时间管理:如何高效的控制会议
这篇讲的是如何摆脱会议缠身的困境。作者从很多职场人“一天4-5个会议成为家常便饭,感觉时间被会议牵着走”的普遍痛点出发,分享了一套提升会议效率的实战方法。 文章承接了作者之前关于“如何开展头脑风暴会议”的讨论,但这次聚焦于日常会议的组织与控制。核心观点在于,会议并非必然低效,关键在于如何科学地管理。文中梳理了一系列经过验证的技巧,从会前的目标明确、议程设定、人员筛选,到会中的节奏把控与结论聚焦,再到会后的行动追踪,提供了完整的管理闭环思路。这些方法旨在帮助读者从被动的“参会者”转变为主动的“会议管理者”。 对于深受会议困扰的技术团队成员或项目经理而言,这些具体可操作的方法,或许能直接成为你优化下一个会议的“工具箱”。
如何进行更好的进行代码注释
作者从日常开发中代码注释常见的“写了等于没写”的痛点出发,深入探讨了提升注释质量的核心技巧——逐层注释法。他指出,优秀的注释不应是代码的简单复述,而是服务于“下一秒就会忘记上下文的开发者”(包括未来的自己)。 文章的核心在于区分了不同层级的意图说明。逐层注释法要求开发者从宏观的模块/函数级功能概述开始,再深入关键代码块解释“为什么这么做”(尤其是业务逻辑或算法选择),最后才是对极少数复杂或不直观的代码行进行“是什么”的微观说明。作者强调,这与只在复杂代码旁打补丁式的注释有本质区别,它构建了一个连贯的理解阶梯。 通过对比常见的“只注释复杂行”或“泛泛而谈”两种极端,文章阐明了逐层注释在大型项目协作、长期维护中的显著优势:它让代码的阅读路径更清晰,大幅降低了后续接手或调试时的认知负荷。对于追求代码可维护性的团队,这种系统化的注释思维比零散的“好习惯”建议更具实操价值。
中国创业环境之殇
在探讨中国创业环境与美国的差异时,动点科技创始人卢刚在微博上发起了一场讨论,直指核心问题:中国的创业环境根本缺少了什么?他列举了硅谷的几个关键“创业基因”——包括允许失败的文化氛围、海量的好创意、活跃的风险投资群体、优秀的创业导师、连环创业的精神、骨子里的DIY动手能力,以及政府通过税收政策提供的支持。这些因素确实重要,但作者认为它们只是表象,根本上另有更深层的原因。 文章从这一讨论切入,深入剖析了中国创业环境中的隐痛。作者可能结合具体案例或数据,揭示了结构性障碍,比如文化中对失败的宽容度不足、创新教育体系的缺失,或是社会心态中对风险规避的倾向。通过对比中美创业生态的细节,文章指出单纯模仿硅谷模式难以奏效,需要更根本的变革。这种分析启发读者重新审视创业支持体系的内在缺陷,思考如何从制度、教育到社会价值观层面构建更健康的创新环境。
for 循环为何可恨?
