nosql数据库选型
作者翻阅了《七天七数据库》一书后,结合自身多个项目从MySQL迁移到NoSQL的实际需求,分享了一套具体的数据库选型方案。他指出,不同的业务场景需要不同的数据库来发挥最大价值。 对于社区网站中复杂的关系数据(如用户关注、图片关联),他摒弃了传统关联表,选择了原生支持图关系的Neo4j,这不仅简化了数据模型,也提升了查询性能和开发体验。而面对网站丰富且结构多变的内容模型(如用户、站点),他看中了MongoDB对复杂索引查询的良好支持,认为其能完美替代MySQL的大多数功能,并可能简化缓存层,甚至取代部分Redis的角色。 在处理高写入、弱一致性要求的微博本地缓存时,他对比后认为Cassandra在写性能和可用性上优于MongoDB。对于极高并发的API服务,他则在Cassandra和Riak之间权衡,前者在列式存储和写性能上可能更具优势。 整篇文章从具体业务痛点出发,详细对比了不同NoSQL数据库在一致性、查询能力、性能及运维复杂度上的关键差异,并给出了清晰的选型结论。这为同样面临类似技术过渡的开发者,提供了一个非常实用且可参考的架构思路。
Impala:新一代开源大数据分析引擎
这篇讲的是Cloudera推出的Impala,一个旨在解决Hive查询速度瓶颈的开源大数据分析引擎。文章详细拆解了Impala如何借鉴Google Dremel的思想,采用列式存储(Parquet格式)和多层查询树架构,摆脱MapReduce的批处理束缚,从而在交互式查询上实现数量级的性能提升。 作者将Impala与同期的Shark、Apache Drill进行了横向对比。Impala的优势在于相对成熟的工程实现和快速的查询响应,但其容错机制较弱,且开源生态初期主要绑定Cloudera自家发行版。相比之下,基于Spark的Shark在内存计算和容错性上更有优势,而Apache Drill则更具平台开放性,尽管当时开发进度稍慢。文章通过性能对比图表指出,尽管Impala和Shark都远超Hive,但与Amazon Redshift等商业MPP数据库仍有差距。 文章的最终观点是,大数据分析的未来不在于某一技术的独胜,而在于Hadoop生态(如YARN)将兼容并包,让不同引擎各司其职——Impala这类系统擅长秒级交互查询,而MapReduce则继续处理大规模批处理任务。这场技术竞争正推动大数据分析变得更成熟、易用和普惠。
SSDB 配置文件
这篇讲的是如何理解和定制 SSDB 的配置文件。文章开篇就点明,默认附带的配置文件无需修改即可运行,但若需高度定制,了解其配置项就很有必要。 配置文件本身是层级 key-value 的静态格式,通过 TAB 缩进来表示结构,一目了然。文章逐一拆解了核心配置段:`work_dir` 指定了存放数据和日志的工作目录;`server` 段控制监听的 IP 与端口,出于安全考虑,可以将 IP 绑定为仅本机访问的 `127.0.0.1`;`replication` 段用于设置主从复制,明确了从服务器如何同步数据;`logger` 段管理日志级别、输出文件以及支持的大小轮转策略。 最值得关注的是 `leveldb` 段的配置。文章特别指出,`cache_size` 参数直接影响性能——适当增大缓存能提升读性能,但过大的缓存反而会拖慢写速度。这种基于实际使用场景的调优建议,对管理员来说非常实用。 总的来说,这篇文章将看似枯燥的配置文件讲解得清晰明了,不仅解释了“是什么”,还点出了“为什么”和“怎么调”,无论是初次接触 SSDB 的开发者,还是需要优化部署的运维人员,都能从中快速找到自己需要的配置要点。
基于Solr的空间搜索(3)
