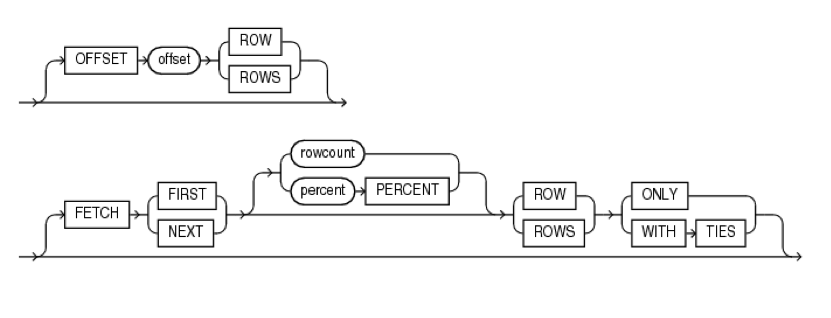
Oracle Database 12c 新特性 - Native Top N 查询
这篇讲的是Oracle数据库在12c版本中引入的一个非常实用的查询优化特性。在12c之前,开发人员若想实现“分页查询”或“只取前N条记录”,通常需要依赖ROWNUM这个伪列进行多层嵌套查询,写法复杂且容易出错,维护成本较高。这几乎是每一个使用Oracle进行Web开发或报表生成的工程师都曾面对过的“经典麻烦”。 Oracle 12c对此给出了一个优雅的“原生方案”:引入了基于OFFSET和LIMIT语法的Top N查询支持。这意味着,过去需要写成多层嵌套的、晦涩的ROWNUM查询,现在可以简化成一条结构清晰、意图明确的SQL语句。例如,直接使用`OFFSET 10 ROWS FETCH NEXT 5 ROWS ONLY`这样的语义化语法,就能轻松实现“跳过前10条,再取5条”的分页逻辑。 这一特性不仅仅是语法糖。它显著降低了编写复杂查询的认知负荷和出错概率,让数据访问层的代码更易读、更易维护。对于那些长期受困于旧式分页查询的团队来说,升级到12c并采用这种新写法,是提升日常开发效率一个很直接的切入点。
MariaDB数据库5.5.27 HASH JOIN源码解读
这篇讲的是MariaDB 5.5.27版本中HASH JOIN特性的底层源码实现。作者从MySQL与MariaDB的分支差异切入,指出MariaDB为优化等值JOIN性能而引入了该特性,并深入其C++源码,拆解了从优化器决策到执行器运行的全过程。 文章的核心在于剖析HASH JOIN的执行逻辑:它如何为内表建立内存哈希表,再逐行探测外表以完成连接。作者特别指出了几个巧妙的设计点,比如在内存压力较大时,系统如何自动切换为分片处理模式,将哈希表溢出写入磁盘,从而在有限资源下完成大表连接。同时,文中也对比了其与MySQL原有Block Nested Loop算法的效率差异,并提供了实际执行计划的对比分析。 对于想理解数据库连接算子如何从算法落地到具体代码的读者,这篇源码解读提供了一个清晰的范本,展示了工程实现中如何在性能与资源间做权衡。
TTS实现跨版本迁移数据
这篇讲的是作者如何利用Transportable Tablespaces(TTS)技术,解决数据库跨大版本迁移这一具体问题。 过去,他对TTS的理解可能停留在理论层面,直到偶然发现这个特性竟能用来做数据库升级——这其实是一个相当实用但容易被忽视的场景。文章以一个真实的测试为例,详细记录了从Oracle 9.2.0.4迁移一个表空间到11.2.0.3的完整过程,平台环境均为Linux 32位。 作者没有空谈概念,而是直接切入实践。核心方案就是利用TTS“表空间传输”的能力,将数据(表空间)从一个旧版本数据库“搬运”到一个新版本数据库,从而绕开常规数据泵导出导入或更复杂的升级路径。这个测试的重点,正是验证在跨了一个大版本(从9i到11g)的情况下,该方法的可行性与具体操作细节。 最终,作者通过实践验证了这一路径的可用性。文章的价值在于,它为需要进行类似数据库升级的DBA提供了一个清晰、经过验证的技术选项,并分享了作者从“理解不深”到“亲手测试成功”的完整认知过程,具有直接的参考价值。
仅仅只备份是不够的
