据库的一次思考与取舍。当时NoSQL概念很火,作者关注了如Hypertable、CouchDB等受Google Bigtable启发而诞生的项目,但并未深入跟进。 核心观点在于,这些项目的设计目标过于宏大,试图解决超大规模数据问题,而这在国内绝大多数项目中并不会遇到。更现实的障碍是迁移成本高,因为团队的核心技术栈建立在MySQL+Memcached之上,业务逻辑中充斥着关系型操作,而早期的Key-Value或类Key-Value数据库对此并不友好。作者认为,很难从这些产品中获得性能或开发效率上明确、可预期的收益。 这段经历其实揭示了技术选型中的一个关键:不能盲目追随热点或“终极解决方案”,而必须紧扣自身业务的实际数据规模、架构现状与团队成本。这篇文章正是从这个务实的视角,铺垫了作者后续对更实用、更契合关系型操作习惯的数据库(如MongoDB)的选择逻辑。
leveldb性能分析和表现
这篇深入剖析了LevelDB在海量数据下的性能表现,核心聚焦于其高效背后的LSM(Log-Structured Merge)算法设计。作者从LevelDB支持billion级数据量这一事实切入,揭示了其卓越吞吐能力的根本原因:LSM算法巧妙地将随机写入操作转化为顺序写入,通过后台合并(Compaction)过程持续优化数据结构,从而在数据量剧增时依然保持稳定的读写性能。 文章具体分析了这一机制的工作流程与优势。LSM树利用内存中的MemTable缓冲最新写入,当达到阈值后刷入磁盘形成不可变的SSTable文件,并定期进行多层合并。这种设计极大地减少了磁盘寻址开销,是高并发写入场景下的性能利器。同时,作者也提及了LevelDB在压缩(如使用Snappy)和缓存(如Block Cache)等方面的优化,这些共同构成了其高性能的整体方案。 对于正在设计存储系统或寻找高性能KV解决方案的开发者而言,理解LevelDB的这些实现细节具有直接的参考价值。它展示了如何通过架构创新来平衡存储成本与访问速度,尤其是在写密集型负载下的权衡艺术。
ZooKeeper解惑
这篇讲的是ZooKeeper客户端与集群交互的深层机制,作者从官方文档未明说的细节出发,基于源码拆解了连接建立、Session管理、ACL鉴权与Watcher重新注册的核心流程。 文章详细剖析了一个ZooKeeper对象如何启动线程打乱顺序连接服务器,Session的ID如何通过Leader的Server ID与时间戳保证唯一性,以及password的生成与校验竟巧妙地依赖随机数种子——Server并不保存密码,重连时用相同算法重新计算比对。在ACL部分,清晰解释了`digest`、`ip`、`auth`等内置Scheme的工作原理,并点明`CREATOR_ALL_ACL`在早期版本失效的根因。关于Watcher,还阐述了连接中断时如何通过`setWatches`包将未触发的监听器带到新连接上,保障了事件通知的连续性。 这些源于源码的洞察,对于理解ZooKeeper在分布式环境下的可靠性设计,以及排查连接、权限相关的问题,提供了非常扎实的内部视角。
