linux下cp,mv进行动态库覆盖问题分析
这篇讲的是一个生产环境中典型的“隐形地雷”:明明只是想更新一个动态库文件(.so),为什么用 cp 命令覆盖后,正在运行的程序就莫名崩溃了?作者从一次周会讨论的问题出发,抽丝剥茧地分析了这个现象的深层原因。 文章先厘清了 Linux 文件系统的两个关键概念:inode 存储文件元数据,dentry 建立文件名到 inode 的映射。核心分析由此展开:cp 和 mv 操作对正在被进程使用的文件影响截然不同。cp 命令本质是“打开目标文件并截断,然后写入新数据”,这个截断操作会通知内核释放该文件在内存中的所有页面映射。当程序再次执行到该库的代码时,会触发缺页中断,但因为原文件数据块已失效,内核无法正确填充内存,于是导致总线错误(bus error)或段错误(segment fault)。相比之下,mv 命令仅仅是重命名操作,只改变了目录项(dentry)的指向,并未影响文件本身(inode)及其内存映射,因此是安全的。 文章通过 strace 跟踪和进程内存映射的视角,清晰展示了故障现场。结论很明确:对于已被进程动态链接的库文件,在线更新的正确姿势是 mv(将新文件重命名为原名),而不是 cp。

DNSv6和DNS64简单配置
这篇讲的是如何在Linux系统上配置IPv6环境下的DNS服务,特别是DNSv6和DNS64功能。作者从上一篇DHCPv6的部署延伸出来,直指DNS作为互联网入口在IPv6时代的重要性。 文章以Bind服务为例,给出了清晰的实操路径。它从最简单的源码安装开始,然后聚焦于核心配置:如何让DNS监听IPv6地址(`listen-on-v6`指令是关键),并配置了测试用的IPv6地址段。配置过程还包括了关闭防火墙、设置SELinux等便于测试的准备工作,同时提醒线上环境需合理配置安全策略。 最终,文章提供了一个精简的主配置文件(`/etc/named.conf`)示例,让读者能快速抓住启用IPv6 DNS服务的配置要点。整体而言,这是一篇步骤明确、重点突出的配置指南,适合需要快速上手IPv6 DNS服务搭建的运维人员参考。
Intel 10-GbE 网卡性能优化[翻译]
这篇翻译文档详细拆解了如何将一块 10GbE 网卡的性能从默认的“可用”状态压榨到“极限”。作者指出,Linux 的默认网络栈配置(如缓冲区大小、TCP 内存分配)是为了可靠性而非峰值吞吐量设计的,这对万兆网卡尤其不利。 文章的核心思路是分层优化,并基于 Intel 官方驱动文档提供了实操步骤。优先级最高的操作是在交换机和服务器两端启用巨型帧(MTU 9000),这能大幅提升大流量传输效率。其次是调整内核的 `sysctl` 参数,例如关闭 SACK 和时间戳、将 TCP 收发缓冲区统一设为 10MB,并提高网络设备积压队列上限。更进阶的操作是通过 `setpci` 命令调整网卡 PCI-X 总线的 MMRBC 寄存器,将内存读块大小提升到 4KB,以增强对突发流量的处理能力。 文章最有说服力的部分在于其测试数据:经过上述优化,使用 `iperf` 测试的吞吐量从优化前的约 4.70 Gbits/sec 飙升至 9.90 Gbits/sec,几乎跑满了万兆带宽。作者强调,优化过程需配合压力测试(如 iperf、netperf)来验证效果,结果可能因硬件和网络环境而异。对于需要榨干网卡性能的 HDFS、高性能计算等场景,这套调优方法提供了清晰的参考路径。
加速scp传输速度
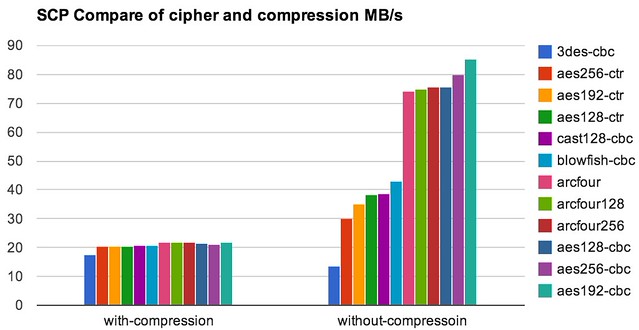