作者从一个常见的技术误区切入:是不是只要部署了数据库、搭配成熟的备份软件(比如NBU、DP、TSM等),再购置大容量磁带库,就能高枕无忧了?文章通过一个真实案例,揭示了单纯备份策略的局限性——即使硬件和软件齐全,若忽略备份后的验证与恢复流程,在实际灾难场景中仍可能面临数据丢失风险。 案例中详细描述了企业虽然拥有完整的备份基础设施,却在恢复阶段遭遇挑战:备份数据无法顺利还原、恢复时间远超预期,导致业务中断。作者指出,根因往往在于备份后缺乏定期测试、未制定清晰的灾难恢复计划,以及对恢复点目标(RPO)和恢复时间目标(RTO)的考量不足。这篇文章强调,备份只是数据保护链条中的一环,完整的策略还需涵盖数据验证、恢复演练和自动化监控。 通过这个案例,作者启发读者重新审视自身的数据保护体系:技术投入固然重要,但流程和制度的完善才是确保数据安全的关键。文章结尾自然引导读者思考如何构建从备份到恢复的闭环方案,避免让备份沦为“摆设”。
一次SQL优化记录
作者在客户现场遇到一个性能糟糕的SQL查询,通过PL/SQL Developer执行时效率极低,影响了业务操作。他详细记录了整个排查与优化过程:首先定位到问题SQL,随后通过分析执行计划,发现表连接顺序不当与关键字段索引缺失是主要瓶颈。针对这两个核心原因,作者分别调整了连接顺序并补建了复合索引,最终使该查询的执行时间从数分钟缩短至毫秒级,优化效果显著。 这篇文章的价值在于它完整呈现了一个真实、典型的SQL性能问题从发现到解决的闭环思路。作者没有停留在简单的“加索引”建议,而是结合具体的执行计划与优化前后的数据对比,清晰展示了如何系统性地诊断和根治数据库查询性能问题。对于日常需要与数据库打交道的开发者和DBA来说,这种一步步分析问题的实战记录,比泛泛而谈的优化原则更具参考意义。
master_pos_wait函数与MySQL主从切换
这篇讲的是MySQL高可用架构切换时一个容易被忽略但至关重要的函数:master_pos_wait。当主库宕机,需要将从库提升为主库时,如何确保这个新“主库”的数据足够新、与原主库保持一致?这是运维人员最焦虑的时刻。问题的根源往往在于,我们可能没有正确使用`master_pos_wait`函数来等待从库应用完所有必要的事务。文章从实际的主从切换故障场景出发,剖析了如果该函数配置不当,会导致数据丢失或复制延迟未被充分消化。作者给出了经过验证的配置方案与执行步骤,明确了在切换流程中应如何设置正确的binlog位点和超时时间,从而让切换过程既安全又可控。这对于搭建高可靠MySQL集群的工程师来说,是一个非常实用的避坑指南。
MySQL 5.6 测试之 Replication(主从复制)
在深入测试了MySQL 5.6的性能之后,作者将目光转向了它的Replication(主从复制)功能,探究其在5.6版本中的表现是否同样令人兴奋。 这篇测评的核心是将MySQL 5.6的主从复制与更早的版本(如5.5)进行对比。作者重点测试了5.6引入的关键改进,例如真正的多线程复制(基于组提交)、基于GTID的复制拓扑管理,以及崩溃安全的特性。文章会详细拆解这些新机制如何运作,并通过实际的测试数据来展示它们带来的延迟降低和运维便利性提升。 通过对比测试,文章旨在回答一个关键问题:MySQL 5.6的主从复制在吞吐量、延迟和可管理性上,相比前代有了多大程度的飞跃?测试结果将揭示这些改进在实际负载下的表现,帮助读者判断是否值得升级。

MySQL优化 之 Discuz论坛MySQL通用优化