这篇讲的是如何在Solr中实现高性能的地理位置搜索。作者从纯使用GeoHash过滤效率不高的问题出发,介绍了一种结合**笛卡尔层(Cartesian Tiers)与GeoHash**的组合方案。 核心思路是分两步走:在构建索引时,同时为每条记录计算其所属的不同精度层级的网格ID(tierBoxId)。查询时,先用笛卡尔层根据查询范围快速定位一个大致的网格集合,将这些网格下的文档ID存入一个BitSet,完成初步粗筛。随后,再将这个BitSet作为输入,传递给GeoHash距离过滤器。该过滤器遍历粗筛后的文档,通过GeoHash解码出精确经纬度,计算其与查询点的实际球面距离,并过滤掉超出范围的结果。 实现上的一个巧妙之处在于利用了Lucene的FieldCache来缓存GeoHash值,并通过过滤链(Filter Chain)将两层过滤逻辑无缝衔接。作者还展示了一个本地查询实例,验证了这套方案在查询指定经纬度500公里内数据时的有效性。整体来看,这种“粗筛+精算”的两级过滤模式,显著减少了需要进行精确距离计算的文档数量,从而提升了查询性能。
基于Solr的空间搜索(1)
这篇讲的是如何在Solr中实现高效的“附近搜索”等空间查询功能。作者从基础原理出发,重点剖析了两种核心方法:Cartesian Tiers(笛卡尔层)和GeoHash算法。 笛卡尔层的思路很直观:把地图像切蛋糕一样分成层层网格。查询周边时,系统只需在几个特定层级的相关网格内搜索,从而大幅减少需要扫描的数据量,这就像一个聪明的漏斗,帮你快速缩小范围。而GeoHash则提供了一种巧妙的编码方式,它将二维的经纬度转换成一维的字符串,比如“wx4g0ec1”。这个字符串本身就像一个地址,前缀代表更大的区域,利用前缀匹配就能轻松实现范围查询,把复杂的空间问题变成了简单的字符串匹配。 文章通过详细的图解和计算示例(比如如何为北京某点的坐标生成GeoHash码),把这两个算法的实现流程讲得非常透彻。理解了这两个基础,你就能明白许多地图应用背后高效的空间检索是如何运作的。文章最后也提到,关于如何在Solr中具体构建索引和执行查询,会在后续内容中展开。
国际商品编码EAN-13介绍
这篇讲的是我们身边无处不在的商品条形码背后的技术标准——EAN-13。文章深入剖析了这个全球通用编码的内部结构。一个标准的EAN-13码由13位数字构成,包含了国家代码、厂商代码、产品代码和检查码。其巧妙之处在于,为了便于机器可靠读取,它并非简单对应,而是有一套精密的编码规则。 具体来说,最左边的第一位数字作为“导入值”,本身不印出条纹,但它决定了紧随其后的六位数字(左资料码)采用A类还是B类的编码模式。左、右资料码之间还通过“中线”这个特殊标识分隔开。右资料码则统一采用C类编码。文章详细列举了A、B、C三类编码各自的逻辑值转换规则,这些由细黑线和细白线组合成的不同图案,最终构成了扫描枪能够精准识别的条形码。 这种多层级、有变化的编码设计,确保了即使从左到右扫描,机器也能准确无误地读取信息,理解了这套规则,就明白了超市扫码器“嘀”一声背后运行的逻辑。
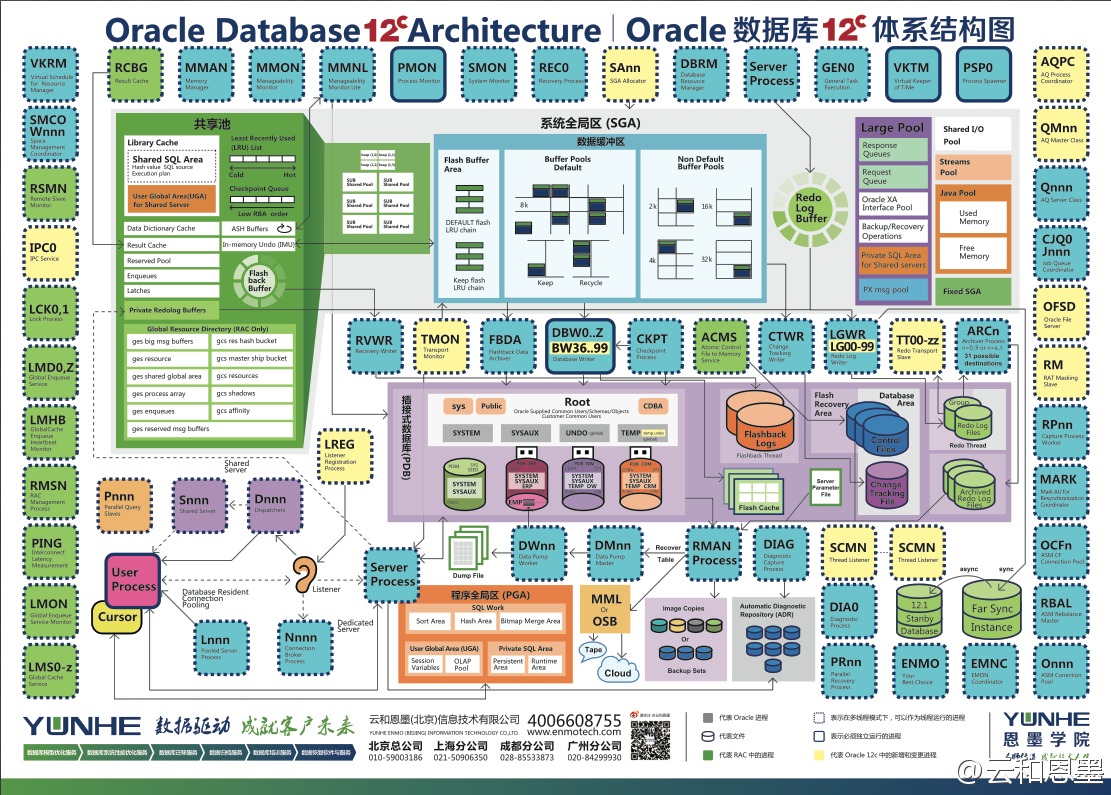
云和恩墨版Oracle Database 12c 最新体系结构图下载
这篇分享的是云和恩墨精心制作的Oracle Database 12c体系结构图。该图最早于2013年甲骨文全球大会上发布,历经多达43个版本的反复修订和打磨,旨在为技术爱好者们提供一份准确、清晰的数据库架构全景参考。其细节之处凝结了团队深厚的技术研究与精益求精的态度。 如今,这份高质量的架构图已开放电子版下载。文章直接提供了Windows版压缩包以及适配Mac不同分辨率(1280X800与1920X1080)的JPG图片下载链接,方便不同平台的用户使用。对于这样一个持续迭代的专业成果,作者也开放了反馈通道,欢迎读者指出任何可能存在的错误或问题,以便在后续版本中进行更正与完善。
