Lua GC 的源码剖析 (5)
这篇讲的是Lua垃圾回收器中一个关键机制的实现细节:write barrier(写屏障)。在增量式GC中,为了保持对象图的一致性,当程序修改一个可能被GC扫描的对象的引用时,需要额外进行标记处理——这就是write barrier要解决的问题。 文章没有停留在概念层面,而是直接切入源码。作者从`luaC_barrier`等函数入手,剖析了Lua GC中三种不同类型的写屏障(普通写屏障、快速写屏障和表写屏障)的具体实现逻辑。比如,对于表的操作,屏障会判断被修改的值是否为白色(未标记),并将相关对象加入一个“gray”列表,确保后续的增量扫描不会遗漏。 最巧妙的部分在于这种“即时记录”的思路:与其在GC周期结束后费力重扫整个对象图,不如在每次可能产生不一致的写操作时,就即时、低成本地记录下变化。文章通过源码展示了这种权衡是如何在性能和正确性之间取得平衡的,对于想理解动态语言GC底层工程实践的人来说,提供了非常扎实的参考。
Lua GC 的源码剖析 (4)
这篇讲的是Lua垃圾回收(GC)中至关重要的标记(mark)过程实现。作为系列分析的第四篇,作者从GC的整体流程切入,将镜头聚焦到标记阶段:它如何从根集合出发,精准地标记出所有存活对象,同时避免程序在运行中修改对象引用而导致标记错误。 文章的核心在于剖析Lua采用的“三色标记法”与写屏障(write barrier)机制的协同工作。作者通过源码走读,展示了灰色、黑色、白色对象状态之间的转换逻辑,以及当黑色对象被赋予白色引用时,写屏障如何“拦截”并记录这一变化,确保后续能正确标记。实现上,Lua为不同状态的对象维护了不同的链表,这种设计让遍历和状态转移都十分高效。 更巧妙的是,Lua针对不同对象类型(如表、字符串、闭包)采用了差异化的标记策略。例如,对于表的标记会递归处理其键值对,而字符串则利用其不可变性简化了流程。这种细致的实现兼顾了正确性与性能。作者在剖析中也点出了这种设计背后对运行时效率和代码复杂度的权衡思考,让人看到一个高效GC背后的精巧工程实现。
内容的个性化与信任感
这篇从Digg CEO宣称要打造“量身打造的新闻网站”这一观点出发,探讨了在追求内容个性化的同时,一个更根本的问题:信任感如何维系?作者敏锐地察觉到,这种“个性化”的承诺在当下并不新鲜,许多平台都在推行。文章的核心观点在于,纯粹的算法驱动的个性化,极易将用户困在“信息茧房”里,导致认知偏狭。而更深层的困境是,当内容完全迎合用户既有偏好时,平台赖以立身的客观性与公信力将遭受侵蚀。作者认为,真正的挑战并非技术上的“千人千面”,而是在满足个体信息需求与构建公共信息空间之间找到平衡。这启发我们反思,在信息过载的时代,我们消费的内容是被精心“喂养”的结果,还是主动探索的收获?平台的责任,或许不止于让我们“看得爽”,更在于帮助我们“看得全、看得准”。
趣题:能否把三维空间分成无穷个圆?
