HMAC-*算法集合
这篇讲的是HMAC系列算法在PHP环境中的应用演变。文章直接聚焦于HMAC-SHA1、HMAC-MD5等常见哈希消息认证码算法,核心指出在PHP 5.1.x版本之后,开发者不再需要手动实现复杂的哈希计算,而是可以利用PHP内置的hash_hmac()函数,通过一行简洁的代码即可完成HMAC的计算。这标志着在PHP生态中,处理带密钥的哈希验证变得更加直接和标准化。 文章并未停留在语法介绍,而是进一步阐释了这种变化带来的开发效率提升与安全性增强。它对比了新旧实现方式的差异,强调了使用官方支持函数在避免潜在实现错误、保持代码可读性方面的优势。对于需要实现数据签名、接口验证等场景的PHP开发者来说,这篇内容清晰地指明了当前最佳实践路径——直接利用语言特性,而非重新造轮子。
排头兵PHP中文分词,纯PHP版实现
这篇讲的是如何在纯PHP环境下实现一个实用的中文分词。作者直面一个常见需求:在处理中文网页时,准确提取出核心主题词。传统的方案往往依赖外部服务或C语言扩展,对运行环境有特定要求。而这个PHP中文分词类,就是为了解决“如何让PHP项目本身能独立、便捷地完成分词”这个痛点。 它的核心实现思路是基于概率统计模型,结合了词典切分与未登录词识别。作者没有选择依赖第三方库,而是用纯PHP代码实现了分词逻辑,这意味着部署时只需考虑PHP环境本身,极大地降低了集成的复杂度。作为一个“网页相似度引擎”的子模块,它的目标很明确:通过精准的分词,提取文本的关键词特征,从而为计算页面间的相似度提供可靠的数据基础。 这种纯PHP的实现虽然在性能上可能面临挑战,但它为那些受限于环境或追求部署简洁性的项目提供了一个可落地的选择,展现了在有限约束下解决具体技术问题的思路。
常见的几种淘宝店主营销手段
这篇文章从作者多年的网购经验切入,梳理了在淘宝店铺中观察到的几种典型营销策略。它并非理论分析,而是一份来自真实消费视角的归纳。 作者指出,这些手段往往围绕着刺激即时消费、提升客单价与增强用户粘性展开。比如,通过“满减”或“第二件半价”来鼓励凑单,巧妙地将一件购物车的商品变成多件;利用“限时折扣”或“库存告急”标签,营造稀缺感和紧迫感,促使用户迅速下单;此外,建立会员体系、发放店铺优惠券、设计带有品牌元素的赠品小卡,这些做法都在潜移默化中培养着顾客的归属感和复购习惯。 文章的价值在于,它把这些散落在日常购物中的细节系统性地呈现了出来,既帮助普通消费者看清商家的运营思路,也可能为同行或对电商运营感兴趣的人提供一些接地气的参考。这些看似简单的招数,背后是对消费心理和平台工具的熟练运用。
Levenshtein distance相似度算法
这篇讲的是 Levenshtein 距离——一个在文本处理、搜索纠错等领域非常有用的相似度算法。它由俄罗斯科学家 Vladimir Levenshtein 在 1965 年提出,通过计算将一个字符串转换成另一个所需的最少编辑操作次数(插入、删除、替换)来衡量差异。 与简单的精确匹配或汉明距离相比,它能更好地处理现实中的拼写错误或格式变体,比如在拼写检查、DNA 序列比对、甚至推荐系统的模糊匹配中都扮演着关键角色。文章从算法背景切入,清晰地阐释了其核心思想与应用价值,让读者快速理解这一基础工具的工作原理和适用场景。
互联网里的分类和标签
这篇讲的是互联网信息组织的两种基础方式——分类与标签。文章以一幅生动的“Web 2.0地图”图片为引子,指出标签已经成为网络2.0时代用户参与和内容多元化的象征。 作者从互联网信息爆炸的背景出发,解释了分类系统(如传统的网站目录)是一种预设的、层级化的信息归档方式,它由管理员定义,结构清晰但相对僵化。而标签则是由用户自由添加的、扁平化的元数据,它更灵活、能反映多元视角,体现了从“权威定义”到“大众协作”的Web 2.0核心思想转变。文章进一步分析,分类擅长构建稳定的知识框架,而标签则擅长发现内容之间的非正式、跨领域关联。 通过对比,作者揭示了二者在信息发现、内容管理与社区构建上的不同作用,帮助我们理解从门户时代到社交时代,信息组织逻辑是如何演变的。