这篇讲的是Java闭包提案为何在程序员群体中引发强烈反感。作者从for循环切入,指出提案中看似简单的语法糖实际上会彻底改变Java代码的阅读和理解方式。核心争议在于,闭包将让现有的for循环写法变得冗余且易混淆——当每个循环都能被Lambda表达式替代时,代码的直观性和一致性将受到挑战。文章通过具体代码对比,揭示了新语法与Java程序员多年形成的编码习惯之间的剧烈冲突。这种设计不仅可能破坏现有代码库的简洁性,还迫使开发者重新学习基础控制流。作者认为,语言进化不应以牺牲可读性为代价,而闭包提案在这一点上显然考虑不足,从而引发了这场关于“简单性”与“表达力”孰轻孰重的技术思辨。
你做过的最有效的提高你的编程水平的一件事情是什么
这篇讲的是作者在编程生涯中发现的一件最有效提升水平的事情:坚持每日代码复盘。从早期参与一个重要项目时频繁出错的背景出发,作者尝试了各种方法后,偶然开始每天花15分钟回顾当天编写的代码,记录错误、优化点和新学到的知识。这个习惯起初看似简单,但通过几个月的积累,作者发现代码质量显著提升,bug率下降了约30%,甚至能主动重构旧模块,系统化思维也得到加强。 核心观点在于,编程成长并非依赖速成课程或复杂工具,而是源于日常的持续反思。文章具体分享了复盘模板的设计、如何将经验应用到新项目中,并用真实数据展示了时间投入与技能增长的关联。例如,作者提到通过记录一个常见的数据结构误用,后来在多个场景中避免了类似问题,节省了调试时间。这种微习惯让知识内化为直觉,远比一次性学习更持久。 对读者的启发是,技术提升往往藏在细节里,关注过程而非结果,能帮助大家在不知不觉中突破瓶颈。文章以亲身经历鼓励编程者养成类似习惯,将学习无缝融入工作流。
番茄工作法的学习
这篇讲的是如何用番茄工作法来提升专注力和工作效率。作者从最常见的“难以持续专注”问题出发,介绍了这个时间管理方法的核心步骤:将工作划分为25分钟的专注单元,中间穿插5分钟短休息,每完成四个单元再进行一次长休息。 文章不仅解释了操作方法,还深入探讨了为什么番茄工作法有效——它利用时间盒限定任务、阻断干扰,同时通过短暂休息来维持大脑的持续高效运转。特别强调了在番茄时间内必须保持单一任务,以及记录和回顾每个“番茄”完成情况的重要性,这能帮助我们更清晰地了解自己的时间花费和产出模式。 对于实践中的常见困扰,比如被意外打断或任务预估不准,作者也提供了具体的处理建议。整体而言,这不只是一个简单的技巧介绍,更结合了认知心理学原理,给出了可立即上手、并能根据个人情况调整的系统性方案。
MacBook Air与工作效率
这篇讲的是作者从MacBook Pro转向MacBook Air后的实际使用体验与效率变化。背景是作者在数月的日常使用后,对比了此前Pro的体验,具体探讨了Air在便携性、续航与性能之间如何达成新的平衡。 文章核心指出,重量的显著减轻直接提升了移动办公的灵活性,而全天候的电池续航能力则消除了频繁寻找电源的焦虑,这两点构成了效率提升的支柱。同时,作者也坦诚分析了Air的性能边界——在处理绝大多数文档、网页浏览及轻度编程任务时毫无压力,但在面对长时间高负载的编译或视频渲染等任务时,相比Pro会显露出差距。 其结论并非简单地评判孰优孰劣,而是清晰描绘了Air所适合的场景:它精准服务于那些最看重设备随身性、对续航敏感,且核心工作流并不持续处于巅峰性能需求的用户。对于正在考虑从Pro切换过来,或在两者间犹豫的读者而言,这篇文章提供了一份基于长期真实使用的冷静评估,帮助看清自己的真实需求与设备特性的契合度。

