区块链将会如何影响开源
这篇文章探讨的是区块链技术可能为开源社区带来的范式变革。 文章从开源当前的协作与商业模式入手,指出了一个核心痛点:开源生态中,价值(尤其是资金激励)在开发者与用户之间的传递往往是间接且单向的。虽然商业化公司和基金会扮演了重要的中介角色,但许多有潜力的项目仍因无法形成有效的价值交换而难以维系。 作者的核心观点是,区块链和智能合约能为开源引入一种新的、去中心化的激励与治理模型。通过代币机制,用户可以直接资助项目、通过投票影响方向,开发者也能因提交代码、修复缺陷、完善文档等贡献获得透明量化的奖励。这并非要取代现有模式,而是为那些商业公司难以覆盖的项目,提供一种“自我供给”的补充路径,构建一个更直接的价值交换网络。 文章还列举了GitCoin、oscoin等一系列已有的探索实践,说明这一结合正在快速发展。最终,它描绘了一个图景:未来的开源项目可以自由选择许可证、基金会管理,以及基于代币的激励模型,从而让整个生态系统更加多元和充满活力。
PHP非阻塞实现方法
这篇讲的是如何让PHP在后端执行耗时任务时,仍能快速响应前端请求,避免阻塞页面加载。文章集中对比了8种实现非阻塞的技术方案。 作者从最简单的PHP-FPM内置函数`fastcgi_finish_request()`切入,它能立即结束会话,让后续代码在后台静默执行。对于需要发起异步HTTP请求的场景,介绍了利用`fsockopen()`设置非阻塞模式,以及使用cURL多句柄`curl_multi_*`函数的方法。 更进阶的方案涉及扩展与架构:`pcntl_fork()`能创建子进程来处理任务,优点是方便,但需要小心处理可能产生的僵尸进程;而Gearman和Swoole等异步框架则提供了更成熟的分布式任务处理能力。文章还提到了在高并发场景下常用的缓存与队列(如Redis)方案,将耗时操作解耦到后台执行。最后,也提及了通过系统命令或PHP原生协程(Coroutines)来实现的可能性。 总的来说,文章从不同技术层面剖析了PHP的非阻塞之道,为需要优化长任务处理的开发者提供了从快速实现到架构设计的多重选择。
TCP 滑动窗口 与窗口缩放因子(Window Scaling)
这篇讲的是TCP滑动窗口协议中一个常被忽略但影响重大的参数:窗口缩放因子(Window Scaling)。文章指出,TCP窗口字段本身只有16位,最大值为65535字节。在“高带宽-长延迟”的网络中,这个上限会成为性能瓶颈——比如在10Mbps、单向延迟80ms的链路上,理想窗口需要约100KB,但65KB的窗口迫使发送方必须等待确认,白白浪费了带宽。 为了解决这个问题,窗口缩放选项被引入。它通过在TCP握手中协商一个“缩放因子”,将接收到的窗口值左移该因子位,从而将最大窗口理论上扩展至约1GB(缩放因子最大为14)。文章通过计算示例说明,原先65KB的窗口经过缩放后,能够匹配高带宽网络的实际吞吐需求。 作者在实战中也验证了其效果:对一个上传服务进行调优,增大TCP缓冲区并启用窗口缩放后,上传一个8MB视频文件的时间从1分30秒显著缩短至20秒,体现了在特定网络环境下对此参数进行调优的实际价值。

流量引导:网络世界的负载均衡解密
这篇讲的是大型互联网系统如何把用户流量合理分配到多台服务器上。作者从早期云计算服务商简单地将域名指向一个服务器IP出发,指出这本身并非负载均衡,进而引出高可用和扩展性带来的挑战。 文章梳理了负载均衡技术的核心演进路线。首先分析了简单DNS轮询的弊端,比如DNS缓存导致故障切换缓慢,TTL设置也令人左右为难。接着,引入了四层(L4)网络负载均衡器,通过一个虚拟IP(VIP)和基于五元组的哈希算法,快速、高效地在多台服务器间分配连接,并具备了健康检查能力。为了应对数据中心级容灾,又引入了利用BGP泛播(Anycast)将同一VIP宣告到多个站点的方案,但也面临流量控制和就近访问的难题。最终,为了支持更复杂的应用逻辑(如缓存、限速、基于Cookie的分发),七层(L7)负载均衡器被加入架构,它能解析请求内容,做出更智能的决策,但其更高的计算成本也需通过前置L4均衡器来缓解。 文章指出,负载均衡是一个随云计算不断发展的复杂课题,从L4到L7,从单站点到多站点,其演进始终围绕着高可用、灵活性和控制力的权衡。
救命!我的电子邮件发不到 500 英里以外!