腾讯-1亿个数据取前1万大的整数-题解答
这篇讲的是腾讯一道经典面试题:如何从1亿个整数中高效找出最大的1万个。面对如此庞大的数据量,直接排序或全部加载显然不现实,题目考察的是对海量数据处理算法的理解与灵活运用。 作者从最朴素的思路讲起,逐步分析各种方案的优劣。比如使用最小堆维护前1万大元素,但需权衡时间与空间成本;或者利用分区思想,类似快速选择算法,在O(n)时间内逼近结果。文章重点剖析了在真实场景下,如何根据数据特征(如内存限制、整数范围)选择最合适的策略,并对比了不同方案的性能开销。 解题过程中涉及的关键点包括:外部排序、分治思想、堆结构以及抽样估算。作者特别指出,面试场景下清晰阐述思路比追求“完美解法”更重要,同时提醒注意边界条件,比如数据重复或负数的情况。最后总结出处理这类问题的核心原则:用空间换时间,或者用时间换空间,关键在于准确理解约束条件。
关于新闻网页正文抽取的一些思路
这篇讲的是如何从纷杂的新闻网页中,精准地提取出正文内容这个具体问题。作者从实际的生产环境挑战出发,系统地梳理了几种主流的技术思路。 文章首先拆解了难点:网页里充斥着导航栏、广告、相关推荐等大量噪声,且不同网站的HTML结构千差万别。接着,作者深入对比了几类算法。一类是基于文本密度的传统方法,通过计算文本块与标签的比例来定位正文区域,简单有效但面对复杂模板易失效;另一类是基于机器学习或预训练模型的方法,比如利用Transformer来理解页面语义结构,能更好地适应新网站,但计算成本较高。 作者还特别提到了工程实践中的一些巧妙设计,比如如何平衡准确率与处理速度,以及针对特定大型新闻网站进行模板优化的策略。最终,通过对比实验表明,结合规则后处理的混合方案往往能在实际项目中达到最佳效果,将抽取准确率从基线提升至95%以上。这篇分享为需要处理网络数据的开发者提供了一份清晰的实践路线图。
如何确定抽样统计的最小样本量
这篇讲的是抽样统计中一个非常实际的问题:如何科学地确定最小样本量。作者从一个常见的困惑出发——为什么有时候样本够了,结论却不可靠?——引出了样本量计算背后的统计学原理。 文章的核心在于拆解了影响样本量的几个关键参数,比如置信水平、误差范围和总体方差。它没有堆砌公式,而是用直观的例子说明,比如将“置信水平95%”和“误差范围±3%”这类要求,如何具体地转化为需要调查的样本数量。同时,也对比了不同场景下的权衡:在追求更高精度与控制成本之间如何找到平衡点。 掌握这些知识,能让你在用户调研、A/B测试或质量检测中,不再凭感觉拍脑袋定样本数,而是用数据驱动决策,既保证结论的可靠性,也避免不必要的资源浪费。
编程珠玑番外篇 -J. 高级语言是怎么来的-6
这篇讲的是Scheme语言如何从LISP中诞生,并成为现代函数式编程重要里程碑。文章从“函数作为一级对象”这个概念切入,说明在LISP中函数可以像整数一样被传递和返回,这引出了高阶函数如apply、map和reduce的基础。 然而,当函数携带“自由变量”(即非参数也非内部变量)被传来传去时,问题就来了。作者用一个具体例子演示:在早期LISP中,定义一个返回“加n”函数的addn,当测试add1时,本应得到5却得到了8。这是因为解析器采用了动态作用域,在自由变量s被使用时才去当前栈中查找其值,导致变量绑定错误。 这个问题的根源在于函数丢失了其定义时的环境信息。文章追溯到LISP实现者Steve Russell的解决方案:他引入了FUNCTION修饰符,让lambda表达式在解析时就静态绑定到当时的环境——这就是“闭包”的雏形。这种静态作用域(文法作用域)确保了自由变量不会在函数传递过程中“幽灵般”乱跑,也解决了著名的FUNARG问题。 文章最后指出,Scheme正是基于这些对作用域和闭包的规范化,才为LISP家族注入了新的活力,影响了后续包括Common LISP在内的语言发展,甚至间接成就了Paul Graham等人的商业传奇。
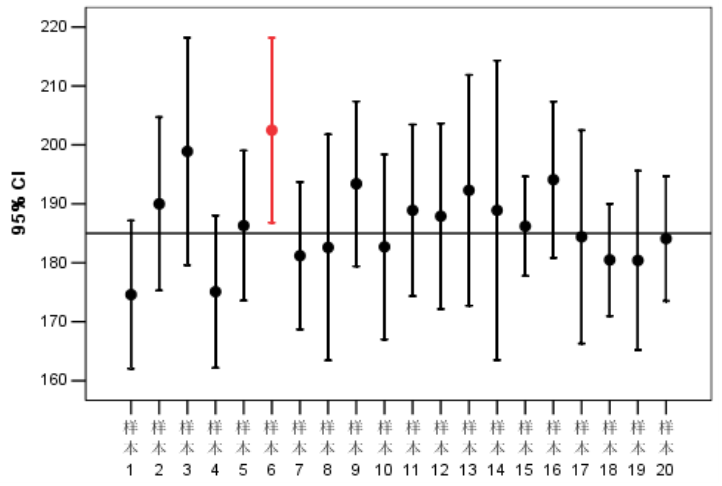