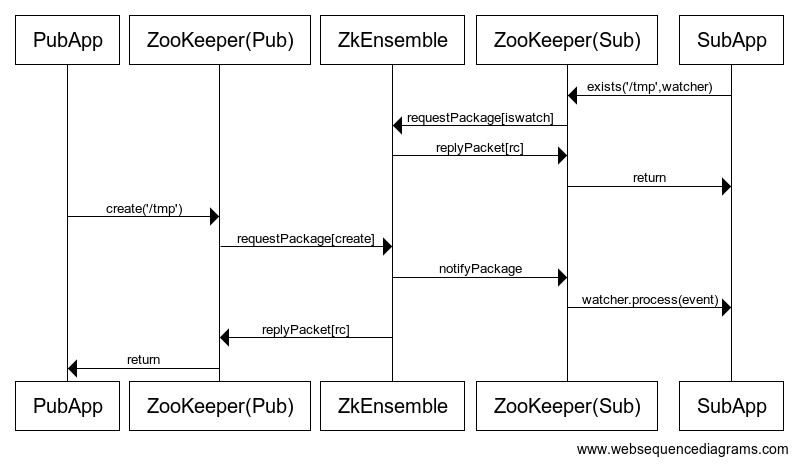
一个典型支付系统的设计与实现
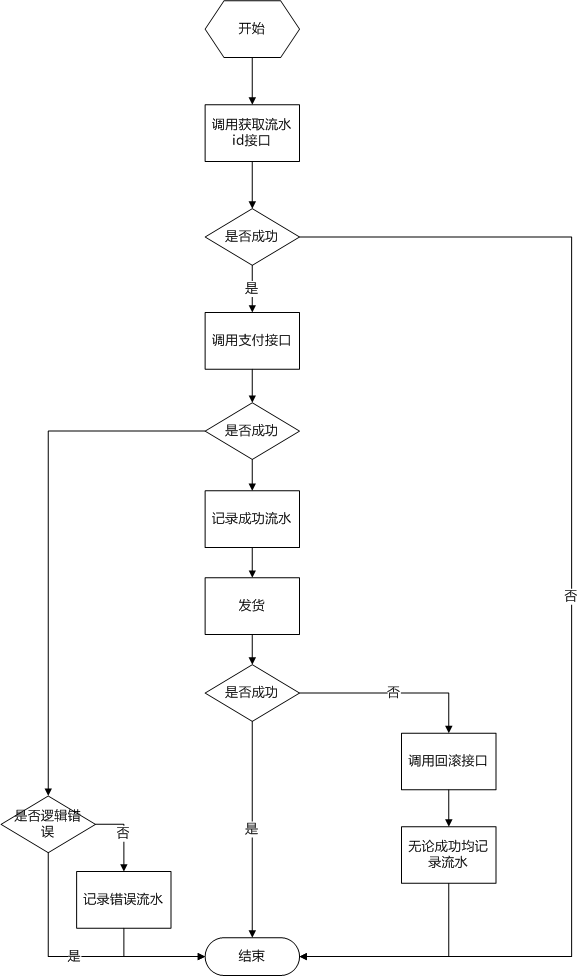
作者从实际业务需求出发,分享了一个在两周内从零实现的小型支付系统的设计与实践。文章坦言,网上的支付系统资料多偏重理论研究,因此作者将这套“麻雀虽小,五脏俱全”的系统完整地呈现出来,它既能作为轻量级支付系统使用,也适合作为第三方应用接入时的支付流水层。 系统的核心在于一个清晰务实的数据库设计。作者详细列出了包括账户状态、余额、流水、价格和应用锁在内的六张关键表结构,并解释了每张表字段的设计意图,比如用bigint存储分单位的金额以避免浮点数精度问题,以及利用seqid序列号来应对并发。 实现上,文章重点剖析了支付操作和账户锁定两个典型场景。支付流程被拆解为发起方与系统内部的两层逻辑,并附有清晰的流程图。系统采用了“先写入流水,再更新账户”的稳健策略以最大限度保证数据不丢失。同时,针对不同类型的返回码(如逻辑错误与系统错误),给出了明确的流水记录建议。账户锁定则直接利用了数据库的行级锁机制。整个系统设计紧扣事务性保证与对账等核心需求,是一次对小型支付系统关键模块的完整实践复盘。
日本的 Perl 项目 CloudForecast 分布样式监控系统
这篇讲的是一个日本开发者用Perl实现的分布式监控系统CloudForecast。作者从观察日本开源项目的共享文化出发,提到自己很早就接触过这个项目,认为它代表了日本Perl社区扎实的技术水平与乐于分享的精神。 文章的核心观点在于对比——作者感慨这类质量不错的项目在日本能被开源共享,而类似的中国项目却常常被“放在家中烂掉”。CloudForecast本身是一个专注于监控系统“样式”的工具,主要解决分布式环境下如何统一直观地呈现系统状态的问题,其设计思路在早期云运维场景中颇具前瞻性。 虽然文章没有深入技术细节,但作者通过推荐这个相对冷门的项目,传达了对技术共享生态的思考。这种视角或许能启发我们:一个项目的影响力不仅取决于代码本身,还在于它能否被看见、被传播,从而激发更多协作与改进。
微格式:让网页更加语义化
这篇讲的是如何用微格式给网页“注入语义”。作者从现有的HTML标准出发,指出微格式不是另起炉灶的一套新规范,而是在XHTML标签上增加特定属性,像给内容打上语义标签。 这些属性让机器能理解信息的结构——比如一段内容是人名、日期还是地址——同时对不识别它们的浏览器或工具完全无害,实现了向后兼容。这巧妙地在不破坏现有Web生态的前提下,提升了数据的机器可读性。 微格式的核心价值在于它的“轻量”和“务实”。它不需要改变底层框架,只需在书写网页时遵循一些简单约定,就能让内容同时服务于人和机器,为分离式开发提供了便利。对于希望提升网页语义化但又担心技术债务的开发者来说,这种渐进式的增强方案提供了一个平滑且有效的切入点。
一种oracle2hdfs的数据推送思路