这篇讲的是一个听起来像都市传说,却又真实得令人哭笑不得的邮件故障。作者接到统计系主任求助,对方煞有介事地表示:“我们的邮件发不出520英里。”经过一番测试,问题居然是可复现的,近的纽约能到,远的波士顿就失败。 排查最终指向了一个看似“打补丁”的维护操作。服务顾问在升级服务器OS时,不慎将系统自带的Sendmail 8降级回了老版本的Sendmail 5。新的sendmail.cf配置文件中许多高级选项被旧版程序当作“垃圾”跳过,其中就包括SMTP连接超时——它被默认设成了0。作者通过计算发现,在0毫秒超时下,数据包依靠光速所能传播的极限距离,恰好就是这500多英里。一个系统配置的乌龙,竟意外地与物理定律产生了美妙的巧合。这个故事不仅是个绝佳的故障排查案例,也提醒着每一次“例行维护”都可能埋下意想不到的彩蛋。
交易系统如何确保账簿100%准确
这篇讲的是如何从设计层面根本性解决交易系统的账簿对账难题。作者指出,对账处理不好会带来巨大的人力成本和线上修改风险,因此提出一个核心设计原则:时刻保持整个系统的资产负债表为零。 文章以一个比特币交易系统为例,展示了只存储用户余额(资产)的账户表为何难以对账。关键一步是引入一个虚拟的“负债”(DEBT)账户来平衡整个资产负债。这样,无论用户间如何交易、资产如何转移(包括手续费进入FEE账户),所有账户的余额按币种求和,结果理论上都应精确为零。 基于此,对账逻辑变得极其简单:在每笔交易后执行一句SQL查询,检查各币种余额总和是否为零。文章还解释了用户入金和出金的本质是资产与负债账户之间的转移。这套设计不仅让系统能自动化、近乎实时地验证账簿准确性,也极大简化了财务核算,体现了用清晰架构提升系统可靠性的思路。
一起来学 Spring 2.X
这是一份针对 Spring Boot 2.x 的全面学习指南,由作者唐亚峰在其个人博客上连载。系列文章从最基础的构建第一个 Spring Boot 工程讲起,为读者铺设了一条清晰的学习路径。 整个系列系统性地覆盖了 Spring Boot 2.x 开发中的核心技术栈。作者不仅详细解释了配置管理、日志框架这些基础内容,还深入到整合 Thymeleaf 模板、使用 JdbcTemplate、Spring Data Jpa 以及 MyBatis 进行数据库访问的实战环节。对于进阶需求,文章进一步探讨了如何集成 Lettuce Redis 做缓存、利用 Spring Cache 二级缓存、接入 RabbitMQ 消息队列(包括延迟队列的实现),以及使用 Swagger 进行接口在线调试。 除了核心功能集成,系列也关注应用运维与工程化实践。例如,通过 Actuator 与 Spring Boot Admin 实现服务监控与管理,配置定时任务,实现文件上传与全局异常处理,以及借助 Liquibase 进行数据库版本管理。在安全与性能方面,讲解了整合 Shiro 安全框架,使用本地锁与分布式锁防止重复提交,并探讨了分布式限流方案的优雅实现。甚至包括 JDK8 日期格式化这种实用细节和 WebSocket 聊天室搭建这样的趣味课题。 这个系列最大的特点是循序渐进且内容扎实,每一讲都聚焦一个明确的主题并提供可运行的示例,非常适合希望从零开始或系统性巩固 Spring Boot 2.x 开发技能的读者作为案头参考。
