undo异常事务回滚规则分析
这篇讲的是Oracle数据库在异常情况下(如非正常关闭或事务未提交会话终止)undo事务回滚的具体机制。文章没有停留在理论描述,而是通过一系列实际的测试和dump操作,清晰地展示了这一回滚过程是如何发生的。 核心流程是,数据库启动后会扫描回滚段,识别出未提交的事务。它通过事务的xid(回滚段号.槽号.序列号)定位到具体的undo block,再通过undo记录中的信息找到对应的数据块(data block)。回滚的关键在于undo记录之间通过rdba字段形成了一个链表结构。文章通过dump回滚段头(v$transaction视图)和具体的undo block(datafile 2 block 3627)证实了这一点:一个undo block处理完成后,其内部的undo记录(rci字段)指向前一个undo block的rdba地址,从而实现连续回滚。整个过程遵循“先进后出”原则,即最后修改的数据块最先被回滚。 作者通过从创建测试表、查询事务信息到最终dump出undo block内部结构的完整步骤,直观地揭示了Oracle底层利用undo链表保证事务原子性和数据一致性的精巧设计。
关于blockrecover 解决坏块相关测试与总结
这篇文章讲的是,当线上数据库因硬件故障(如小机意外掉电)出现大量坏块,甚至坏块中包含未提交事务时,如何使用Oracle的blockrecover命令进行恢复。作者从一个真实的故障场景出发,客户在IBM p系列小机更换电源后,数据库(9.2.0.8 RAC)出现了大量坏块和smon回滚报错。为了在减少业务影响的前提下解决问题,团队决定采用blockrecover方案。 为了验证该方案在复杂情况下的有效性,作者在10g环境下进行了完整的模拟测试。实验详细重现了从创建测试表、使用RMAN备份数据文件、切换归档日志,到人为模拟产生包含未提交事务的坏块的全过程。测试的关键在于,它不仅模拟了坏块,还通过后续的业务操作模拟,验证了blockrecover能否在不影响其他正常数据块的情况下,精准修复目标坏块并正确处理其中的事务。 最终的测试结果证实,blockrecover命令能够有效处理这类棘手的坏块问题。整个复现过程步骤清晰,对于遇到类似“坏块+事务回滚”故障的DBA来说,提供了一个极具参考价值的实战解决方案。
记Redis那坑人的HGETALL
这篇讲的是Redis的HGETALL命令可能引发的性能陷阱。作者从亲身踩坑经历出发,描述了在HASH字段从十几个扩展到一百多个,并使用Pipelining批量获取时,意外导致服务器宕机的过程。 问题的根因在于Redis的单线程模型:当执行HGETALL时,Redis必须遍历每个字段来获取数据,其消耗的CPU时间与字段数量成正比。配合Pipelining一次性发起大量HGETALL请求,单个线程被长时间占用,从而阻塞了所有其他命令,导致服务不可用。 文章随后分析了三种解决思路:引入多线程的Memcached作为缓存层;部署多个Redis实例以利用多CPU核心;或采用序列化字段冗余,将多个字段合并为一个“all”字段存储,从而将多次HGETALL简化为一次HGET,大幅减少操作数。作者最终指出,技术坑就是用来踩的,重要的是从中爬出来并找到解决方法。
数据开发技术概述
这篇讲的是面向海量数据计算入门者的数据开发技术全景。作者冷川从淘宝数据平台及开发技术的演进过程出发,系统梳理了当前主流的数据开发技术栈。 文章的核心在于为我们呈现了一幅清晰的“目前主要的数据开发技术框架图”。它不仅仅罗列技术点,而是结合平台实际场景,讲解了这些技术如何被组织和应用。这对于想建立系统性认知、而非零散了解的同学非常有帮助。 在当前超海量数据的背景下,文章最后抛出了一个关键思路:数据同学不应被动使用技术,而要主动结合系统痛点去思考和推动技术应用。这从单纯的“技术介绍”提升到了“工程思维”的层面,给读者留下了具体的行动方向。