这篇讲的是作者在迁移旧应用时,重新翻出了一个自己以前编写的、用于将Oracle数据库数据同步到Hadoop HDFS的程序,并决定将其核心思路分享出来。 文章聚焦于一个具体的数据同步场景:如何稳定地将传统关系型数据库(Oracle)中的数据,批量或增量地推送到大数据平台(HDFS)上。作者没有空谈理论,而是基于自己生产环境中的实践,梳理了从数据源读取、可能的数据转换到最终写入HDFS的具体技术路径。分享的重点在于实现的思路和架构考虑,比如如何处理两边数据结构的差异,以及如何保证数据推送的可靠性。 对于正在面临类似数据集成需求,尤其是需要将OLTP数据导入数据湖或离线数仓的团队来说,这种直接来自实践的一线经验,提供了比通用文档更具体的参考价值。
几个HIVE的streaming
作者分享了在实际项目(JIS旺铺装修数据开发)中,因Hive原生功能不足而编写四个Python Streaming的实战案例。每个案例都针对一个具体的数据处理痛点,提供了可直接复用或修改的代码示例。 文章逐一拆解了这四个脚本的核心逻辑:前两个用于处理流式数据中的“前序”与“后序”输出,基于分组和特定标志位(flag)进行行级过滤;第三个实现了十进制到三十六进制的转换函数;第四个则相对复杂,处理行内字段拼接与跨行分组聚合,并包含了时间戳格式化等细节。 这些实现的关键在于巧妙地利用了Streaming脚本对标准输入的逐行处理能力,通过维护状态(如前序ID、分组标识)来完成Hive SQL较难表达的序列逻辑。代码虽短,却展现了将复杂数据操作拆解为流式处理步骤的清晰思路,对于有类似数据清洗、序列归并需求的开发者很有参考价值。
Redis内存存储结构分析
这篇讲的是 Redis 如何在内存中巧妙组织其核心数据结构。作者深入剖析了 Redis 为不同数据类型设计的多种底层编码,例如字符串的 SDS、列表的 quicklist、哈希和集合的 ziplist/hashtable 以及有序集合的 ziplist/skiplist。 文章的核心亮点在于,它清晰地揭示了 Redis 是如何根据数据的规模和元素类型,动态、智能地选择最优的底层存储方案。这种设计并非一成不变,而是精妙地在时间效率与空间利用率之间寻求最佳平衡点。例如,当集合元素是整数且数量不多时使用 intset 以节省内存;而当数据量增大或元素类型复杂时,则无缝切换到 hashtable 以保证 O(1) 的操作性能。 通过这种从应用层编码到底层内存布局的垂直剖析,文章让读者不仅能知道 Redis “怎么用”,更能理解它“为什么这么设计”。这对于进行高性能内存优化或排查复杂内存问题的工程师来说,提供了至关重要的底层视角。
Microsoft Azure Storage架构分析
这篇讲的是 Microsoft 云存储服务的底层架构选择。作者从 Azure Storage 与 SQL Azure 的服务定位差异入手,剖析了云存储系统设计中一个核心的权衡:可扩展性与传统关系型功能之间的取舍。文章指出,要实现海量数据的弹性扩展,就必须对 SQL 数据库的强一致性、复杂事务等特性做出让步。 核心分析围绕 Azure Storage 的具体实现展开。它并非一个单一系统,而是将数据存储拆分为 Blob、Table、Queue 等不同服务,各自针对特定场景优化。