Windows 下重定向当前进程的 stdout 到网络连接
这篇讲的是在 Windows 系统下,如何将一个正在运行的进程的标准输出(stdout)重定向到一个 TCP 网络连接中。这并非一个简单的 API 调用,作者为了解决这个需求,深入探索了 Windows 与 POSIX 在底层 I/O 机制上的根本差异。 作者指出,尽管 Windows 提供了 `_dup2` 来模拟 POSIX 的 `dup2`,但其进程标准输出句柄(HANDLE)与 C 运行时的文件描述符(fd)之间的绑定关系是静态的。在进程运行时调用 `SetStdHandle` 并无法影响 `cout` 或 `printf` 的输出流,这是解决问题的第一个关键障碍。 更麻烦的是,Windows 下的 socket 不能直接作为普通的文件句柄使用,因此无法通过 `dup2` 直接传递。作者最终采用的核心方案是:先用 `dup2` 将 stdout 重定向到一个匿名管道,然后启动一个独立的转发线程,持续从该管道读取数据并发送到目标网络连接中。这个方案还巧妙地解决了进程结束时可能丢失末尾输出的问题——通过主动关闭管道来通知转发线程结束,确保数据完整性。 整个探索过程涉及了 Windows 内核对象、句柄复制、管道 I/O 与多线程同步等多个层面的考量,最终作者将实现封装成了一个 Lua 模块,并在 GitHub 上提供了可运行的示例代码。
对SaaS业务的几点感受
这篇分享的是作者从C端产品转型到B端SaaS业务后,经过一年实践所得的核心观察。作者发现,SaaS产品与C端产品存在本质差异,主要体现在四个方面。 首先,SaaS产品面对的角色和流程链条远比C端复杂。产品需要同时考虑商家内部不同岗位(如老板、运营、财务)的权限与协作,以及最终的消费者,设计思考维度显著增加。其次,产品启动期漫长。不同于C端可以靠一个“爆点”快速迭代,SaaS需要先夯实那些用户不会单独提出但必不可少的“底座”功能,非常考验团队的耐心和扎实程度。 第三,SaaS产品通常不具备强网络效应。一个商家选择哪款软件,很少会直接影响其他商家的选择。这决定了业务必须更注重全链条的服务和老用户的深度维护。最后,也是因此,SaaS业务离不开强烈的销售意识。产品设计本身就需要思考如何向付费者清晰地传递价值,这与纯粹依赖流量的C端逻辑大相径庭。 作者以一位“行业新人”的视角,坦诚地将这些来自一线的、关于业务模式与产品设计复杂性的观察总结出来,揭示了SaaS赛道需要长期深耕、心态稳健的本质。
UMStor Hadapter:大数据与对象存储的柳暗花明