aix使用太多内存导致shared pool 相关latch异常
这篇讲的是AIX系统因内存耗尽引发Oracle数据库性能问题的真实案例。某客户服务器上出现shared pool相关latch的异常等待,系统响应变慢。作者通过nmon和topas工具抓取现场数据,发现物理内存使用率高达99.8%,空闲内存仅剩51MB,同时Paging Space使用了近35%,表明系统正在大量依赖交换空间,这正是导致数据库共享池锁竞争加剧的直接原因。 进一步查看vmo内核参数配置,其值遵循了Oracle官方建议,但根本问题在于物理内存总量(21.5GB)已无法承载数据库SGA、PGA及操作系统进程的消耗。文章分析了特定Oracle进程的内存映射,显示单个进程的SGA占用就非常高。最终指出的解决路径非常清晰:要么为服务器扩容内存,要么在业务允许的前提下,主动调小数据库SGA等内存相关参数,从源头降低内存压力。整个排查过程结合了监控命令与参数分析,是AIX+Oracle环境下一个典型的内存型性能故障样本。

LevelDB 的原理和动机
这篇讲的是LevelDB作为高性能键值存储系统的设计原理和动机。作者从持久化数据到硬盘的基本需求出发,解释了如何在实际场景中平衡写入速度和读取效率。 为了快速写入,LevelDB采用追加方式顺序写入日志文件(Log文件),这避免了随机写入的开销,但导致了数据无序。接着,为了从硬盘中高效读取数据,文章指出必须基于查找算法和局部性原理,将数据排序组织到SST文件(Sorted String Tables)中。 文章进一步探讨了为什么使用多个SST文件而不是单个。为了高效插入数据,每个SST文件只保存一定范围的数据,类似于堆的结构。更深入地,LevelDB引入层次(Levels)结构,将SST文件按层次组织,层次越深文件越多但合并频率越低,从而优化了数据合并过程,减少了每次合并影响的文件个数。 面对查找不存在数据时的性能瓶颈,文章强调了结合布隆过滤器(Bloom Filter)的重要性,利用其快速判定“不存在”的特性,避免了在每一层进行无效查找。通过这些层层递进的设计,LevelDB巧妙地解决了存储系统中写入、读取和查询的关键挑战,为读者提供了关于高效数据结构设计的实用思路。
陈吉平的Oracle职业生涯:兴趣与思考 成败之所系
这篇文章记录的是资深技术专家陈吉平从大学沉迷游戏到成长为Oracle领域专家的完整职业历程。作者以第一人称回忆了从非科班出身,到初入职场作为混沌的VB程序员,再到因兴趣选择数据库方向,最终在Oracle领域扎根的全过程。 文章并非讲解具体技术,而是通过大量真实细节——比如为逃避本专业而打游戏逃课、因800元月薪接下第一个项目、在论坛解答问题养成学习习惯、考取OCP证书——生动刻画了一个技术人员的成长轨迹。其中,如何确立方向、从迷茫转向系统学习、借助社区力量(如CSDN与ITPUB)提升自我等思考,构成了文章的主线。 其核心观点在于,技术的成败与持续的“兴趣”和“思考”紧密相关。从最初对计算机的着迷,到后来面对Oracle学习瓶颈时主动寻找方法、总结经验,这份内驱力和对成长路径的反思,远比起点或背景更重要。这对许多正处于技术学习或转型期的读者,提供了真实而鼓舞人心的参考。
Ubuntu工作机使用FlashCache技术加速