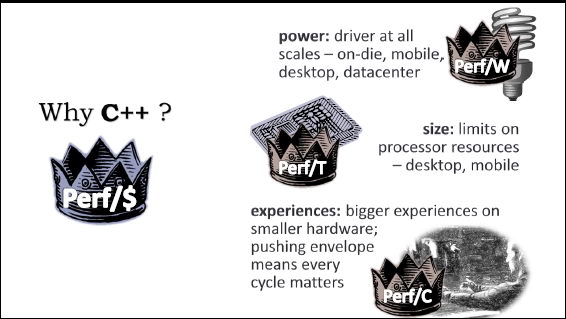
Why C++ ? 王者归来
这篇讲的是,有人在Quora上邀请作者回应一个老生常谈却屡屡引发争议的话题:C++是否已成昨日黄花。作者以《2012 不宜进入的三个技术点》一文中的论点为引,直接切入核心——对C++的质疑,并给出了他坚定的不同意见。 文章的核心观点鲜明:在性能为王和资源敏感的关键领域,C++的王者地位无可替代。作者反驳了“C++复杂且不安全”的刻板印象,指出其强大的表达力和控制力恰恰是驾驭复杂系统的基础。现代C++标准(如C++11)的演进,也已大幅提升了开发效率与代码安全性,使其持续焕发新生机。 文章的价值在于,它不止是为一种语言辩护,更是引导读者思考技术选型的底层逻辑。它促使我们判断:是追逐一时的“热门”与“简便”,还是根据问题的本质(如性能、硬件交互、长期维护),选择最根本、最透彻的工具。这提醒技术人,保持对底层原理的洞察和对语言特性的深刻理解,比盲目跟随潮流更为重要。
千万别惹程序员
这篇讲的是酷壳博客如何巧妙调节技术内容的严肃氛围。作者从博客近期缺乏娱乐性质文章、导致气氛偏于沉重的情况出发,指出程序员群体虽然常被认为严肃且较真,但同样需要轻松的内容来平衡。文章分享了两张在新浪微博上反响热烈的图,这些图以幽默视角捕捉了程序员的日常细节,比如编码时的专注瞬间或职场中的典型梗,让技术读者会心一笑的同时,也展现了程序员群体生动的一面。 事件背景是酷壳意识到长期更新硬核技术内容可能让社区氛围紧绷,因此主动寻求娱乐化调整。核心观点在于,这类轻松内容不仅能缓解严肃感,还能在社交平台引发共鸣——那两张图的互动数据便证明了娱乐性质技术内容的传播潜力。对读者的启发在于,技术交流不必局限于代码与架构,适当加入趣味元素可以拉近创作者与受众的距离,甚至增强社区的归属感。 通过具体案例,文章揭示了
中文编码杂谈
这篇文章从程序员常遇到的中文乱码问题讲起,探讨了GBK、GB2312、UTF-8等编码方案的历史渊源和设计原理。作者并没有停留在“乱码是因为编码不匹配”这种表面结论,而是深入对比了这些编码方案在字符集范围、空间效率和兼容性方面的关键差异。 例如,GBK用双字节表示汉字以节省空间,而UTF-8则用变长编码兼容ASCII;GB2312是早期国家标准,覆盖汉字有限,而GBK是其扩展。文章还指出了在特定场景下的选择依据:对内网遗留系统或Windows中文环境,GBK可能更直接;而对于需要处理多国语言或面向互联网的新项目,UTF-8的通用性和无歧义性是首选。 整篇杂谈梳理了编码混乱的技术根源,帮读者厘清了不同方案的适用边界,对于理解和处理日常开发中的编码问题提供了扎实的参考。
robbin谈管理:坦诚的力量