这篇讲的是大数据存储里一个经典矛盾的解决方案。作者从武侠江湖的比喻切入,指出数据湖架构也分“计算存储融合”(以HDFS为代表)与“计算存储分离”(以S3A+Ceph对象存储为代表)两大派系。前者有数据本地性优势,但NameNode易成瓶颈且弹性差;后者扩展灵活,但所有请求必须经过RGW网关,多了一跳,影响性能且不支持追加上传。 文章的核心亮点在于提出了一条“柳暗花明”的路径。作者团队受NFS-Ganesha启发,利用Ceph提供的librgw函数库,绕过了RGW网关这一中间环节。据此开发的Hadapter插件,能让Hadoop客户端直接通过librados与OSD通信。这相当于在保留对象存储管理优势的同时,借鉴了HDFS直接交互的思路,在IO路径上少了一跳,理论上能获得更好的读写性能,并补齐了社区版S3A在追加上传上的短板。 摘要最后可以简要提及Hadapter的部署便利性(一个jar包)和其作为Hadoop存储插件的定位,让读者对这个方案的具体形态有个直观了解。整篇文章的脉络是从问题拆解到方案融合,对架构选型有切实参考价值。
初探Kafka Streams
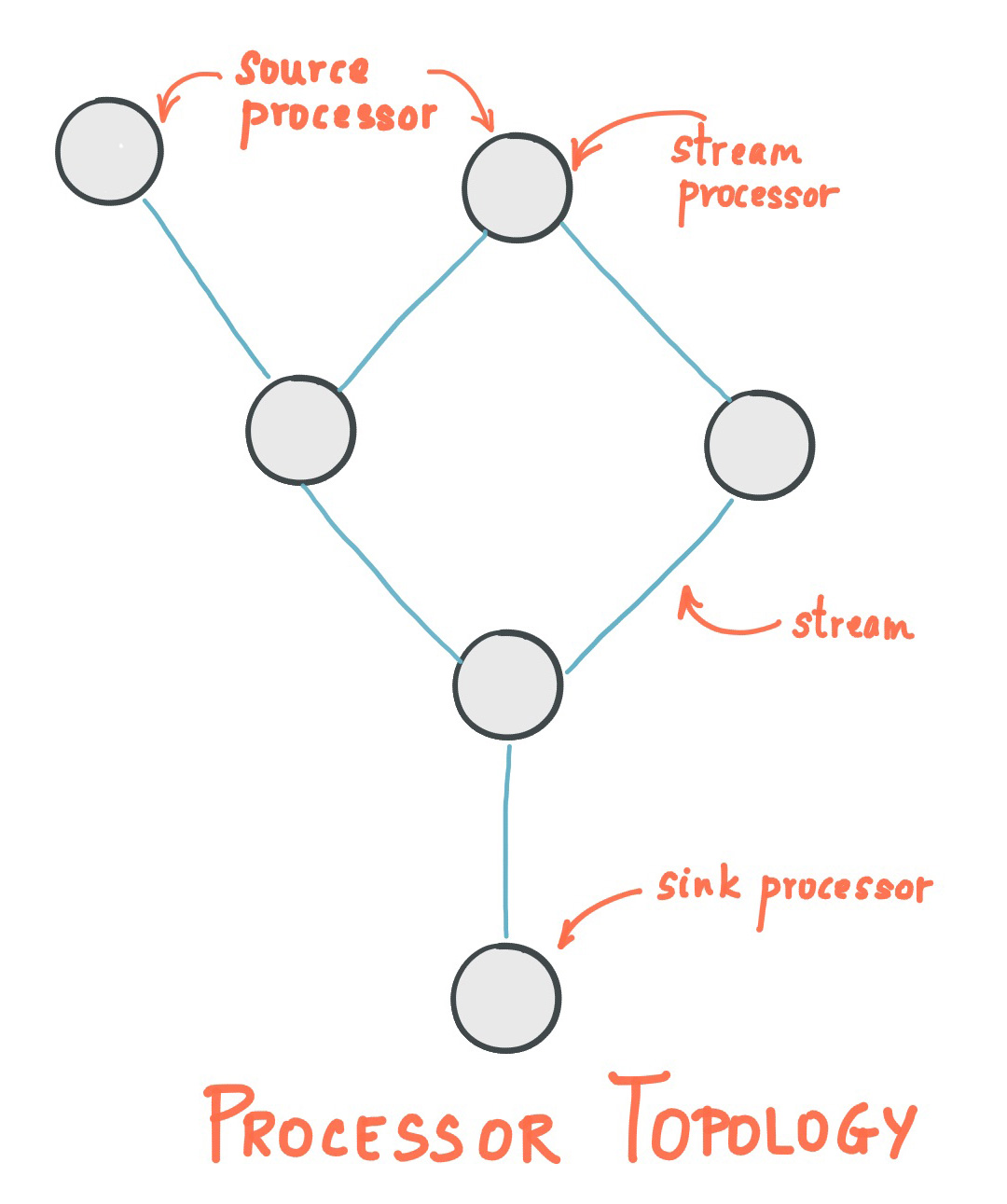
这篇文章从流式计算讲起,清晰地区分了它与批量计算及实时计算的核心差异。流式处理的是“无界”数据流,追求增量式计算与实时性,而非等待全量数据。 在此基础上,文章引出了Kafka Streams——一个轻量级的客户端类库,它让Java应用能轻松处理Kafka中的流数据。它的设计亮点非常突出:除了Kafka本身几乎没有外部依赖,却能利用Kafka的分区模型实现水平扩展和顺序保证;它通过可容错的状态存储支持复杂窗口操作,并提供从高层流式DSL到底层Processor API的完整工具链。 文章进一步深入到Kafka Streams的架构内核。它解释了以Stream(无界数据集)为核心抽象,如何通过Source、Sink等Processor节点构建出处理拓扑(Topology)。同时,也剖析了流处理中至关重要的时间模型,如事件时间与处理时间的区别。最终,文章展示了Kafka Streams如何将简洁的客户端编程与强大的服务器端集群能力结合,为构建微服务提供了一条清晰的路径。
我的阿里面试之路
这篇讲的是作者长达三个月的阿里云技术岗面试全记录。与许多“面经”不同,它并非一份简单的答案清单,而是从面试者的视角出发,详细还原了从电话面到交叉面、最终拿到offer的曲折过程。 文章坦诚地分享了作者在算法题、系统设计以及技术深度探讨中遇到的具体挑战,尤其是几次因准备不足或理解偏差而差点“翻车”的真实时刻。作者从中总结出几个核心发现:阿里面试尤其看重对技术原理的深刻理解与现场推导能力,而非死记硬背;同时,清晰的沟通逻辑与展现解决问题的思维过程,有时比直接给出最优解更重要。 对于正在准备大厂技术面试,或是对阿里巴巴技术文化感兴趣的读者来说,这篇复盘不仅提供了实战细节,更揭示了面试背后对技术底蕴与临场应变能力的双重考验。它像一面镜子,能让读者在别人的经历中照见自己的准备方向。