这篇讲的是作者如何诊断并优化一个号称日均数百万PV的Discuz论坛MySQL数据库。硬件配置不低(双路至强、16G内存、RAID 1+0),但数据库压力仍然很大,大量请求卡在sending data和statistics状态。 经过深入分析,作者定位了问题的三个核心瓶颈:一是所有数据表都还在使用MyISAM引擎,导致磁盘物理读很高,内存缓冲效果差;二是论坛使用的MySQL官方5.1版本,其InnoDB引擎的队列处理能力较弱,对于已经转换了InnoDB的表,请求排队依然严重;三是部分尚未转换的MyISAM表,其表级锁成为了并发写入的严重阻碍。文章从这些具体的技术痛点出发,给出了对应的优化思路,对于仍在运行老版本MySQL或处理类似高并发读写混合场景的Discuz论坛,有很强的实战参考价值。
MySQL中like语句及相关优化器tips
这篇讲的是MySQL中`LIKE`语句的正确使用姿势以及背后的优化器逻辑。作者从“为什么有些`LIKE`查询能走索引,有些却成了全表扫描”这个问题切入,深入剖析了优化器如何根据匹配模式(前缀匹配、后缀匹配、中间匹配)来决定查询计划。 文章清晰地指出了使用`LIKE`的一个核心原则:尽量使用前缀匹配(如 `'abc%'`),因为这能有效利用索引,避免扫描全表。对于后缀匹配(`'%abc'`)和中间匹配(`'%abc%'`)这两种典型场景,文章分析了它们无法高效利用传统B+索引的原因,并提供了几种实用的替代方案,例如使用反转函数创建函数索引,或者借助全文索引等。 更进一步,文章还揭示了MySQL优化器在处理`LIKE`时的一些“小聪明”,比如如何通过`index dive`或统计信息来估算行数,从而影响最终的执行计划选择。这些细节对于理解查询性能瓶颈至关重要。 无论你是正在编写复杂查询的DBA,还是日常进行SQL开发的后端工程师,这篇文章提供的底层原理和优化技巧,都能帮助你避开`LIKE`语句的性能陷阱,写出更高效的数据库访问代码。
时光荏苒,五年陈酿
这篇讲的是作者在2012年国际爱牙日这天的健康复盘。文章从一次常规体检后的反思切入,记录了去年体检中发现的血压偏高与轻度脂肪肝等问题,今年均已恢复正常,但检查中指出了牙结石的存在。作者由此联想到健康管理中的一个重要细节:许多潜在问题(如高血压、脂肪肝)在通过生活习惯调整后可以逆转,而像牙结石这样的小问题也需主动干预。 作者提出的具体行动是“找个时间去洗牙”,目标是让明年的体检结果更健康。这背后传递出一个朴素但关键的观点:健康不是一次性的结论,而是动态的、需要持续关注与微调的过程。定期复查、对照往年数据、及时处理小隐患,才是长期健康的有效策略。
全球级的分布式数据库 Google Spanner原理
这篇讲的是 Google 如何打造能够横跨全球、又快又稳的数据库 Spanner。作者从传统数据库在跨地域部署时遇到的一致性难题出发,引出了 Spanner 的核心设计理念:用一套统一的系统,同时解决全球分布式数据的一致性、可用性与低延迟问题。 文章深入剖析了 Spanner 的几个关键技术支柱。首先是通过原子钟与 GPS 构成的 TrueTime 机制,为全球所有数据中心提供一个同步的、有误差边界的时间戳,这使得跨区的事务排序成为可能。其次是围绕数据分片与移动的创新,例如通过锁表实现无锁读,以及将数据自动迁移到离用户更近的地方以降低延迟。 最终,Spanner 实现了对外表现为看似单一数据库的体验,同时在底层自动处理了全球范围内的数据复制、分片和故障转移。这对于需要全球级一致性的业务,如金融交易、库存管理,提供了一个兼具强一致性与高可用的基础设施级解决方案。
关于InnoDB索引长度限制的tips