例如,Table 存储虽名为“表”,却采用了键值对和最终一致性的设计,这牺牲了部分查询能力,却换来了近乎无限的横向扩展能力。文章详细拆解了这两种实现思路(例如分区、复制策略)是如何服务于此架构目标的。 最终,作者不仅解释了“是什么”,更阐明了“为什么”。这篇分析的价值在于,它清晰地揭示了现代云存储服务背后的设计哲学:没有普适的最佳方案,只有针对特定场景(如高吞吐、海量对象存储 vs. 事务处理)的明智权衡。对于正在设计系统或进行技术选型的开发者而言,理解这种权衡逻辑比记住某个具体产品的参数更有意义。
抵制代码重写
这篇讲的是,当开发者面对一个逐渐臃肿、难以维护的遗留系统时,“推倒重写”往往是一个极具诱惑力的选项。作者从大量实际项目经验出发,剖析了这种诱惑背后的陷阱。 他指出,重写项目常被乐观地估计,却极易陷入无限循环的泥潭:新系统需要实现旧系统里所有已知甚至未知的业务逻辑,而这些逻辑往往已无文档,只存在于少数资深员工的脑中或陈旧代码的缝隙里。这个过程不仅耗费巨大,还可能丢失关键的隐性知识,导致新系统反而不如旧系统稳定。 文章的核心观点是:除非系统已彻底腐化到无法维护,否则应首先考虑“抵制重写”的冲动。作者主张,更稳妥的路径是采取渐进式重构,在持续交付价值的同时,一步步改善代码质量与架构。这对于维护关键业务的系统尤为重要,因为稳定性与可预测性远胜于一次高风险的重置。
淘宝2011彩票首页开发实践
这篇讲的是,面对一个需要从旧版平稳过渡到新版的首页,淘宝彩票团队如何设计和实施他们的发布策略。他们没有选择直接替换,而是采用了“新旧版并行”的方案。 核心思路是,让新版首页作为一个可选版本,仅通过老版首页中的一个链接入口进行小范围暴露。这种做法背后有两个明确目标:一是为用户提供足够的缓冲期,避免突然变更带来的不适应;二是以此为机会,收集真实的用户反馈和数据,用于打磨和优化产品,使其更贴近用户实际需求。 从实践效果看,这种渐进式的发布策略,为产品的迭代上线提供了宝贵的缓冲空间和数据支撑,是一种稳健且注重用户体验的工程化实践。
浅析手机消息推送设计
这篇讲的是手机消息推送的设计思路。作者从消息的核心作用切入——主动提醒用户新内容,无需反复刷新应用。文章特别指出,像早期Android版微博那种必须手动刷新才能获取更新的做法,在移动网络环境下既消耗流量,也影响效率,对包月用户尤其不友好。 消息推送则解决了这个问题。它允许用户在专注于当前任务时,被动接收来自其他应用的提醒,比如短信、邮件、日程安排或社交申请。这种机制的本质是化被动检查为主动通知,既节省了不必要的网络请求,也使得多任务并行处理成为可能,让用户不会错过重要信息。 整体来看,文章没有深入到具体技术协议,而是从用户体验和资源效率的角度,阐明了消息推送这一功能设计的必要性与基本价值。
各消息队列软件产品大比拼
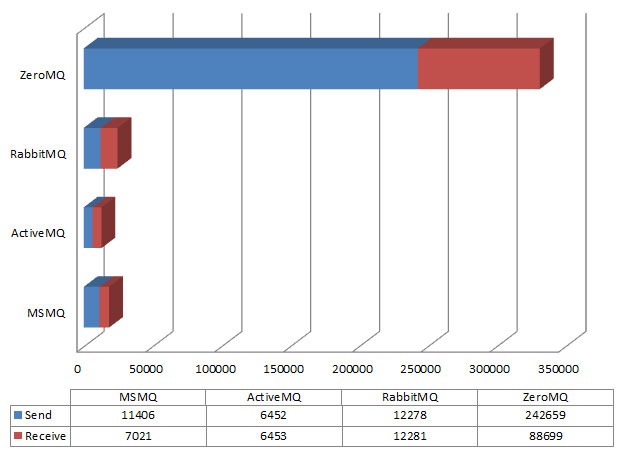