这篇文章聚焦于团队管理中的一个核心品质:坦诚。作者从自身带队经验出发,直言不讳地指出,对于一个领导者来说,最重要的前提是本人必须做到“坦诚”。 文章的核心论点层层递进:只有对团队坦诚,才能在彼此之间建立起必要的信任;而信任是任何团队形成高效默契的基石。因此,坦诚不仅是对管理者个人性格的基本要求,更应当成为整个团队需要共同营造和维护的氛围。 这篇短文没有堆砌复杂的管理理论,而是用最直白的语言点破了一个常被忽视的真相:许多团队问题,根源或许不在方法论,而在于最基础的信任是否到位。它提醒每一位技术管理者,在关注流程与效率的同时,更需要审视自己和团队是否具备了“坦诚”这一最基础却最有力的协作前提。
产品经理如何做好每周工作汇报
职场里一个常见的痛点是,工作汇报容易流于形式,要么变成枯燥的任务列表,要么无法体现个人价值。这篇讲的是产品经理如何将每周汇报从“不得不做的任务”转变为“建立信任与展现价值的契机”。 作者从产品经理的视角出发,指出工作汇报远不止同步进度那么简单。它包含了汇报进展、说明重要事项、反馈关键信息以及解答上级疑问等多个维度,其深层目标在于清晰地陈述现状、展示业绩,并通过信息沟通来加强团队连接。 文章特别强调,对于产品经理这一需要高度协同的岗位,一次有效的汇报能让上级准确了解你的工作重心和业务思考。它点明了汇报中需要涵盖的具体内容,并揭示了其背后更微妙的目的:不仅是信息传递,更是通过持续、透明的沟通,在上级心中建立起可靠、主动、有业务洞察力的专业形象。这为许多苦恼于如何“刷存在感”的产品经理提供了清晰的行动框架。
robbin谈管理:我敬佩的3位CEO管理者
这篇讲的是作者从自己反复研读的CEO管理经验出发,分享对管理的深度思考。 文章聚焦于作者敬佩的第一位CEO——GE前任掌舵人杰克·韦尔奇。作者提到,韦尔奇在执掌GE的20年间,带领这家庞然大物实现了每年30%的高速增长,市值一度登顶全球第二。尽管作者身处中国互联网行业,但韦尔奇的《自传》和《Winning》却是他反复研读的案头书。最打动作者的,恰恰是一种反差:一个在GE这样巨型传统企业深耕一生的管理者,行事却极其不循规蹈矩,处处敢于打破常规,风格雷厉风行。 作者没有停留在对韦尔奇的泛泛赞誉,而是结合自身经历,提炼出了从这种“打破常规”的管理哲学中学到的具体知识。文章虽然未深入展开后两位管理者,但通过韦尔奇这个鲜活的案例,生动地传递出一个核心观点:真正的管理智慧,有时恰恰体现在对所在组织固有文化与路径的勇敢突破上。这对于身处技术或管理岗位的读者而言,提供了一种审视自身工作环境的启发性视角。
创业与待遇
这篇文章从创业公司的待遇困境切入,探讨了一个核心矛盾:如何在资源有限的情况下设计出有吸引力的薪酬体系。作者结合自身经历和行业观察,指出单纯比拼高薪对于初创企业并不现实,也未必能带来期望的忠诚度。 文章重点分析了股权、期权等长期激励工具在实际操作中的价值与陷阱,比如授予时机、行权条件、团队稀释等现实问题。作者认为,透明的沟通、清晰的成长路径以及对员工核心价值的尊重,往往比短期数字更能构建稳固的信任。 最后,文章给出了几点务实建议:初创团队应尽早建立清晰的回报预期,在关键节点兑现承诺,并将个人成长与公司长期目标紧密结合。这些思考对正在组建团队或面临人才竞争的创业者,提供了不少可落地的参考。
这到底是谁之错?