数据的游戏:冰与火
这篇讲的是一位在Amazon和淘宝都有过实践的数据挖掘新人,在不到10个月里总结出的“冰与火”心得。作者开篇就点明,数据世界象征着权力与征服,但通往“王座”的道路布满荆棘。 文章的核心观点很明确:他从Amazon经验中提炼出数据团队的三大角色——苦累却至关重要的数据清洗员、技术含量最高的研究科学家、以及相对次要的软件开发工程师。作者强调“Garbage In, Garbage Out”,再牛的算法也敌不过一堆垃圾数据。 通过两个生动的案例,作者阐明了数据质量的重要性。一是像Amazon那样建立严格的商品ID(ASIN)作为数据标准;二是清洗海量但格式混乱、真假混杂的用户地址数据。他指出,数据不分大小,只分好坏,从80%的准确度提升到90%,所需成本远超过从60%到80%。 作者进一步讨论了业务场景对数据挖掘的制约。推荐系统在音乐和电商场景下逻辑截然不同,对书籍和服装的需求预测难度也有天壤之别。他提醒,数据挖掘远非人工智能,在特定业务场景下,资深从业者的经验甚至比机器学习更准。 最终,作者认为数据分析结果不能止步于统计呈现,必须能指导下一步行动。他抛出了数据挖掘中质量、场景与结果这三个关键问题,虽未给出标准答案,却为从业者揭示了被算法光环所掩盖的实践本质。
HBase解决Region Server Compact过程占用大量网络出口带宽的问题
这篇讲的是作者在维护一个HBase 0.94.0集群时遇到的实际问题。他们发现多台Region Server的网络出口带宽经常跑满千兆网卡极限(接近100MB/s),机器负载也异常高。在排查中,一个关键疑点是:根据查询量估算,出口带宽本应只需约60MB/s,但实际观测值却多出了约40MB/s。 经过对源码(CompactSplitThread.java)的分析,根因被定位为集群在高写入压力下频繁触发了Compaction。由于Compaction过程本身需要读取大量数据,从而“偷走”了这部分额外的网络带宽。这是一个在0.92版本后,因引入small/large Compaction线程而可能出现的典型性能问题。 为此,作者提出了两个具体的配置调整方案。核心思路都是减少Compaction的并发度或触发频率:一是通过调大throttle值强制所有Compaction变为small类型,并保持线程数为1;二是直接将small Compaction线程数设为0以关闭它。应用配置后,Region Server的网络利用率显著下降至70MB/s以下,问题得到有效解决。
Impala与Hive的比较
这篇文章深入对比了Hadoop生态中两款重要的SQL查询工具:Impala与Hive。它们虽然共享HDFS/HBase存储和相同的元数据,但设计目标截然不同。 核心差异在于查询引擎的架构。Hive将查询转换为一连串的MapReduce任务,采用“推”式数据流和依赖外存的中间结果落盘,适合长时间、稳定的批处理作业。而Impala受Google Dremel启发,彻底绕开了MapReduce,其分布式查询引擎直接生成执行计划树,并以“拉”式流传输中间数据、最大化使用内存,大幅降低了延迟,专为交互式分析设计。 文章详细拆解了Impala的组件与查询流程,并指出其多项优化技术,比如使用LLVM进行运行时代码生成、利用SSE4.2指令集以及更优的I/O调度。不过,Impala在容错和处理超大数据集时存在限制。因此,一个高效的实践是:先用Hive进行耗时的数据清洗与转换,再让分析师在处理后的数据集上利用Impala进行快速、反复的探索与验证。