通过Twemproxy提升PHP/Redis的性能
这篇文章讲的是如何用 Twemproxy 这个看似“古老”的 Redis 代理,来解决 PHP 应用中难以实现真正连接池的性能痛点。作者没有从复杂的理论入手,而是直接从一个已知的“曲线救国”方案(借助 Nginx Stream 模块)出发,转而尝试用现成的 Twemproxy 来达到相同目的。 核心方案是让 Twemproxy 与 PHP 部署在同一台服务器上,并通过本地 Unix Domain Socket 进行连接。经过初步压测,作者发现默认的单进程 Twemproxy 并没有带来性能提升,问题根源在于其单线程架构无法利用多核 CPU。因此,他调整策略,按照 CPU 核心数启动了多个 Twemproxy 进程,并让 PHP 请求随机分配到这些进程对应的 Socket 上。 最终的测试结果非常直观:性能提升了整整 100%。作者在文中指出了性能跃升的关键因素:Twemproxy 的 Pipelining 功能将多个请求打包发送,减少了网络 RTT,同时还优化了连接建立过程。文章不仅给出了具体的配置文件示例和压测命令,还提到了如 mbuf-size 设置和绑定 CPU 等实战细节,为读者提供了可直接参考的落地步骤。
浅谈《守望先锋》中的 ECS 构架
这篇技术博客的作者从《守望先锋》GDC演讲出发,深入浅出地解析了游戏开发中的ECS架构。文章直面传统面向对象游戏引擎的痛点——每个游戏对象都捆绑了所有功能模块的Update方法,导致模块间耦合严重、内聚性差。对于像《守望先锋》这类需要复杂网络预测与同步的游戏,传统架构显得力不从心。 作者详细拆解了ECS(Entity-Component-System)的核心设计:Entity仅作为带ID的生命体容器;Component是纯数据(如位置、输入状态);System则是纯逻辑处理单元。框架负责根据System声明的Component组合,自动筛选出它关心的Entity子集进行遍历。这使得每个System能高度专注且松耦合。文章还提到了Singleton Component的演进、Utility函数的使用以及如何集中处理有副作用的行为。 最终,作者指出ECS最大的优势在于清晰分离状态与逻辑,这极大简化了网络同步中的状态快照与回滚操作。《守望先锋》利用这套架构,在60fps的固定更新频率下,优雅地处理了客户端预测、服务器仲裁及网络波动时的“时间压缩”同步难题,展现了架构在管理复杂度上的强大能力。
分布式系统中唯一ID的生成