这篇讲的是一个看似简单却暗藏玄机的几何趣题:我们能不能用无数个彼此绝不“触碰”的圆形,把整个三维空间严丝合缝地填满?作者从这个经典的二维平面问题出发,探讨将其推广到三维世界时会遇到的根本性挑战。 核心冲突在于,圆是一个二维图形,而空间是三维的。这意味着,无论这些圆如何排列,它们必然需要“悬浮”在不同的高度或角度上。问题的关键变成了,这些悬浮的圆所占据的空间体积,能否恰好填满整个三维空间而不留空隙,也不相互重叠。作者引导读者思考圆的几何定义及其在三维中可能呈现的形态。 经过分析,结论是这实际上无法实现。因为圆在三维中无论怎么摆放,其本质仍是二维的,无法真正具有“体积”来填充三维空间。任何一个空间点,要么在某个圆的平面上,要么就不在。要完全覆盖三维空间,需要的是具有体积的三维实体,而非平面图形。这个看似巧妙的设想,最终揭示了维度差异带来的根本限制。
我理解的运营
这篇讲的是作者对运营工作的深度理解,不同于常见的方法论堆砌,而是从一线实践中提炼出的底层逻辑。文章开篇就直指运营的核心矛盾——如何证明“用户增长”与“价值留存”的因果关系,并坦诚分享了自己早期只关注拉新数据的教训。 作者重点拆解了运营思维与产品、技术思维的关键差异:产品关注功能闭环,技术追求实现优雅,而运营必须始终锚定“人”的动态反馈。他以曾负责的某个社区冷启动项目为例,说明运营者需要像数据侦探一样,从用户行为轨迹中反向推导真实需求,而非依赖主观假设。 更值得关注的是,文中提到运营的终极价值不是简单地执行动作,而是构建可复用的“增长模型”。通过搭建自动化用户分层机制,团队将原本依赖人工经验的干预,转化为能持续迭代的数据策略,使后期转化率提升了近40%。这种从重复劳动到系统构建的转变,或许才是运营人进阶的关键。
Lua GC 的源码剖析 (1)
这篇讲的是 Lua 虚拟机中最核心的自动内存管理模块——垃圾回收器(GC)是如何从源码层面实现的。作者从 GC 的核心目标(自动回收无用内存)出发,直接深入到源码实现,详细拆解了其工作原理。 文章重点剖析了 Lua GC 采用的“三色标记”算法,并解释了其中“写屏障”这一巧妙机制如何保证在并发标记阶段不会遗漏存活对象。作者还梳理了 Lua GC 如何通过增量回收和分代回收等策略,在保证回收效率的同时,努力降低对程序运行造成的卡顿影响。 整篇分析不是泛泛而谈,而是紧扣源码中的数据结构和函数调用,把“标记-清除”、“增量更新”这些抽象概念与具体的代码逻辑对应起来,清晰地展现了 Lua GC 在简洁性与高效性之间进行权衡的设计思路。
创业与梦想
这篇探讨的是创业浪潮中“梦想”这个关键词的真实分量。作者从互联网史上那些标志性的创业传奇切入,梳理了从雅虎、谷歌到Facebook的共同轨迹:它们都诞生于校园的一隅,却凭借改变世界的愿景成为了全球巨头。这种叙事深刻影响了如今的创业文化,使得“有激情、有梦想”成了许多初创公司招聘时的标配口号。 文章并未停留在复述传奇,而是将视线拉回现实,剖析了这种“梦想驱动”模式背后的复杂性。它指出,当“梦想”被简化为一句响亮的口号时,可能忽略了创业过程中至关重要的执行能力、技术积累与市场洞察。作者提醒我们,真正的创业精神,既需要仰望星空的勇气,也离不开脚踏实地的耕耘,尤其是在一个创业已从特殊现象逐渐成为普遍选择的今天。 对于读者而言,这篇文章的启发在于,无论身处创业洪流还是职场生涯,都不应将“梦想”与“激情”空洞化。它鼓励我们更理性地审视驱动自身行动的核心要素,思考如何将宏大的愿景转化为扎实的、可执行的步骤,从而在充满不确定性的旅程中,找到属于自己的坚实道路。
一些有意思的贴子和工具