作者从Facebook开源的FlashCache项目切入,介绍如何利用一块闲置SSD为Ubuntu等Linux系统的机械硬盘分区提供缓存加速。文章核心解决的是传统磁盘性能不足的问题,方案是在机械硬盘前放置SSD作为写回缓存:数据先高速写入SSD,再由后台异步同步至机械硬盘,从而在保证数据最终落盘安全的前提下,显著提升大容量存储的读写体验。 具体步骤上,文章详细演示了从获取源码、编译安装模块,到使用`flashcache_create`命令初始化缓存设备、设置开机自动挂载的完整流程。作者以加速`/home`分区为例,提供了清晰的命令行操作指南,并提醒了数据迁移时需注意的权限问题。 文章最后指出了该方案的权衡点:SSD空间将完全用于缓存而非存储文件,因此只适合拥有空余SSD容量的用户。整体而言,这为拥有多硬盘或闲置SSD的用户,提供了一个低成本、高可靠性的系统加速思路。
HBase Thrift 接口使用注意事项
这篇讲的是作者在实际使用HBase Thrift接口(基于0.92.1版本)时,总结出的几个关键陷阱和注意事项,对开发者在实际对接时避坑非常实用。 文章首先强调了字节存储顺序的重要性。由于HBase内部按字典序排序,row key和value中的数值类型在转换成byte数组时,必须严格使用大端序进行打包和解包,否则会导致数据无法正确检索。作者给出了C++和PHP中的具体处理示例。 接着,文章指出了一个在PHP和C++接口中行为差异显著的“TScan设置陷阱”。在PHP中,直接设置属性即可生效;但在C++中,必须通过专用的`__set_xxx()`方法赋值,才能将内部的`__isset`标记置为true,否则服务端会忽略这些设置,导致扫描从头开始。 最后,文章从运维角度提出了两点建议:一是合理配置Thrift Server的并发线程数(通过`-threadpool`参数),避免请求被阻塞;二是当进行带缓存的扫描操作时,需要调大Thrift Server的最大堆内存(`HBASE_HEAPSIZE`),以防止因缓存数据过多而引发内存溢出错误。 这些问题都是实际开发部署中容易忽略的细节,但对系统性能和功能正确性有着直接影响。
HBase集群出现NotServingRegionException问题的排查及解决方法
这篇讲的是HBase集群在压力测试中频繁出现NotServingRegionException,导致读写波动乃至短暂不可用的实战排查经历。作者从实际压力测试中遇到的问题出发,发现当每秒读写量达到几十万条时,客户端会周期性地抛出大量异常。 经过对Master日志的分析,问题的根因被定位到两个关联过程:一是由于rowkey包含时间戳且写入量巨大,导致频繁的Region Split(平均耗时约10秒);二是Split后Region分布不均,进一步触发了自动的Region Balance(平均耗时约20秒)。这两者都会造成Region暂时下线。 为解决这一问题,文章从客户端和服务端两个层面提出了具体方案。客户端侧,可通过设置自动刷写(autoFlush)保留写入缓冲区,或调整重试次数与间隔来增强容错。服务端侧则更为关键,建议关闭自动Balance并选择低峰期手动执行;同时针对Region无限增长的问题,提出了两种根治思路——按天分表或巧妙地将时间戳字段改造为周期循环值,从而实现Region的复用。整个过程提供了清晰的排查逻辑与可落地的解决方案。
ORACLE 12C可以通过expdp导出view数据