perl查询空表引起的bug
这篇文章详细复盘了阿里集团内部数据采集系统(xxagent)中,一个由Perl查询空表引发的诡异Bug。问题现象是:当数据库表(如lijie)中没有记录时,Perl脚本通过DB模块查询,得到的日志显示矛盾结果——直接打印查询结果数组显示为0条,但数组的标量上下文却报告存在1条记录,导致数据采集逻辑异常。 问题的根因出在DB模块的`query`函数实现上。当底层数据库查询返回0条记录时,函数并没有正确地返回一个空数组给调用方,反而因为`scalar @res`为假,错误地进入了重连和重试的逻辑循环,最终函数没有显式返回值,造成了调用方接收到的状态不一致。 修复方案很直接:在`query`函数的循环外添加一个明确的返回语句,确保在重试耗尽后,能返回一个预先定义好的空数组`@nores`。修改后,空表查询的行为得到修正,日志输出恢复为一致的`0`条记录,监控逻辑也随之正常。这个案例提醒我们,即使是一个简单的数据库查询封装,也必须对空结果集等边界情况做严谨的处理,否则可能埋下难以排查的隐患。
Oracle Database 12c架构图
这篇讲的是Oracle Database 12c的架构全景图。作者提供了两张高清图表,一张完整勾勒了12c的整体架构,清晰地展示了所有关键组件以及它们之间的关系,特别是那些在新版本中引入或调整的后台进程,并简要说明了它们的工作原理。另一张则专门聚焦于12c最引人注目的特性——多租户(Pluggable Database)架构。这张大图详细描绘了容器数据库(CDB)与可插拔数据库(PDB)之间的交互逻辑,将这种能大幅提升资源利用率和管理效率的新模式,以可视化的方式呈现得一目了然。对于需要快速理解Oracle 12c技术演进方向、或正在规划数据库升级的团队来说,这两张图提供了非常直接的架构参考。图文结合的方式,让抽象的数据库内核设计变得直观可感。
企业掘金大数据的两种选择
这篇讲的是企业如何真正将数据转化为利润,而不仅仅停留在“拥有数据”的层面。作者从“很多公司坐拥金矿却不知如何挖掘”的普遍困境出发,明确指出了两条核心路径:一是优化业务流程,二是创新数据产品。 在流程层面,文章强调现代数据科学家需要超越传统Excel和SQL,综合运用统计、机器学习等工具。例如通过分析SaaS高端客户特征来优化营销,或像Target那样建立预测模型识别潜在消费群体。在产品层面,除了直接出售数据(如Twitter授权DataSift),更多公司是将数据智能融入产品,比如广告平台精准投放、电商推荐系统提升购买率,或媒体网站个性化内容展示。 文章最后给出了具体行动指南:企业应尽可能全量保存各类原始数据,根据规模聘请或培养数据科学家团队,并考虑将自有数据产品化。而这一切成功的基础,在于管理层必须建立以数据为导向的决策文化。
PL/SQL的那些事儿
这篇讲的是PL/SQL在Oracle数据库中的正确使用姿势,作者通过对比两种常见场景,点明了优化的核心。 文章清晰地划分了PL/SQL的两类使用场景:一类是作为“胶水”,串联一系列SQL分析语句,性能瓶颈主要在SQL引擎;另一类是用游标逐行处理数据,进行过程化计算。作者指出一个关键现象:即便优化后者,性能提升也有限;但若将其重写为前者纯SQL驱动的模式,性能常能获得成百上千倍的提升。这揭示的根本原则是:务必优先利用数据库核心的SQL引擎能力,而非用过程化代码(无论是Java还是PL/SQL)去替代它。 当然,PL/SQL并非一无是处。文章也强调了其不可替代的价值,例如实现数据库内部监控工具。作者用了一个形象的类比:将监控代码部署在数据库内部,就像把监控脚本直接放在被监控主机上,避免了网络开销,能获取更精确的数据。文中推荐的工具Session Snapper,就是一个典型的、高效运行在数据库内部的PL/SQL诊断范例。 因此,PL/SQL是一把宝剑,用于数据库管理与扩展时锋利无比;但若当作处理数据的“菜刀”来过度使用,则可能事倍功半。