这是一篇典型的资源集合类推荐。作者延续了CoolShell上杂项分享的风格,将近期在互联网上发现的各种新奇有趣的网站、工具和讨论帖子汇编在一起。不同于专题文章,它的价值在于精心筛选后的“发现感”。 文章涵盖了从实用开发工具到脑洞大开的在线项目,可能包括提高效率的命令行神器、设计独特的Web应用,或是程序员社区里引发热烈讨论的深度帖。作者并非简单罗列链接,而是为每个资源附上了简短的个人点评或背景说明,帮助读者快速判断其趣味点和实用价值,节省了大家自行发掘的时间。 这种持续更新的杂项集合,就像一个不断扩展的“有趣事物清单”,非常适合技术爱好者作为日常灵感的来源,或者在工作间隙换换脑子时浏览,总能从中发现一两个让你眼前一亮的东西。
搜索引擎知多少
这篇从国内用户的上网习惯出发,细致拆解了百度、Bing、搜搜等主流搜索引擎的差异。文章没有停留在简单的功能罗列,而是从首页面设计、搜索结果质量、信息更新速度等多个维度进行了对比分析。比如,它指出百度在中文内容覆盖和生态整合上优势明显,而Bing在学术搜索和国际信息获取上表现更佳,搜搜则依托腾讯社交链在特定场景下有独特价值。作者不仅分析了现状,还点出了这些差异背后的产品逻辑,帮助读者理解不同工具适合解决哪些具体问题。如果你想搞清楚日常用的搜索工具到底“特在哪”,这篇分析提供了一个很清晰的参照框架。
漫话折纸几何学
这篇讲的是折纸与尺规作图的“实力对决”。文章从一个关于“用纸片折出等边三角形”的热门讨论切入,直指那个引发争论的核心问题:折纸凭什么在几何构造上比经典的尺规作图更强大? 作者并没有停留在现象,而是回溯了折纸几何学的历史脉络,带我们看到两者的根本差异。尺规作图有其明确的“能力边界”,比如三等分任意角或折出正七边形这类经典难题,它就无能为力。而折纸,通过其特有的公理体系(比如可以同时对折来确定某些点),实际上能解决更多、更复杂的几何问题,这背后有坚实的数学理论支撑。 文章梳理了这些历史与原理,让人明白折纸并非儿戏,而是一门被严格研究的几何学科。它解释了为何那些看似“神奇”的折法其实是必然可行的,也为我们理解几何学的边界提供了另一种有趣的视角。读完会对“折纸”这件事,产生完全不一样的技术认知。
另类称球趣题:验证砝码所标克数的正确性
这篇讲的是一个经典的逻辑推理问题:如何仅用两次天平称重,来验证六个标有1至6克重量的砝码是否准确。很多人拿到这个题目时,第一反应可能是尝试所有组合,但这显然效率低下。 文章作者巧妙地从一个全局条件切入——这六个砝码的标称总重是21克。基于这个确定值,解题的关键思路在于如何设计两次称重,使得每一次都能揭示出矛盾的可能。例如,第一次称重可以比较某几个砝码与另一组的总重,通过是否平衡来缩小范围;第二次则针对第一次的结果,设计更具针对性的组合来检验。 最精彩的部分在于,作者揭示了这种验证方法背后的数学原理:它本质上是在用“总重已知”这个约束,去检验所有可能子集的组合关系是否唯一成立。两次称重方案并非随意选择,而是能构成一组逻辑上严密的“校验方程”。即使存在标错的情况,这套方法也能准确地指出问题所在。这种用有限次操作解决全局验证问题的思路,体现了逻辑推理中“以巧破繁”的魅力,对理解如何设计高效验证方案颇有启发。
STL可能的误用-find_first_of和erase