这篇讲的是MySQL InnoDB存储引擎中索引长度限制的实用技巧。作者从一个实际问题出发——有同学遇到了索引长度相关的疑问,然后直接抛出几个关键点进行说明。 文章具体梳理了InnoDB单列索引的最大长度限制(3072字节),以及当使用多列组合索引时,总长度是如何按字符集不同进行折算的。比如对于utf8mb4字符集,一个字符占4字节,那么总长度上限能支持的列数就会相应减少。这些细节在设计和创建索引时非常关键,直接决定了索引能否成功创建,以及查询性能会受到怎样的影响。 作者还提到,在实际开发中,过长的索引不仅会浪费存储空间,还可能影响写入性能,因此需要根据业务场景进行权衡。对于大字段或长文本,文章暗示了前缀索引等变通方案的存在。这些具体的注意事项和边界情况,帮助读者在面对索引设计时能更清晰地做出判断,避免踩坑。
Transfer 2.0 介绍
这篇讲的是 Transfer 2.0 的全面升级,作者从实时
mysql 初探
这篇讲的是,一位有着多年理论学习但缺乏实战的开发者,如何重新打开 MySQL 的世界。文章从作者“温故知新”的视角出发,并未深入某个复杂案例,而是像一位耐心的向导,带读者重新梳理那些最常被提及也最易被忽略的基石概念。 作者回顾的焦点落在了 MySQL 最核心的两个支柱上:底层的 B+ 树索引结构如何决定了查询的效率,以及不同的事务隔离级别在并发场景下各自守护了什么、又可能牺牲了什么。对于许多刚接触数据库或工作后疏于回顾的开发者而言,这些概念或许都听过,但其精妙的设计与权衡细节却容易在日常使用中变得模糊。文章的价值恰恰在于,它以一种“回到起点”的坦诚,把这些知识点重新擦亮,并通过简明的逻辑将其串联。 它没有复杂的架构图或性能压测数据,却为许多“知其然不知其所以然”的日常操作提供了一个理解的基础框架。当再次面对一条慢查询日志或一个诡异的并发 bug 时,重温这些根本性的设计,或许能让人更快地锁定问题所在。
Character set ‘#45′ 导致主从停止问题
这篇讲的是一个在搭建MySQL主从环境时可能遇到的隐蔽坑点。有工程师在配置主从复制时发现,从库总是无法正常同步,复制进程意外停止。排查后发现,问题根源并非网络或权限,而是出在字符集设置上——具体是主库某个表的字符集被错误地设成了`#45`这样无效的值。 这个非标准字符集导致主库产生的二进制日志在从库重放时解析失败,从而中断了整个复制链路。文章不仅指出了这个由特殊字符引发的故障现象,还提供了明确的解决方案:修正表的字符集为正确的编码(如`utf8mb4`),并确保主从配置一致。 对于负责维护数据库架构或处理同步问题的开发者来说,这篇文章提醒了一个容易被忽略的配置细节。它展示了如何通过日志定位一个看似复杂、实则源于基础配置错误的复制故障,具有很强的实战参考价值。
MySQL命令行按Delete键输出”~”的问题
这篇文章直击一个在MySQL命令行中使用方向键和功能键时的常见“小别扭”——当你习惯性地按下 Delete 键期望删除字符时,终端却顽固地输出了波浪线“~”。作者指出,问题的根源在于MySQL默认编译时使用了一个名为 libedit 的库来替代更标准的 libreadline,而前者对部分键盘事件的处理与我们的预期不符。 解决方法清晰直接:重新编译MySQL时,在配置阶段添加 `--without-readline --without-libedit` 这两个参数。这会强制MySQL使用传统的libreadline库,从而完美解决 Delete、Home、End 等键的功能异常问题。这是一个典型的通过调整编译选项来解决运行时交互问题的案例,虽然问题不大,却实实在在影响着日常操作的流畅度。对于需要在终端中频繁与MySQL交互的开发者来说,这个小技巧能省去不少无谓的烦躁。