这篇译文聚焦于对 RabbitMQ、ActiveMQ、HornetQ、Kestrel 和 Redis 这五款主流消息队列软件的性能评测。作者将它们置于相同硬件和网络条件下,设计了一系列基准测试,旨在量化对比它们在吞吐量、消息延迟、持久化能力等关键维度的表现。 文章的核心结论清晰而实用:在追求极高吞吐量的场景下,基于内存的 Redis 或 Kestrel 表现突出;当消息的持久化和可靠性成为首要需求时,ActiveMQ 和 RabbitMQ 则更为稳健;而 HornetQ 在两者间取得了不错的平衡。这些结论并非空谈,而是基于大量图表数据的实证分析得出。 对于正在为技术栈选型而困惑的团队,这篇文章提供了一份宝贵的“横评报告”。它不仅展示了各产品的性能上限,更指出了它们各自最擅长的应用场景,能帮助开发者根据业务对性能、可靠性、协议支持等方面的具体要求,做出更贴合实际的技术决策。
用一堆Gem来架起你的Rails3机枪
这篇讲的是如何利用Ruby生态系统中现成的Gem(库)来快速、高效地构建一个功能完善的Rails 3应用,核心思路正如文中那句“好程序员写代码,伟大的程序员复用代码”。 作者从“避免重复造轮子”这一经典原则出发,聚焦于Rails 3项目的实战场景。文章并非泛泛而谈,而是具体展示了一系列Gem的选型与集成策略,例如哪些Gem负责用户认证、哪些管理后台、哪些处理文件上传。作者像一位熟练的指挥官,将这些独立的“组件”通过配置和少量胶水代码整合起来,最终让项目能像“架起机枪”一样,以模块化的方式快速实现功能,同时保持架构的清晰与可维护性。 其巧妙之处在于,作者没有停留在列举工具,而是传达了一种开发哲学:在Rails这样约定优于配置的框架下,主动拥抱和组合社区的最佳实践(即这些Gem),能让你把精力集中在最核心的业务逻辑上,而非基础功能的重复建设。文章最终导向一个结论:在Rails开发中,高效复用与合理选型,是构建可靠应用的关键加速器。
PHP在金山游戏运营中的应用
这篇讲的是金山游戏团队如何使用PHP高效支撑其官网与运营系统的技术实践。文章从一个实际问题切入:多开发者在Windows上编码,但测试和生产环境却在Linux,导致调试缓慢且易冲突。 作者分享了他们的核心解决方案。在团队协作上,他们利用Nginx与PHP分离的架构,让开发者在Windows本地修改代码,直接调用Linux服务器的PHP环境进行调试,并通过SVN钩子与优化后的自动同步脚本实现代码的快速集成与版本控制。为此他们还开发了XDevelop工具,一键配置这套跨平台开发环境。 在系统架构与运维方面,文章介绍了多项关键设计。为解决多环境配置难题,他们开发了专用PHP扩展与管理后台,统一了代码在不同环境下的配置。发布流程被封装成一个带版本管理和一键回滚功能的代码发布系统,并将发布权下放给项目负责人。在架构上,采用Nginx负载均衡与服务器集群池应对高并发,并对论坛、抢购等突发流量大的业务进行独立分组隔离。此外,他们通过将HTML缓存上移至Nginx层、使用Memcached进行Session共享,以及在php-cgi中增加预判断机制来防范代码篡改等措施,保障了系统的高性能与安全性。 整篇文章并非泛泛而谈,而是结合具体的开发工具、代码示例和架构图,详细复现了从开发调试到上线运维的全流程优化,展现了PHP在大规模游戏运营场景下的工程化落地经验。