Java的那些事儿
这篇讲的是作者从个人经验出发,分享对Java语言的理解与数据库开发实战心得。作者认为,Java因其设计上的后发优势、简单的语法和强大的生态(如优秀的IDE),相比C/C++在开发效率上更胜一筹,尤其在现代注重高并发与可扩展性的项目中。 文章的重点,落在了Java开发者(特别是使用Oracle数据库时)必须掌握的三个核心数据库优化点上:首先是连接池技术,以解决连接数失控或过度复用的问题,并给出了基于Oracle UCP的配置示例;其次是语句池技术,强调必须使用绑定变量并启用语句缓存,以避免昂贵的软解析开销;最后是资源泄露问题,指出Java的内存回收机制无法处理数据库连接、游标或事务锁的泄露,这常常是异常处理不严谨导致的,并附有锁等待的监控图作为例证。 作者从实用主义出发,最终将讨论落脚于具体的技术细节与解决方案,对于从事数据库应用开发的Java程序员来说,文中列出的这几点排查清单具有直接的参考价值。
C Mohan 讨论NoSQL的得与失
这篇文章是资深数据库专家 C Mohan 从历史演进的视角,对 NoSQL 运动兴起背景及其暴露问题的系统性梳理。他首先指出了传统关系数据库在应对 Web 2.0 时代需求时的力不从心,比如难以建模社交图谱、JSON 数据交换不便、扩展性与成本制约,以及 ACID 原则在实际业务中常需妥协等。 接着,作者结合自己在 System/38、Lotus Notes 乃至 DB2 等系统上的深刻教训,揭示了数据库内核设计的复杂性,例如锁粒度、崩溃恢复、集群支持等关键环节的挑战,为理解后续问题埋下了伏笔。 随后,他犀利地剖析了 NoSQL 方案普遍存在的“先天不足”:对并发控制与原子性等事务核心问题关注不够,索引设计过于简单,数据模型复杂却缺乏标准化工具,以及对分布式下一致性和可靠性的误判。文章并未全盘否定 NoSQL,而是强调无论是 MongoDB 的写锁、CouchBase 的文档复制粒度,还是对 ACID 的简化处理,都在高并发或复杂业务场景下可能遇到瓶颈。 最终,这篇讨论的启发在于:技术选型需回归具体场景的本质需求,无论是追求强一致的传统企业核心系统,还是需要灵活扩展的互联网应用,理解关系数据库与 NoSQL 各自的设计哲学和代价,才能避免盲目追随潮流,做出更务实的技术决策。
Ceph的现状
这篇详细拆解了Ceph这个统一分布式存储系统,它告诉我们,Ceph卓越的性能、可靠性和扩展性,都建立在一个名为RADOS的底层对象存储系统之上。而RADOS的核心,正是那个巧妙的CRUSH伪随机数据分布算法。这个算法是解决大规模集群中数据如何高效、均匀分布到成百上千节点的关键,它能在节点增减时最小化数据迁移,平衡了效率与扩展性这一对矛盾。 在RADOS基础之上,Ceph通过不同组件提供了三种存储接口:LIBRADOS提供了直接的对象操作API,RADOS Gateway兼容了S3和Swift,让对象存储更易用;RBD则将存储抽象为块设备,支持精简配置、快照等企业级特性;Ceph File System则直接提供POSIX接口,无缝对接传统文件应用。这真正体现了“统一”的价值。 文章同样关注了Ceph的“人”的生态。项目源于Sage Weil的博士论文,至今已积累24万行代码,近期开发活动依然活跃。更值得关注的是其完善的社区设施,从邮件列表、项目管理到详尽的文档和路线图,构成了一套健康、开放的运作体系,这为Ceph的长期发展和质量提供了坚实保障。