给MySQL的show table status结果做过滤
这篇文章解决了一个实际开发中常遇到的问题:MySQL的 `SHOW TABLE STATUS` 命令无法直接过滤结果。通常我们只能看到整个数据库所有表的状态列表,当表数量很多时,想快速筛选出特定状态的表(比如查看哪些表引擎是InnoDB、或者估算哪些表可能占用空间较大)就显得非常不便。 作者从这个痛点出发,分享了两种实用的解决方案。一种是借助脚本或自定义工具,先获取全部结果再在本地进行过滤;另一种则更为巧妙,直接通过查询系统信息库(`information_schema`)中的 `TABLES` 表,并结合 `SELECT` 语句的 `WHERE` 子句,来实现类似 `SHOW TABLE STATUS` 且支持灵活过滤的效果。 文章清晰地对比了原始命令的局限性与替代方案的灵活性,特别是通过 `information_schema` 查询的方法,不仅能模拟出表状态信息,还能根据任意字段进行条件筛选,功能更加强大。对于需要管理大量数据表的DBA或开发人员来说,这是一个能直接提升运维效率的小技巧。
Transfer在MySQL数据库双主同步架构中的应用
在MySQL数据库的双主同步架构中,数据一致性和同步可靠性一直是关键挑战,尤其是当两个主库同时接受写入时容易引发冲突。这篇讲的是Transfer工具如何支持双主结构,作者从实际讨论出发,直接给出了肯定答案,并简
布隆过滤(Bloom Filter)-必须了解的优化器算法
这篇讲的是一个因数据库小版本升级引发的性能雪崩事件。作者从一次真实的客户案例出发:将数据库从11.2.0.1升到11.2.0.3,看似无害的操作却导致SQL性能暴跌百倍。根因在于新版本优化器默认启用了布隆过滤(Bloom Filter)特性,这一原本用于优化的算法,在特定查询场景下反而生成了低效的执行计划。 文章核心揭示了优化器自动选择的“双刃剑”效应。作者没有停留在描述现象,而是深入剖析了布隆过滤器如何影响了SQL的执行路径,并给出了关键的应对策略——在版本升级后,必须进行严格的性能回归测试,其中比对SQL执行计划的变化是不可或缺的一环。这提醒我们,数据库升级绝非简单的版本号变动,底层行为的改变可能带来难以预料的后果。 对于DBA和后端开发者而言,这是一个极具参考价值的踩坑记录。它强调了在享受新特性带来便利的同时,必须对其潜在风险保持警惕,并将执行计划分析纳入标准的升级验收流程,以避免类似性能灾难的发生。
创造价值
这篇讲的是一个有趣的思想实验:即使所有交易暂停,财富也可能增长。作者设想了一个“木头人游戏”般的瞬间——假设市场静止,你手里拿着一个坏相机和相同数量的现金。但当你动手把它修好,你的钱一分没多,拥有的东西却实实在在地“值钱”了。这个差额,就是凭空创造出来的价值。 文章由此引出一个被日常交易忽略的核心观点:财富的增加,本质上并不依赖于金钱的流转,而是源于人们通过劳动和智慧改造物质世界、使其变得更有用的过程。一次修复、一次整理、一次创造,都在为整个社会的总财富增量做出贡献。 这或许能帮我们重新审视自己的工作:我们写下的每一行代码、优化的每一个流程,其价值最终都体现在它为世界增加了多少真实的“有用性”,而不仅仅是账面上的数字变动。