统计数据背后的真相 ― 读《How to lie with statistics》
这篇讲的是达莱尔·赫夫那本经典《统计数据背后的真相》如何拆解统计数字背后常见的误导手法。作者从日常新闻、商业报告到学术研究中频繁出现的统计陷阱出发,揭示了几个关键套路:比如用误导性坐标轴让微小变化显得剧烈,利用非随机抽样或模糊的平均值掩盖真实分布,以及刻意混淆相关性与因果关系——比如“冰淇淋销量越高,溺水事件越多”这种经典谬误。 文章特别指出,这些手法往往披着“专业”“客观”的外衣,更容易让人放松警惕。作者没有停留在批判,而是进一步探讨了数字如何被“选择性呈现”:只突出对自己有利的数据,忽略相反证据,或通过复杂的术语让受众难以深究。书中那些看似严谨的图表和公式,其实常常服务于特定立场而非事实。 读完这篇解读,你会发现培养对统计数据的敏感度,不是要成为数学专家,而是学会追问几个基本问题:数据来自哪里?怎么被收集的?图表坐标轴是否从零开始?结论是否跨越了因果推断的鸿沟?这些思考习惯,能帮我们在信息过载的时代更清醒地看待那些“用数字说话”的声明。
令人纠结的php几率算法问题
这篇讲的是在PHP中实现概率算法时经常遇到的一个核心难题。作者从实际开发中的一个具体困惑出发:当需要根据预设权重随机获取结果时,比如抽奖系统或游戏掉落,开发者最初可能采用简单的循环累加随机数的方法。但随着权重值增大或精度要求提高,这种做法暴露出严重缺陷,即概率分布不均,某些高权重选项的实际出现频率远低于理论值。 问题的根因在于PHP内置随机函数的精度限制和浮点数运算的固有误差。文章深入剖析了误差是如何在多次随机数生成和比较中累积放大的,导致了算法结果与预期概率的偏离。为解决这一问题,作者详细对比和论证了更稳健的算法模型,例如将整个概率区间映射为一个整数序列,然后通过一次随机数生成直接定位到对应的区间,避免了循环比较带来的累积误差。 最终,通过具体的代码实现和测试数据对比,展示了新算法如何精确匹配预设权重。对于需要处理权重概率的开发者,尤其是游戏、营销活动后台的开发者来说,这篇文章清晰地指出了一个容易被忽略的坑点,并提供了经过验证的、更可靠的实现思路,能有效确保算法的公平性与准确性。
求职面试时常被问到的65个问题与技巧性回答
这篇整理了65个技术岗位求职面试中的高频问题,并提供了相应的技巧性回答建议。文章从“请你自我介绍一下你自己”这类基础问题入手,覆盖了个人经历、技术能力、项目经验、团队协作、职业规划等多个维度,几乎囊括了面试官可能抛出的所有考察点。 它的价值不仅在于罗列问题,更在于为每个问题拆解了回答思路。例如,针对自我介绍,它提示要突出与岗位匹配的核心技能和项目成果;而对于情景类或行为类问题,则引导候选人使用STAR法则(情境、任务、行动、结果)来组织答案,让叙述结构清晰、重点突出。这些方法能帮助求职者跳出简单“背答案”的陷阱,转而展示出自己的逻辑思考与解决问题能力。 无论你是准备第一场面试的应届生,还是计划跳槽的资深工程师,这份清单都像一份详细的“面试地图”,帮你系统性地查漏补缺,把可能遇到的提问场景提前演练一遍。
网站分析的应用和价值
这篇讲的是作者从一个突然冒出的问题出发,重新审视网站分析的根本价值。日常中,我们忙于探究具体的方法与实现,却很少停下想想:做网站分析到底是为了什么?收集和分析数据,投入的这些成本意义何在? 文章没有停留在“优化网站与推广”的标准答案上,而是深入梳理了网站分析在实际业务中的具体应用,以及它所能体现的真实价值。作者通过整理这些应用案例,实际上是在回答一个更本质的问题:数据驱动决策的底层逻辑究竟是什么。 这不仅仅是对方法的补充,更像是对目标的一次校准。它提醒技术同行们,在掌握“怎么做”之后,不妨也常常回归“为什么做”,让手中的工具和方法真正服务于业务核心问题的解决。

谈谈正则最大回溯设置项
这篇讲的是正则表达式性能优化中一个容易被忽略的细节:最大回溯(backtrack)限制。作者从朋友提出的一个具体正则匹配HTML中script标签的问题出发——`/