这篇讲的是如何突破scp文件传输的速度瓶颈。作者在实际场景中发现,默认配置下传输400GB文件耗时太长,于是系统性地测试了加密算法、压缩选项和完整性校验算法对速度的影响。 测试数据表明,选择更轻量的加密算法(如arcfour128、aes192-cbc)能显著提速,通常“越弱”的算法速度越快。有趣的是,启用ssh内置压缩反而常常拖慢速度,因为压缩本身消耗了时间,除非传输的是可压缩率极高的数据。此外,使用umac-64这类校验算法也比默认的hmac-md5带来约10%-20%的性能提升。 基于这些发现,作者建议直接尝试类似 `scp -c arcfour128 -o "MACs umac-64@openssh.com"` 的命令组合,往往能让传输速度翻倍。文章提醒,最终效果高度依赖数据类型和网络环境,关键在于根据实际情况做针对性调优。
Linux如何统计进程的CPU利用率
想在脚本里“非阻塞”地获取Linux进程CPU利用率,却遇到top需要等1秒、ps只显示平均值的问题?这篇文章就从这个实际需求出发,直接深入到/proc文件系统,带你看清背后的原理。 文章的核心是对比两种思路:使用现成工具vs手动计算。作者明确指出,像top和ps这样的工具,虽然方便,但本质上提供了不同的“快照”——ps给出的是进程生命周期的平均利用率,而top需要至少1秒的采样间隔。关键差异在于,它们都无法满足对“当前时刻”瞬时利用率的精确、非阻塞获取。 真正的解决方案隐藏在/proc/stat和/proc/[pid]/stat这两个文件中。文章详细拆解了其中各列的含义,并给出了具体的计算公式:在两个时间点分别读取系统总CPU时间片和进程CPU时间片,通过差值比来计算这段时间内的利用率。这就像用两张“照片”的位移差来算速度,揭示了CPU利用率本质是一个时间段内的统计量,而非一个瞬时值。 最后,文章还解释了ps命令中%CPU指标的准确含义,即它是进程自启动以来的累计平均利用率。如果你需要在监控脚本中实现高精度的进程CPU统计,或者对系统工具背后的实现原理感到好奇,这篇文章提供的思路和细节会很有参考价值。
记录一个软中断问题
这篇讲的是如何定位并解决Linux系统软中断负载不均的“坑”。作者从一台XEN虚拟机的Nginx服务器入手,通过top命令观察到软中断(si)数值异常,且几乎全部集中在CPU1上,导致该CPU成为性能瓶颈。 进一步用`/proc/softirqs`确认,网络收包中断(NET_RX)是主要来源。排查发现,问题根源在于宿主机的网卡运行在单队列模式,且中断被绑定到了特定CPU上。虽然尝试修改中断亲缘性(`smp_affinity`),但对单队列网卡无效。 最终,作者启用了Linux内核的RPS(Receive Packet Steering)功能,通过软件层面将网络包处理负载分摊到多个CPU核心。配置后,软中断成功从单一CPU分散到了两个CPU上,显著改善了负载不均的问题。 文章还附带介绍了`itop`这个中断监控小工具,并提及了Nginx的`worker_cpu_affinity`配置、NUMA架构调优等后续优化思路,为遇到类似网络中断瓶颈的开发者提供了一套完整的排查与优化路径。
MogileFS 复制不正常,发现文件少于指定的份数解决方法
这篇文章聚焦于一个MogileFS部署中的棘手故障:安装最新版后文件复制功能异常,副本数始终无法达到设定值。作者通过telnet监控发现replicate进程不断报错退出,日志显示“Child died: 256 (UNEXPECTED)”。 经过深度调试,作者定位到根本原因:Perl的Sys::Syscall模块升级至0.25版本后与新版MogileFS存在兼容性问题,导致底层复制操作失败。文章给出了明确的排查与解决路径:首先使用命令检查模块版本,确认是否为0.25;若是,则通过CPAN回退安装稳定的0.23版本即可恢复正常复制功能。此外,文章还补充提醒了最新客户端对数据库密码的硬性要求。 这是一次典型的、由依赖库升级引发的隐蔽故障排查记录。作者不仅详细描述了故障现象,更关键的是找到了那个“不兼容的精确版本”,并给出了可立即操作的修复命令,为同样遇到此问题的开发者节省了大量排错时间。