Facebook 的系统架构
这篇讲的是 Facebook 为了支撑十亿级用户、应对海量数据和实现极致发布效率,如何设计其底层系统架构。文章从一个核心矛盾切入:既要保证全球服务的高可用性和低延迟,又要让数千名工程师能像在初创公司一样快速迭代代码。 作者重点剖析了几个关键设计。为了解决单体应用的瓶颈,Facebook 采用了深度定制化的微服务架构,将用户信息、动态消息、聊天等功能拆分为独立服务。数据存储上,他们为不同类型的数据选择了最合适的技术:关系型数据库 MySQL 经过分片和主从复制来处理核心社交图谱,而像 News Feed 这样的大规模写入场景则依赖自研的 TAO 缓存层和 Cassandra 等 NoSQL 系统。 最巧妙的部分在于其部署文化。文章提到,Facebook 采用了基于 Mercurial 的大型代码仓库和持续部署流水线,工程师的代码提交在通过自动化测试后,可以极快地推送到全球服务器,甚至实现了“一键回滚”。这套架构不仅解决了规模问题,更重要的是将“快速试错”这一互联网基因深深植入了基础设施之中,使其能始终适应业务的快速演变。
理解云计算
这篇讲的是云计算的三大核心分类——SaaS、PaaS和IaaS,帮助读者快速厘清这个热门概念的技术框架。 作者从当前云计算热潮的背景切入,指出许多公司正纷纷涌入这个领域。文章没有停留在泛泛而谈,而是直接将云计算拆解为三个清晰的层次:软件即服务(SaaS)、平台即服务(PaaS)和基础设施即服务(IaaS)。这三者构成了云计算服务的主体,分别对应着从直接使用软件、到开发部署平台、再到租用底层计算资源的不同粒度。 理解这种分层是关键。简单来说,SaaS让你直接使用云端软件,无需关心底层;PaaS为你提供开发和运行应用的环境;而IaaS则提供最基础的计算、存储和网络资源,灵活性最高但也最需要管理能力。这篇短文就像一张路线图,为初学者指明了进入云计算世界的起点,帮助他们在众多技术讨论中先建立正确的认知坐标。
模拟HTML表单上传文件(RFC 1867)
这篇讲的是HTTP文件上传中一个被广泛使用却常被忽略的标准——RFC 1867。作者从常见的开发困惑出发:当需要上传多个文件或附带额外信息时,很多人的第一反应是将文件二进制流转化为文本(比如Base64)再作为普通字段传递。这种方式虽然能用,但代价不小:Base64编码会让数据体积直接膨胀三分之一,效率不高。 更合理的做法是遵循互联网上已有的成熟协议。RFC 1867正是为解决HTML表单文件上传而生的标准,它定义了如何在POST请求中结构化地封装文件流与元数据,这正是我们日常使用 `` 时背后的工作原理。文章具体剖析了这种协议化方式相比“土办法”的优势:更高效的数据封装、更清晰的结构,以及对多文件场景的原生支持。 对于需要构建文件上传接口的开发者而言,这篇文章清晰地指明了一条路径:与其重复造轮子,不如深入理解并运用现有的RFC标准。它不仅解决了具体的效率与规范性问题,也提醒我们去挖掘HTTP协议中那些为特定场景精心设计的解决方案。