这篇技术文章聚焦于C++ STL中`string`的`find_first_of`函数常见的误用场景。作者从开发者容易混淆`find_first_of`与`find`的区别出发,点明了问题的根源:仅从名称相似性推断函数行为会导致逻辑错误。 文章的核心在于澄清这两个函数的关键差异。`find_first_of`并非查找整个子串,而是在目标字符串中搜索参数字符串中任意一个字符首次出现的位置。相比之下,`find`用于查找整个子串。这种细微的语义差别,正是代码中隐蔽bug的来源。 接着,文章深入讲解了与`erase`配合使用时可能出现的陷阱。例如,当意图删除找到的子串时,若误用`find_first_of`定位,后续计算起始索引和长度时就极易出错,导致非预期的删除范围。作者通过具体的代码示例,展示了这种误用可能引发的运行时错误或逻辑漏洞。 通过剖析这些日常编码中可能忽略的细节,文章不仅指出了“病症”,更提供了明确的“解药”——准确理解每个STL函数的行为规范。对于经常处理字符串操作的C++开发者来说,这能帮助其写出更健壮、可维护的代码。
(麻省理工免费课程)计算机科学和编程
这篇推荐的是MIT OCW平台上的经典入门课“计算机科学和编程(6.00)”。作者体验了课程后,最强烈的感受是讲解极为系统,能带来“一通百通”的贯通感。 课程从编程基础讲起,但不止于语法,而是系统性地构建计算机科学的思维框架。作者特别提到,观看后能明显感受到国内计算机教育与MIT这类课程在体系化和思维训练上的差距。这是课程超越单纯“写代码教学”的价值所在。 课程视频托管在YouTube并配有字幕,意味着国内访问可能需要借助一些网络工具。对于已经具备一定基础的计算机专业学习者而言,理解内容会比较顺畅。这篇推荐适合所有希望从源头扎实理解计算机科学核心思想、而不仅仅是学习一门语言的初学者。它提供的是一张值得深入探索的知识地图。
打印质数的各种算法
这篇博客深入探讨了打印质数这一编程经典问题的多种算法实现。作者从算法设计的基础出发,系统对比了试除法、埃拉托斯特尼筛法以及欧拉筛法等主流方法,帮助读者理解不同策略的核心思路与适用场景。 文章重点分析了每种算法的关键差异:试除法通过逐个检测整数是否被整除来判断质数,实现简单但时间复杂度较高,适合教学或小规模数据;埃拉托斯特尼筛法则利用标记合数的方式批量筛选,显著提升了效率,尤其适用于生成较大范围内的质数列表;欧拉筛法进一步优化了筛法的内存使用和速度,在大数据场景下表现更优。作者还结合了具体代码示例和时间复杂度分析,揭示了算法从“暴力枚举”到“智能筛选”的演进过程,突出了权衡代码简洁性与运行效率的编程智慧。 通过这些对比,文章不仅提供了实用的技术参考,更启发读者在编程中思考如何根据实际需求选择最优解,培养算法优化意识。
人脸识别算法综述-(LPP,PCA,K-L,SVM)
这篇综述直面人脸识别领域的核心问题:如何从庞杂的算法中理清脉络,并评估其实际效果。作者没有停留在理论介绍,而是直接以工业界世界级人脸测试数据为基准,点明了当前技术发展的真实水平。 文章的技术剖析从二维与三维两个视角系统展开。在二维特征提取层面,详细对比了PCA(主成分分析)通过全局降维捕捉主要特征、LPP(局部保留投影)侧重维护数据局部几何结构的差异,并阐释了K-L变换在特征选择中的作用。对于分类决策环节,则重点剖析了SVM(支持向量机)如何有效处理高维特征并实现精准分类。这些经典算法构成了现代人脸识别系统的基石。 更难得的是,文章不仅横向对比了算法特性,还纵向梳理了从二维到三维的技术演进路径,最终落脚于对算法发展趋势的判断。这种结合了客观测试数据、关键技术拆解与未来视野的写作方式,为读者提供了一个既扎实又清晰的认知框架,能有效帮助工程师在项目选型时做出更合理的权衡。
m进制转换为n进制-任意进制转换算法
这篇文章聚焦于编程面试中频繁出现的任意进制转换问题,即如何将m进制数高效转换为n进制数。作者没有停留在简单的十进制转换案例上,而是直击核心:提出一套通用的算法思路,能处理从二进制到三十六进制等任意基数间的转换。 算法的核心在于将问题拆解为两个可复用的步骤。首先,将输入的m进制字符串按照“权值叠加”的原理,逐位计算并累加,转化为一个中间十进制数值。紧接着,再将这个十进制数通过经典的“除基取余”法,不断对目标基数n取模并逆向拼接,得到最终的n进制字符串。巧妙之处在于,这套两步走的流程将一个复杂问题标准化,无论基数如何变化,底层逻辑都保持一致。 这种实现不仅思路清晰,也极大地提升了代码的通用性和可维护性。文章通过这道经典的面试题,实际上深入浅出地讲解了数制本质与编码思维,对巩固算法基础很有帮助。