代码审查不是用来……
这篇文章讲的是代码审查在实践中常被误用的几个典型姿势。作者从自己公司的长期实践出发,总结了四个容易让代码审查变味的陷阱。 首先,别把代码审查当成控制代码的流程关卡。在团队内部,信任比强制审批更重要,流于形式的审查只会引发抵触。其次,它不该是追究责任的审判厅,揪出某个审查者来背锅会彻底摧毁团队的信任。第三,不要将其变为程序员必须完成的枯燥任务,这会扼杀其作为学习与交流机会的乐趣。最后,对代码的批评应当对事不对人,避免演变成互相讽刺的人身攻击。 文章指出,代码审查的真正价值在于促进学习、获得反馈与团队交流。作者通过具体场景描述了这些误区如何发生,旨在提醒团队避开这些坑,让审查回归提升代码质量与团队协作的正途。

Bash的模式和配置文件加载
这篇讲的是Bash启动时如何加载配置文件的“冷知识”,作者坦言自己早年也一知半解,于是从`man`手册出发,把这个绕人的机制捋清楚了。核心在于理解运行中的Bash有两种“模式”:交互式(是否直接与终端对话)和登录式(是否作为用户登录会话的起点)。两者独立组合,决定了启动时加载哪些文件。 文章清晰列出了加载路径:登录Shell会依次尝试`/etc/profile`、`~/.bash_profile`等;而交互式非登录Shell则主要加载`~/.bashrc`。这些规则直接解释了日常中的两个典型困惑:为什么在`crontab`里配置的环境变量常常不生效?因为非交互、非登录的Shell压根不会加载这些配置文件。同样,为什么在Mac终端里修改`~/.bashrc`没反应?因为它的终端默认启动的是登录Shell(`$0`以`-`开头),本应配置`~/.bash_profile`,而不像某些Linux发行版那样在`~/.profile`里隐式地加载了`~/.bashrc`。 搞清楚这个加载逻辑,就能精准定位Shell脚本的环境问题,无论是定时任务还是跨平台开发。作者用亲身踩坑的例子把这份“手册知识”讲得生动实用,帮读者建立起正确的心智模型。
使用 lsyncd 同步本地和远程目录
这篇讲的是如何解决文件同步的实时性与服务器资源消耗之间的矛盾。作者从常见的 rsync + cron 方案切入,指出其“定时轮询”的固有局限——间隔设得太短则频繁启动 rsync 增加负担,设得太长则同步不及时。 文章的核心方案是引入基于 Linux inotify 事件驱动的 lsyncd 工具。它不同于 cron 的定时执行,而是像一位尽职的哨兵,持续监测本地目录的变动。一旦捕捉到文件或目录的变更事件(默认触发条件是每20秒或累积1000次写入),便立即触发 rsync 或 rsync+ssh 进行精准同步。这种“按需启动”的模式,从根本上避免了无谓的资源消耗。 作者用清晰的步骤,演示了从安装、手动创建配置目录,到编写 Lua 配置文件(重点指明 source、host、targetdir 三个参数)和设置无密码 SSH 登录的全过程。配置完成后,lsyncd 服务启动即可自动守护同步任务。 最终,文章指出通过简单修改配置文件(将远程同步改为本地目录同步),lsyncd 同样能胜任本地目录镜像备份的任务,提供了灵活的文件同步选项。
Git subtree 要不要使用 –squash 参数