这篇讲的是分布式系统中一个看似简单却至关重要的问题:如何生成全局唯一的ID。作者从实际大型系统的共同需求出发,对比了几种主流方案,分析了它们各自的适用场景与取舍。 文章首先剖析了“独立生成服务”这类集中式方案。最典型的是利用数据库的自增序列,它保证了递增性,但存在单点瓶颈。对此,一个变通思路是通过划分序列范围或设置不同步长,用多个节点分摊生成任务,但这又牺牲了全局的递增性。作者重点介绍了开源方案Twitter Snowflake,它通过组合时间戳、节点编号和自增序列,在保证高性能与有序性的同时,减少了中心化依赖(尽管节点ID仍需从Zookeeper获取)。 另一大类是“本地生成器”。这类方案在节点本地生成ID,通常要求不同节点间无状态依赖。例如用主机号加时间戳,简单但受限于单毫秒只能生成一个ID;而UUID(通用唯一识别码)则提供了更灵活的128位随机标识,不过理论上仍存在极低概率的冲突。 整体来看,作者并未简单评判优劣,而是引导读者思考:在递增性、全局有序、高可用、高性能与实现复杂度这些不同维度间,应如何根据具体业务场景做出合适的选择。
个人博客技术演进的流水账
这篇文章从个人博客的“搬家史”出发,串起了一个Web前端技术演进的缩影。 作者最初受困于商业博客平台的种种限制——域名不可控、内容易丢失、样式不自由,为了“把数据和控制权握在自己手里”,走上了自建博客之路。文章以这个起点展开,以博客系统的技术栈变迁为线索,梳理了Web开发的几个关键时期:从前后端不分的“SHTML+SSI”时代,到ASP/PHP动态脚本主导、MySQL普及的“前后端初分”时期;再到jQuery大行其道、前端资源开始分离,以及MV*框架、模块化构建工具与Node.js全栈模式兴起的高速迭代时代。 文中提及了SaBlog、WordPress、Ghost等具有代表性的博客系统,并剖析了它们在各自阶段如何体现当时的主流技术架构与痛点。作者的流水账,实际上记录了前端如何从一个“后台附属”逐渐走向工程化、复杂化并分担更多职责的过程。文章结尾留下的疑问,也为思考当下技术选型提供了一个历史参照。
sproxy开发体验
作者分享了开发sproxy代理工具时的一些实战经验。起初是为了解决内网服务需要统一通过代理访问公网的需求,他用Go编写了支持多种协议的sproxy。在后续迭代中,为了能对接Shadowsocks等服务,只需利用golang.org/x/net/proxy库并借助环境变量配置,就能轻松增加SOCKS5链式代理支持。 这次经历虽只涉及少量代码改动,却让他收获了多个实用的排坑心得。例如,在Mac上调试监听443端口的程序时,因权限不足,他通过端口重定向巧妙地解决了问题。更关键的是,他发现本地DNS解析可能被污染,导致调试时访问特定网站不通,将域名解析环节调整到SOCKS5代理之后进行则可解决此问题。文章还简要提及了dnscrypt等更复杂的DNS安全方案,以及对SOCKS5协议特性和Go语言调试环境的观察。 这些来自一线开发的具体细节与思考,对于同样在处理网络代理、开发环境调试的开发者来说,提供了不少可直接参考的路径和启发。
如何将树莓派变成电子书服务器