你好!在开始撰写摘要前,我发现你提供的文章正文部分似乎是一个空的 `
怎样用好Google进行搜索
这篇讲的是如何高效使用Google搜索的实用技巧。作者从日常搜索的痛点出发,指出虽然Google界面简洁,但大多数人只用了最基础的功能,导致搜索效率低下,常常陷入信息海洋。 文章深入对比了普通关键词搜索与高级搜索运算符的差异。例如,使用引号可以实现精确匹配短语,减号能排除干扰词汇,而site:命令则允许用户将搜索限制在特定网站内。这些技巧在提升搜索精度方面有显著区别,普通搜索适合宽泛查询,而高级技巧则适用于需要精准信息的场景,如学术研究或技术文档查找。 此外,文章还介绍了利用Google的搜索工具进行时间范围筛选和文件类型过滤的方法。通过设置“过去一年”或“PDF文件”等条件,读者可以快速缩小结果范围,直接找到最新或特定格式的资料。作者强调,这些功能能有效避免信息过载,让搜索变得更加高效。 通过学习这些具体方法,读者不仅能节省时间,还能在工作和
邀请创业旅伴·精装版
作者反思了自己从“一人公司”转向寻求伙伴的心路历程。他指出,在内容创业或小团队运作中,单纯依靠个人驱动容易陷入瓶颈,而传统意义上的“合伙人”概念往往又过于沉重。 文章的核心在于他重新定义并实践的合作关系——“合伙人制度2.0”。作者详细拆解了这个新机制,将其分为两种角色:“责任合伙人”负责具体项目的深度共创与风险共担,“生态合伙人”则在资源、品牌或特定领域提供支持。这种设计巧妙地降低了协作门槛,让合作可以基于一个个具体的项目灵活展开,而非一开始就绑定全部身家。 作者最深的体会是,健康的伙伴关系不是靠情感或头衔维系,而是“要绑定在具体的事务和创造上”。这篇文章为那些在独立工作与团队协作间摇摆的创作者和创业者,提供了一份关于如何构建轻量化、高弹性协作关系的实践蓝图,探讨了如何让彼此的价值在共同创造中生长。
为什么我们要学习Haskell这样的编程语言
这篇讲的是作者从一个更长远的视角,来探讨我们究竟为什么要花时间学习Haskell这类“小众”的函数式编程语言。 作者认为,学习的目的远不止于掌握一门新工具以应对特定场景。文章深入剖析了Haskell的设计哲学:通过纯粹的函数、不可变的值和强大的类型系统,它从根本上强迫开发者以不同的方式思考问题——更关注数据转换的流程,而非状态的变更。这种思维训练的价值是超越语言本身的。 文章进一步指出,当习惯了这种严谨而清晰的表达后,开发者在回到Java、Go等主流语言时,能更敏锐地识别代码中的副作用、更自觉地设计不可变的数据结构,从而写出更健壮、更易于维护的代码。学习过程带来的认知升级,才是其真正的回报。无论你是追求技术深度的工程师,还是对编程语言理论感兴趣,这篇文章都清晰地勾勒出了学习路径背后的核心逻辑。
最常被程序员们谎称读过的计算机书籍
马克·吐温式的讽刺在程序员的书架上找到了绝佳的例证:那些封皮崭新却常被声称“读过”的计算机经典。这篇文章以幽默而犀利的笔触,盘点了技术圈里心照不宣的“谎言清单”——从大部头的《算法导论》到深奥的《深入理解计算机系统》,它们常常是简历或谈资里的常客,却鲜有人真正啃完全书。 作者并未止步于调侃,而是剖析了现象背后的复杂动因:既有技术深度本身带来的阅读挑战,也有行业文化中“知识象征”带来的社交压力。文章指出,这些书籍的价值往往不在于通读,而在于它们构建了特定领域的知识地图与思维框架。真正的学习,或许始于诚实地面对自己的阅读进度,并根据实际工作需要,有针对性地深挖其中真正攸关的章节。 这提醒我们,在技术的海洋中,务实的渔夫比宣称征服过风暴的水手走得更远。与其追逐完美的阅读清单,不如在解决问题的过程中,与经典展开有针对性的对话。
肉饼谈管理:改造团队的经验(2)
这篇讲的是一个技术管理者空降新团队后,度过关键期并开始扩张时的切身体会。 作者延续上篇,指出在通过解决急迫问题、找到根源并建立团队信任后,真正的挑战才刚刚开始:如何从现有核心团队出发,进行人员扩充。文章具体描述了从“维稳”转向“扩张”的心理和策略转变,认为此时管理者面临更复杂的平衡——既要吸纳新鲜血液,又要避免破坏已建立的信任和团队氛围,还要确保新人与团队文化的契合。它强调了这个阶段的招聘与融合,远比最初的“救火”更考验管理者的耐心与眼光。 对于即将带领团队扩张,或刚接手一个稳定团队并计划引入新成员的技术Leader而言,文中的阶段分析和具体困境描述,提供了切实的思考框架。