这篇讲的是,作者在使用 Git subtree 管理多层代码包含关系时,遇到了一个持续困扰的冲突问题,并深入分析了 --squash 参数背后的机制与应对策略。 作者从实际项目(Gregarius 管理 MagpieRSS,后者又管理 Snoopy)出发,指出使用 subtree 的 --squash 参数虽然能让主项目提交历史更清爽,却会在后续更新(subtree pull)时,反复引发需要手动解决的冲突。反之,不用 --squash 虽然更新顺畅,但子项目的历史会“污染”主项目。 文章清晰地剖析了根因:--squash 会合并并消除子项目的历史提交,导致下次合并时 Git 找不到共同的父提交,从而无法自动处理冲突。作者引用并评估了 StackOverflow 上的一种平衡方案:在一个专用分支上进行不带 --squash 的更新以保留历史、避免冲突,然后在合并到主分支时使用 `git merge --squash` 将其压缩为一个简洁的提交。 文章最后总结了两种典型的使用场景:如果只是单向接收子项目更新,任选一种方式均可;如果是拆分大项目(如 Symfony2),则建议避免 squash,主项目主导开发再 split 出子项目发布。作者的实践表明,专用分支方案虽然略增复杂度,但能有效兼顾提交历史的整洁与更新的顺畅。
Git log diff config高级进阶
这篇文章从一个已有的《更好的git log》分享出发,延续了Git效率提升的主题,重点聚焦于git log、git diff、git blame和git config这四个常用命令的深度配置与使用。 作者系统梳理了它们的进阶用法:对于git log,可以结合`--oneline`、`--stat`、`--graph`和`--pretty=format`等参数,实现从单行简洁显示、文件变更统计到图形化分支历史的多种视图,并支持按精确时间区间进行筛选。git diff部分则扩展了比较范围的灵活性,不仅能对比HEAD、特定提交(HEAD^)或不同分支,甚至能结合时间参数进行比较。git blame命令被用来追溯文件的每一行修改历史。 文章的亮点在于将重心引向了git config。它清晰地解释了Git配置的三层优先级体系(系统级、全局用户级、项目级),并详细演示了如何通过全局配置进行个性化定制:从基础的用户信息、终端颜色渲染(支持对diff、status等不同命令设置不同配色方案),到利用alias功能创建如`git mylog`和`git lol`这样的自定义快捷命令。最终,所有这些技巧都指向一个实用目标:通过精心配置,让Git这套强大的工具在日常工作中变得更顺手、更高效。
【翻译】用 elasticsearch 和 elasticsearch 为数十亿次客户搜索提供服务
这篇讲的是邮件服务商 Mailgun 如何为数百万客户提供对每月数十亿封邮件事件的实时搜索与分析。面对原有日志 API 的功能短板,他们构建了基于 Elasticsearch 和 Logstash 的新后端。 核心方案是将所有邮件事件(如发送、拒绝、打开等)通过 Logstash 从 Redis 接入,存入 Elasticsearch 集群,从而提供灵活的字段过滤与全文搜索。文章详细分享了几个关键实践:为满足不同账户的数据保留需求,他们设计了灵活的索引轮转策略;为了处理复杂的事件数据结构,他们定义了详细的自定义 mapping,并巧妙运用了 not_analyzed 属性和多字段类型来优化查询与聚合统计。 此外,文章还介绍了如何通过一个名为 Vulcan 的双层代理来解决 Elasticsearch 原生缺乏的认证问题,以及如何利用 Graphite 和自研的 Vör 工具监控集群状态。整个方案最终让 Mailgun 控制面板拥有了强大的实时日志分析能力。