深入理解Oracle中的Mutex
这篇讲的是Oracle数据库中两种底层串行机制——Mutex与Latch的深度对比分析。作者从内部机制出发,清晰阐述了Mutex为何以及如何在多个场景下成为更优的选择。 关键差异首先体现在效率上:Mutex获取仅需约30~35个CPU指令,而Latch需要150~200个;其内存结构也仅16字节,远小于Latch的112字节。更重要的是,Mutex的设计能大幅减少伪争用——不同于一个Latch保护多个热点对象,一个Mutex可以专门服务于单个数据结构(如每一个父游标或子游标),使得串行控制点更精准。 文章详细剖析了Mutex如何兼具传统Latch和Pin的双重职责。其内嵌的引用计数(ref count)机制,使其能像Pin一样防止对象被释放,同时自身又提供了必要的串行保护。在10.2版本后,这直接替代了游标执行时频繁创建/销毁library cache pin的昂贵操作,后续进程只需轻量级地增减引用计数即可。作者以KKS游标共享为例,列举了在父游标检查、统计信息访问等操作中,Mutex如何带来更低的解析成本和更好的并发性能。 最后,文章也提供了从AWR报告解读Mutex等待事件(如cursor:mutex S/X, cursor:pin S)的思路,并附上了统计信息表示例,为实际的性能诊断提供了具体指引。
Django数据库访问优化
这篇文章从Django开发者的实际痛点出发,聚焦于如何诊断并解决数据库访问性能瓶颈。作者首先指出了两个实用的分析工具:利用 `django.db.connection` 查看执行的SQL与耗时,以及集成 `django_debug_toolbar` 进行可视化监控。 在优化策略上,文章的核心思路是将计算尽可能下推到数据库层完成。它详细讲解了如何善用 `filter`、`exclude` 以及 `F()` 对象进行高效过滤,并通过 `annotate` 预先完成聚合计算。对于复杂查询,则介绍了 `QuerySet.extra()` 和原生SQL的使用场景。 针对ORM层常见的性能陷阱,文章深入剖析了QuerySet的惰性求值与缓存机制。它对比了 `select_related`(针对外键/一对一关系)与 `prefetch_related`(针对多对多关系)这两种预加载技术的不同适用场景,能有效避免N+1查询问题。此外,通过 `values()`、`defer()` 和 `only()` 精确控制返回字段,以及使用 `count()` 代替 `len()`,都能显著减少不必要的数据传输与处理开销。这些技巧共同构成了一套从诊断到优化的完整实践指南。
Oracle数据恢复专题
这篇专题文章直击一个国内DBA常面临的痛点:如何在缺少规范备份的严苛条件下,执行Oracle数据库的恢复操作。作者从东西方DBA工作重心的差异切入,坦言“无备份恢复”在国内技术环境中,有时会成为一种被迫练就的“屠龙之技”。 文章并非泛泛而谈,而是系统整理了一系列极具实战价值的案例与脚本。从利用DUL、BBED等底层工具直接抢救数据文件,到通过构造ROWID巧妙绕过ORA-1578等坏块错误;从处理ASM磁盘头丢失这类存储层灾难,到解决PL/SQL对象被覆盖、数据文件名乱码等逻辑故障。每一个链接背后,都是一个需要深入理解数据块结构与数据字典的硬核场景。 对于需要直面数据库“心跳停止”时刻的工程师来说,这份专题更像是一本应急手册。它提供的不只是方法,更是对Oracle内部机制的理解深度——在备份失灵时,这份理解往往是找回数据的最后一道防线。