这篇讲的是Oracle 12c中一个相当实用的新功能:通过数据泵工具expdp,直接将视图数据导出为类似表的数据文件。 以往,我们想迁移某个视图的数据,通常需要先创建一张临时表来存储查询结果,过程稍显繁琐。而从12c开始,expdp引入了`VIEWS_AS_TABLES`参数。作者在文中用一个完整的实例做了验证:在测试库中创建了一个关联查询的视图`v_xifenfei`,随后使用`expdp`配合该参数,直接将其数据导出为转储文件。接着,使用`impdp`导入时,通过`remap_table`参数,成功地将视图数据作为一张名为`v_xff`的新表导入到了目标库,且查询结果完全一致。 这个功能打通了视图与表在数据迁移工具链上的壁垒,特别适合在数据迁移、环境搭建或数据分发时,需要快速提取某个特定视图“快照”结果的场景,省去了中间建表的步骤,让基于视图的数据迁移变得像操作普通表一样直接和简单。
EXADATA与非EXADATA搭建DATAGURAD关于EHCC特性测试
这篇讲的是一个常见的异构容灾场景:很多企业只有一台昂贵的Exadata机器,但为了数据安全,会用一台普通的非Exadata服务器通过Data Guard来搭建备库。官方宣传的EHCC高级压缩特性是否还能正常使用?作者通过实测给出了答案。 测试环境是Oracle 11g,作者在Exadata主库上分别创建了使用BASIC、OLTP以及各种EHCC(Query Low/High, Archive Low/High)压缩的表。关键发现在于,当Data Guard备库是非Exadata环境时,主库的EHCC压缩效率会显著下降。测试数据显示,此时所有EHCC压缩表的数据块大小都膨胀到了接近无压缩的水平,其压缩效果甚至不如简单的OLTP压缩。 作者分析,这很可能是Exadata的一种智能降级机制:当检测到备库不支持EHCC时,主库会牺牲自身的存储性能(高压缩效率)来确保数据在备库的可读性与安全性。因此,在这种异构DG架构下,使用Oracle自带的OLTP压缩或许是更优选择,既能保证容灾,也能获得更好的整体效率。
Innodb IO优化-配置优化
这篇讲的是如何通过调整 InnoDB 的配置参数,来直接提升数据库的 IO 性能,解决数据库最常见的性能瓶颈。 文章的核心思路很清晰:**尽可能利用缓存来减少随机读,同时通过缓冲机制来平滑和延迟随机写**。作者从这个原则出发,详细拆解了多个关键参数。比如,最重要的 `innodb_buffer_pool_size` 建议分配物理内存的 70%-80% 以最大化数据缓存;`innodb_flush_method` 推荐使用 `O_DIRECT` 以避免双重缓存冲突;而 `innodb_log_file_size` 则建议配大到 256M 以上,来减少 checkpoint 的发生频率。 除了这些核心参数,文章还探讨了 IO 线程、预读策略、脏页控制等更多参数的调优建议,并特别指出了不同版本(如 MySQL 5.6 和 Percona)下的差异。无论你是刚接触数据库调优,还是想系统梳理 IO 相关的配置,这篇文章都提供了实用的配置清单和参数建议,帮助你让数据库这台“引擎”跑得更顺畅。
关于一次导入数据提示的MySQL server has gone away
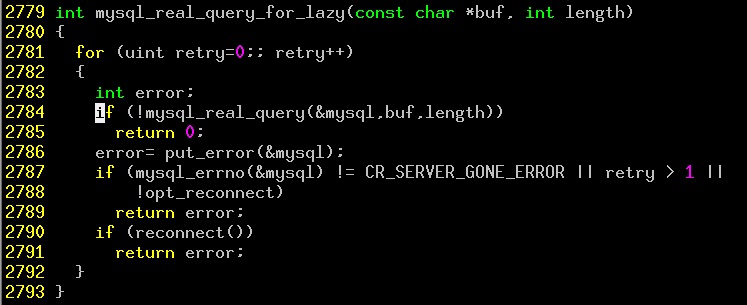