在LVS上实现SNAT网关
这篇技术文章详细记录了作者为LVS负载均衡器添加SNAT网关功能的实战过程。目标很明确:让LVS在承担4层反向代理的同时,还能为内网机器提供访问外网的能力。 作者先分析了常规方案的局限——使用iptables虽能实现SNAT,但会严重影响LVS性能。因此,他决定直接修改LVS源代码。文章核心梳理了两种实现路径:一是修复小米已有的dsnat项目,使其兼容NAT和FULLNAT转发模式;二是在官方内核的NAT模式上,以最小改动直接添加SNAT功能,无需依赖额外的FULLNAT补丁。 实现过程颇具细节:从获取内核源码、打补丁、编译调试,到使用tcpdump抓包分析,作者逐步解决了dsnat与原生NAT的兼容性bug,以及其与FULLNAT的配置冲突。最终产出的补丁和配置示例,为有类似需求的读者提供了可直接参考的完整方案。文章也坦诚指出了当前实现的局限,如暂不支持ICMP协议转发。
使用 SysRq 键安全重启挂起的 Linux
这篇讲的是,当一台 Linux 服务器(比如 NFS 文件服务器)完全卡死——能 ping 通但无法通过 SSH 或本地终端登录时,在万不得已需要重启前,如何避免数据丢失和文件系统损坏。 问题的根源在于,Linux 为了性能会将大量数据暂存在内存缓存中,而非实时写入磁盘。如果此时强制断电重启,这些尚未落盘的数据就会丢失,导致不一致或损坏。文章的解决方法是利用 Linux 内核的“Magic SysRq”机制。这个机制很特别,它工作在系统服务层之下,只要系统还能响应键盘中断,就能通过一组特定的按键组合执行底层操作。 作者详细介绍了标准的安全重启序列:Alt + SysRq + R-E-I-S-U-B。这六个字母并非随意组合,而是一套严谨的操作流程:先让键盘进入原始模式(R),然后温和地终止除初始化进程外的所有进程(E、I),接着将内存缓冲区强制同步到磁盘(S),再将文件系统重新挂载为只读(U),最后安全重启(B)。每一步之间还需留出适当的等待时间。 对于紧急情况,文章也给出了一个实用简化版:通常只用 Alt + SysRq + S(同步磁盘)和 Alt + SysRq + B(重启)。在按下 S 键并看到同步完成的提示后,再按 B 键,就能在数据安全的前提下完成重启。这确实是在系统看似完全无解时,一个能挽救数据和系统的关键技巧。
系统自动化配置和管理工具 SaltStack
作者从团队实际运维经验出发,对比了Puppet、Fabric与SaltStack这几款工具。他指出,Puppet擅长系统初始化和配置管理,而Fabric更适合执行批量临时任务,二者功能有别。但如果选择SaltStack,则可以统一覆盖两者功能,从而减轻工具链的复杂度和人力、时间成本。 文章重点介绍了SaltStack的核心优势:它采用ZeroMQ消息队列,通信速度远超Puppet/Chef;整个工具由Python编写,对Python技术栈的团队更友好,更接近其“能力圈”。它通过Salt Master(主控)和Salt Minion(受控)的架构进行集中管理与下发。 随后,文章详细演示了从安装到使用的关键步骤,包括在Ubuntu/CentOS上部署主控与客户端、建立信任关系,并通过命令行示例展示了如何快速执行远程命令。更重要的是,它展示了如何通过定义状态文件(.sls)来实现类似Puppet的配置管理功能,例如自动安装软件包(vim、Glances)并管理配置文件,真正实现了“一键式”的状态强制执行。 这种将配置管理与任务执行融合的“一专多能”工具选型思路,对需要简化技术栈的团队应该很有启发。