一个Sqrt函数引发的血案
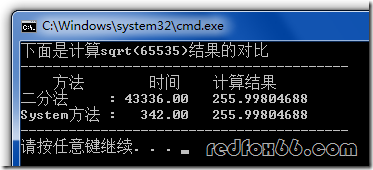
这篇讲的是一个常见数学函数背后的性能奥秘。作者从“我们平时如何计算sqrt”这个朴素问题出发,带读者一路探索了三种实现方案的性能差异,堪称一部微型算法演进史。 文章先从最直观的二分法讲起,虽然结果正确,但性能与系统函数相差几百倍。接着引入牛顿迭代法,性能大幅提升,但仍与系统实现有差距。真正的高潮来自那个被称为“Fast Inverse Square Root”的神奇函数——它利用了浮点数的二进制表示与整数的位运算,仅用几行位操作和一次牛顿迭代,就实现了比系统函数更快的倒数平方根计算。 这个诞生于《雷神之锤3》引擎的算法,其核心魔力在于一个神秘的魔法数字(0x5f3759df),背后涉及对浮点数结构的深刻洞察。文章不仅解析了其精巧的实现,还追溯了它从游戏代码到学术论文的传奇故事,揭示了理论数学与工程实践在极致优化需求下的美妙碰撞。
谷歌(Google)2011年校园招聘笔试题
这篇整理了谷歌2011年校园招聘笔试的典型题目,涵盖算法、数据结构和系统设计等多个方面。不同于普通习题集,它特别剖析了每道题考察的核心能力:比如用“数字游戏”题测试抽象建模思维,用“海量数据处理”题考察分布式计算思路,以及如何用简洁代码实现高效算法。文中不仅给出了标准解法,还对比了不同解题路径的时间与空间复杂度,点明哪些思路更符合谷歌对工程效率的偏好。对于准备技术面试的读者,它提供了一个窗口去理解顶级科技公司如何通过笔试题筛选出兼具理论基础和工程思维的人才。
SNS背后的科学(4)―― 信息的传播
这篇文章继续SNS背后的科学系列,聚焦于信息在社交网络中的传播机制。作者从基础的传播模型入手,详细解释了信息如何沿着社交关系链扩散,以及不同网络结构(如小世界网络、无标度网络)对传播路径与速度的影响。 文章重点剖析了几个关键影响因素:用户活跃度与连接强弱决定了初始扩散的范围;内容的“社交吸引力”(如情感强度、实用价值)则影响其被转发和二次传播的可能性。通过具体的模拟数据和案例,作者指出,在强弱关系交织的复杂网络中,信息往往不是均匀扩散,而是依赖少数高连接度的节点实现“跳跃式”传播,这解释了为何某些话题能迅速引爆。 文中还对比了不同传播模型的适用场景,例如疾病传播模型(SIR)与信息扩散在机制上的异同。对于内容创作者或运营者而言,理解这些底层逻辑,有助于更有策略地设计内容与触达路径,而不仅仅是追逐表面的“爆款”。
用正方形纸片折出等边三角形
这篇讲的是如何仅凭一张正方形纸和几次折叠,就能精确得到等边三角形。作者从一个经典的几何问题出发:在没有量角器的情况下,如何构造一个60度角?文章没有依赖复杂的数学推导,而是展示了一个纯手工的解法。 核心在于折纸步骤的巧妙设计。它并非简单的对折,而是通过特定的对齐与压痕,利用正方形纸片本身的比例关系,间接“计算”出等边三角形所需的边长与角度。过程中涉及到了勾股定理与黄金比例的隐含应用,但最终通过直观的折叠动作得以实现,把抽象的几何原理变成了指尖可感的步骤。 这种折法体现了数学与手工的美妙结合。它告诉我们,精确的几何图形并不总是需要尺规,有时候,一张纸本身就藏着答案。理解这个过程,不仅能收获一个实用的折纸技巧,更能体会到几何构造背后那种简洁而优雅的思维乐趣。