这篇文章讲的是如何用一台树莓派3和开源软件Calibre,在本地网络中搭建一个私有的电子书服务器,特别适合网络条件不佳的环境共享阅读资源。 作者的起点很实际:学校或图书馆需要共享电子书,但可靠带宽并非总能获得。他选择的方案是利用Calibre 3.0(支持浏览器在线阅读)的强大功能,将其部署在低功耗的树莓派上。整个过程并不复杂,核心是在Raspbian系统上安装Calibre,然后配置其内置的内容服务器。 文中展示了从下载系统镜像、通过终端命令安装Calibre,到搜索并添加免费电子书(如从古腾堡计划下载马克·吐温的作品)的具体步骤。关键操作包括启动服务器、用`ifconfig`获取树莓派的IP地址,最后通过同一局域网内任何设备的浏览器访问`IP:8080`端口即可连接。 作者最终在iPhone、Linux和Mac电脑上都测试成功,验证了这个方案的可行性。它把一台廉价的微型电脑变成了一个随时可用的数字图书馆枢纽,对于教育和小团队知识共享场景是个不错的思路。
【死磕Java并发】—–J.U.C之Java并发容器:ConcurrentLinkedQueue
这篇技术解析深入探讨了Java并发包中非阻塞线程安全队列ConcurrentLinkedQueue的实现原理。文章从线程安全队列的两种实现思路(阻塞与非阻塞)切入,重点剖析了ConcurrentLinkedQueue如何完全基于CAS算法(无锁)来实现其核心操作。 作者详细拆解了该队列必须遵循的四个关键不变性,并阐明了head与tail指针在更新时可以“滞后”的设计特性。全文的核心在于通过逐行解读offer()入列与poll()出列方法的源码,并辅以清晰的步骤图,生动展示了在多线程竞争环境下,新节点是如何被安全添加、以及头部节点如何被识别并移除的。分析中特别指出,像“p == q”这种看似异常的判断,正是处理并发删除与插入操作交错进行的关键所在,巧妙地解决了指针可能因并发更新而失效的难题。 通过这篇文章,读者能直观理解一种高性能并发容器如何在不使用锁的情况下,通过精巧的指针操作和CAS原子指令来保障线程安全与最终一致性。
缓存那些事
这篇讲的是缓存体系中的“十八般武艺”。作者从最前端的浏览器缓存头(If-Modified-Since)谈起,带我们看到了CDN层面的不同玩法:CSI、SSI和ESI。文章特别指出了ESI在App接口场景下的适用性,以及在高并发要求下,直接生成静态文件上传CDN的硬核方案。 视线转向应用层,文章拆解了local cache、Redis、Tair构成的多级缓存策略。以当当网交易链路为例,设置了1分钟的本地缓存过期时间,在一致性与性能间取得了平衡。对于开发者常头疼的缓存击穿问题,文章清晰地列举了三种场景:缓存过期、数据不存在和缓存宕机,并分别给出了“加锁防雪崩”、“空对象防穿透”和“DB裸压保底”的实战心法。 此外,文章还延伸到了提升用户体验的pjax局部更新与bigpipe分段输出技术。最后,作者将笔触落到缓存优化的细微处——通过精简Key、使用slim object序列化以及Gzip/Brotli压缩,从一点点缩减对象大小入手,来节省整个缓存池子的资源。这是一份从浏览器到服务器、从架构到细节的缓存实践地图。