这篇讲的是一个看似平常的数据导入操作,如何引出对 MySQL 一个模糊报错的深度追查。作者从同事遇到的“MySQL server has gone away”问题出发,起初通过调大 `max_allowed_packet` 参数解决了表象。但作者敏锐地抓住了这个错误提示的“不友好”之处:并非所有包过大的情况都会报此错误,有时会有更明确的提示。 为了定位这类模糊报错的原因,作者没有停留在“突然想到”,而是设计了复现场景并深入到 MySQL 源码。分析发现,当 SQL 文件过大导致客户端发送网络包失败时,由于重连逻辑中的一处硬编码(`reconnect` 标志为0),MySQL 客户端库直接返回了 `CR_SERVER_GONE_ERROR`,从而掩盖了真正的错误——“发送通信包失败”。作者还展示了如何使用 GDB 调试获取被隐藏的真实错误码,为类似问题提供了系统的排查思路。 文章的核心在于揭示:一个不友好的错误提示背后,可能隐藏着完全不同的故障链路。与其猜测,不如顺着客户端的连接逻辑和错误处理流程去追溯,这才是定位复杂问题的可靠方法。
由浅入深探究mysql索引结构原理、性能分析与优化
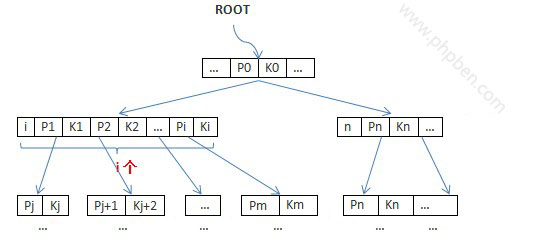
这篇文章系统梳理了MySQL索引的核心原理与实战优化。作者从最基础的索引定义(索引相当于书的目录)讲起,深入对比了MyISAM与InnoDB两种主流存储引擎的索引结构差异。 核心在于B+树的实现细节:MyISAM的索引与数据文件分离,索引叶子节点存储的是指向数据物理地址的指针;而InnoDB采用聚簇索引,主键索引的叶子节点直接包含了完整的行数据,这意味着其二级索引叶子节点存储的是主键值,需要通过主键进行“回表”查询。这一结构差异直接影响了查询性能和内存使用。 文章后半部分聚焦于优化实战,详细拆解了“最左前缀原则”在联合索引中的应用,剖析了ORDER BY与索引配合的五种场景,以及如何通过避免对索引列使用函数、谨慎选择OR/IN等操作来提升查询效率。最后,还涉及了系统配置调优与索引维护的命令。 内容覆盖了从存储结构原理到日常优化技巧的全链路,对理解“为什么这么写SQL更快”很有帮助,适合需要夯实数据库基础或进行性能调优的开发者阅读。
MySQL5.5数据库复制搭建报错之Could not initialize master info structure
这篇讲的是MySQL5.5主从复制搭建过程中,因一个细节疏忽引发的连锁错误排查。作者从一个实际项目出发,由于服务器配置特殊且需求方指定版本,被迫使用MySQL5.5.27,并在配置双主复制时遭遇了两个错误。 首先,因遗漏了中继日志目录的属主变更,执行`CHANGE MASTER TO`命令时报错“File not found (Errcode: 13)”。修正权限后,问题并未解决,错误日志显示“Could not initialize master info structure”,这个提示颇具迷惑性。 经过深入排查,真正的根因浮出水面:数据目录下存在一个0字节的空`master.info`文件,它导致MySQL无法初始化主库信息结构。删除这个异常文件后,再次执行复制配置命令便成功了。文章最后总结道,这个坑的根源在于前期工作不严谨,而解决问题则需要不被表面现象迷惑,进行正反向的深入分析。
数据库的堆表与索引组织表的数据存储格式讨论
这篇文章直接抛出了一个数据库设计中的经典权衡:索引组织表(IOT)与堆表(Heap Table)的存储格式与性能取舍。 核心对比很明确。作者们指出,以InnoDB为代表的IOT,其数据本身按主键有序存储,这带来了主键查询的极致性能,但代价是:频繁的无序插入会导致索引块分裂,批量导入效率低,且主键更新可能引发数据移动和行链接(Row Chain),进而拖慢查询速度。相比之下,堆表的数据是无序存放的,插入稳定,但顺序扫描和范围查询的性能则明显较弱,容易产生大量随机IO。 讨论还深入到了二级索引的维护成本等细节问题,并形成了一个实用结论:IOT更适合那些主键稳定、查询以主键为主、且不频繁更新的表;而堆表则更通用,但在需要顺序扫描的场景下会力不从心。文章通过一场真实的讨论,清晰地剖析了两种存储结构各自的优劣与适用边界,为数据库表结构的选择提供了扎实的考量依据。