如何的退出无响应的 SSH 连接
这篇讲的是SSH连接卡死时的优雅退出方法。作者从日常工作中遇到的实际烦恼出发——离开电脑后,未退出的SSH会话常常悬在那里,既无法操作也无法中断,以往只能粗暴地关闭终端或手动寻找进程并终止。尤其对于没有图形界面的环境,这种重复性操作令人十分头疼。 文章的核心在于一个简单却鲜为人知的技巧:在无响应的SSH会话中,输入波浪符加句点(`~.`)即可立即断开连接。作者通过查阅`man ssh`手册确认了这一“转义字符”的功能,它被列为支持的断开连接命令。这个发现解决了长期困扰他的问题,提供了一种无需依赖窗口关闭或额外终端来杀进程的、直接且“优雅”的解决方案。 这个方法虽然基础,但对于经常使用SSH的开发者和运维人员来说非常实用,能有效节省时间并提升终端操作体验。
深入理解 GRE tunnel
这篇讲的是 GRE 隧道,作者从一个常见误区出发:很多人以为 GRE 和 SIT、IPIP 一样是端到端的隧道,其实根本不是。核心差异在于,GRE 隧道不是建立在通信的主机上,而是建立在中间的路由器上,这对端点主机完全透明。 文章通过对比 SIT 隧道(包在出入口主机封装解封)和 GRE 隧道(由路由器负责封装解封)的原理图,清晰揭示了这一关键设计。这种设计让 GRE 解决了 IPIP 无法处理的多播等问题。随后,作者深入 Linux 内核,剖析了 GRE 隧道的实现:发送时路由将包导向隧道设备,内核添加外部 IP 头;接收时内核先识别 GRE 协议,交给 `ipgre_rcv()` 函数剥去外层头,再像普通 IP 包一样处理。 理解 GRE 是中间节点而非端点的特性,是掌握其工作原理和应用场景的关键。这篇文章从原理到内核实现,把这一点讲透了。
让进程在后台可靠运行的几种方法
这篇讲的是如何在 SSH 断开或终端关闭后,让进程继续可靠运行的经典方法。文章从一个常见痛点出发:在远程执行耗时任务时,网络波动或误关终端会导致任务中断。作者围绕如何规避 HUP(挂断)信号,对比了多种解决方案。 核心方法包括:最常用的 `nohup`,让进程忽略 HUP 信号;使用 `setsid` 或 `(cmd &)` subshell 技巧,让进程在新会话中运行,从而脱离原终端。文章特别指出了一个关键差异:`nohup` 启动的进程父进程仍是原终端,而 `setsid` 启动的进程父进程会变为 init(PID=1),从根源上隔绝了信号影响。 对于已经提交的任务,文章也介绍了补救措施:通过 `Ctrl-Z` 挂起、`bg` 后台运行,最后用 `disown` 命令将其移出作业表,使其不再受 HUP 信号影响。这些方法各有简单的操作示例,非常适合临时任务或未预先规划的场景。 总的来说,文章系统梳理了从预防到补救的完整工具链,帮助你在不同情境下灵活选择,确保关键进程不会意外中断。
DRBD远程实时双机热备系统配置完全手册
这篇文章详细记录了作者重新搭建并配置DRBD远程实时双机热备系统的全过程。出发点很简单:几年前配过的环境已无法使用,于是决定完整走一遍流程,并将每一步骤记录分享。 内容以两台虚拟机为基础环境,从安装Linux系统、配置网络,到添加虚拟硬盘并分区作为镜像源,再到DRBD软件的安装与关键的配置文件(drbd.conf)编写,形成了一个清晰的操作链条。作者不仅给出了具体命令和系统输出,还穿插了如提前创建虚拟机快照等实用经验提示。 整个过程不空谈原理,而是通过一个实际可复现的案例,展示了如何构建一个数据实时同步的节点对。对于想了解或动手实践DRBD部署的读者,这篇手册提供了一个从零开始、步骤完整的配置蓝图,能够帮助读者快速建立对DRBD基础部署流程的认知。