WordPress插件开发 -- 在插件使用数据库存储数据
这篇讲的是WordPress插件开发中一个非常实际的问题:当插件需要存储的数据比较复杂时,比如网店的商品订单或音乐播放器的歌单,简单的键值对(Option API)就捉襟见肘了,这时就得直接操作数据库。 文章清晰地区分了两种场景:简单的配置项适合用 `get_option` 和 `update_option` 这类API;而面对复杂的结构化数据,就必须考虑建表。作者没有止步于此,而是引出了解决方案的核心——WordPress内置但未被官方文档化的 `dbDelta` 函数。这个函数设计的巧妙之处在于,它会自动对比你提供的建表SQL和现有表结构,生成并执行 `ALTER TABLE` 语句,从而实现数据库架构的平滑升级,极大降低了维护成本。 为了让说明更具体,文章以一个用于教学的“博客索引生成器”插件为例,详细展示了如何使用这个API为正排和倒排索引创建所需的数据表。整个讲解从背景需求、方案对比到具体实现思路和实例,为需要处理复杂数据的WordPress插件开发者提供了一个清晰、可操作的技术路径。
了解Database Replay Capture内部原理
这篇讲的是 Oracle 11g 中 Database Replay 特性的工作负载捕获机制,作者从实际演示出发,剖析了其内部原理。它揭示了捕获并非被动记录,而是由服务进程主动完成:进程在 PGA(特别是 WCR Capture PGA)中累积会话的登录、登出及 SQL 执行信息,待历史记录达到一定数量后,再主动将数据写入到磁盘上的 WCR 文件中。这个过程中,进程会经历“WCR: capture file IO write”等待事件。 文章也量化了捕获带来的开销:磁盘上生成的是不可直读的二进制文件,在大并发 OLTP 场景下,10 分钟捕获可能占用约 1GB 空间;性能损耗约为 4.5%,且每个会话会额外消耗约 64KB 内存。对于 RAC 集群,共享目录是必须的。 此外,文中还梳理了相关的性能视图与等待事件,例如从 `v$event_name` 中查询所有 WCR 相关事件,以及查看 `v$latch` 中新增的 WCR 闩锁。这些细节展示了该功能在数据库内核中留下的足迹,为深入理解和监控这一特性提供了实用线索。
内存表在同步环境注意事项
这篇讲的是许多开发者在追求查询性能时,可能会考虑使用 MySQL 的内存表(MEMORY 引擎),但在主从复制环境中,这个看似完美的性能优化手段却可能变成定时炸弹。 文章直指几个关键风险点:从库一旦重启,内存表数据清空会导致复制链路中断;主从操作不均衡时,从库可能因临时表空间不足报错;更隐蔽的是,主库重启会主动对内存表执行 truncate,这极易引发主从数据不一致的严重问题。作者从实际经验出发,点明了内存表在同步架构下的脆弱性。 针对这些坑,文中提供了清晰的规避思路。核心建议是优先使用 InnoDB 引擎替代内存表,因为热点数据会被自动缓存在内存,兼顾了速度与可靠性。若业务确实需要特殊配置,可通过复制过滤规则跳过特定表,或将内存表实例与核心业务数据库进行物理隔离,以此消除复制链路中的不稳定因素。 对于正在设计高可用数据库架构的团队,这篇文章提醒我们,选型时不能只看单机性能,必须将数据一致性、复制稳定性等全局因素纳入考量,从而避免为后续运维埋下隐患。