较安全的rm脚本
这篇讲的是作者针对Linux系统中误删文件这一常见痛点,分享了一个经过安全强化的rm脚本。在默认环境下,rm命令直接删除文件且没有回收站机制,用户一旦误操作就可能面临数据永久丢失的窘境,这在运维和开发工作中尤其令人
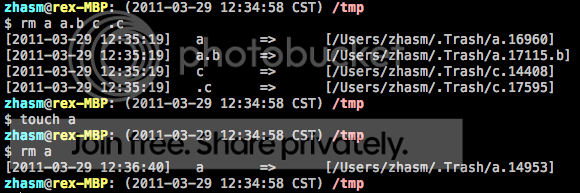
这篇讲的是作者针对Linux系统中误删文件这一常见痛点,分享了一个经过安全强化的rm脚本。在默认环境下,rm命令直接删除文件且没有回收站机制,用户一旦误操作就可能面临数据永久丢失的窘境,这在运维和开发工作中尤其令人
这篇讲的是一个轻松实用的bash练习:作者通过编写一个脚本,来统计最近在终端中使用过的linux命令。虽然作者坦言这“没什么具体用途”,但它恰恰展示了一个清晰的实践目标——熟悉bash环境和命令行操作的痕迹。 文章的核心是一个小巧的脚本实现。它利用Linux系统中的历史记录功能,提取并分析用户最近的命令输入。你可以想象,这个脚本会遍历你的命令历史,进行排序、去重或者计数,最终生成一份使用清单。这不仅仅是统计,更是对shell编程中文本处理、循环和管道等基础技能的一次综合练习。 对于初学bash的开发者来说,这类小项目非常有价值。它从一个非常个人化、可感知的需求出发,让你在实现“统计自己用过什么”这个过程中,不知不觉地巩固了脚本编写的多个知识点。文章本身更像是一份作者的练习笔记,展示了一个从想法到简单实现的小闭环,对于想动手但不知从何开始的读者,或许能提供一种朴实的启发。
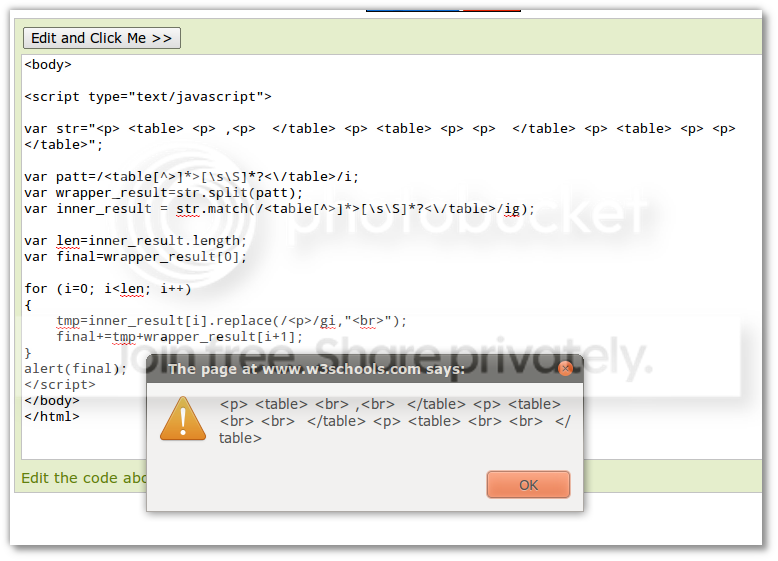
这篇讲的是如何用纯正则解决JavaScript里一个挺棘手的字符串替换难题。网友wys提出了一个具体需求:如何在只用JS原生正则的前提下,完成对嵌套结构(比如多层括号或标签)的匹配与替换。这类操作常规的正则方法往往力不从心,容易出错或无法覆盖复杂情况。 文章的核心方案,是作者深入剖析了正则引擎的执行逻辑,特别是“捕获组”与“零宽断言”的组合运用。他没有推荐更复杂的解析库,而是专注于挖掘语言本身的特性。通过一种巧妙的“延时替换”或“模式迭代”思路,让正则表达式能够“看穿”一层层的嵌套,并在正确的层级执行替换操作,既保证了准确性,又兼顾了性能。 最巧妙的地方在于,整个解法优雅地绕过了正则表达式通常无法匹配“任意嵌套”结构的理论限制。作者的思路为处理这类层级文本提供了轻量级的新视角,展示在熟悉工具底层原理后,能激发多少创造性用法。
这篇书评是作者对几本主流正则表达式书籍的实战评测与心得提炼。作者没有泛泛而谈,而是直击核心:从《精通正则表达式》的深度与权威,到《正则表达式必知必会》的简洁高效,再到《正则表达式经典实例》的场景化解决方案,他都结合自身学习与应用经历,剖析了每本书的独特价值与侧重点。例如,他提到《精通正则表达式》是构建系统知识体系的“圣经”,而《必知必会》则像一本快速上手的实用手册,特别适合项目救急。这种基于个人阅读体验的对比,清晰指出了不同书籍在内容深度、写作脉络和目标读者上的差异。对于想学习正则却不知从何入手的技术人来说,这份“排雷”指南能帮助他们根据自己当前的需求——是追求原理贯通,还是需要快速产出——来做出最高效的选择。
这篇讲的是如何用一个Python脚本,精准统计混合文本中汉字和英文单词的数量,并按出现频率排序。 程序的核心任务是处理同时包含中英文的文本文档。作者需要解决两个基础问题:一是准确区分汉字与英文单词,二是分别统计它们的出现次数。实现上,可以利用字符编码范围来识别汉字(例如,在UTF-8或Unicode中,汉字有特定的码点区间),并使用正则表达式来匹配和提取英文单词。 更进一步,统计结果需要逆序排列,即让出现频率最高的汉字或单词排在最前面。这可以通过构建字典或使用Python的collections.Counter来计数,再结合sorted函数根据值(频率)进行排序。其巧妙之处在于,这种区分处理和频率排序能让文本的特征一目了然——无论是分析一篇文章的用词风格,还是快速了解一段代码注释或用户反馈的语言构成,都能立刻抓住重点。 整个实现虽然代码量不大,但逻辑清晰,从字符识别到频率分析形成了一个完整的闭环。对于需要快速处理混合语言文本数据的场景,这是一个非常实用的工具雏形。
这篇讲的是作者从零实现一个中文分词程序的过程和思路。中文分词看似简单,实则挑战不少——没有明确的词边界,歧义切分和未登录词识别更是难点。作者没有调用现成库,而是选择用最大匹配算法来构建一个最小可运行版本,核心思路很直接:维护一个词典,每次从句子中切分出与词典匹配的最长词语。 文章具体演示了正向最大匹配和逆向最大匹配两种实现。通过对比测试,作者发现逆向匹配在处理某些特定歧义结构时效果更佳。更有趣的是,作者并未止步于此,而是进一步思考了算法的局限性,比如词典大小对性能和覆盖率的直接影响,以及这类基于规则的算法在面对复杂语境时的天花板。 整个实现过程清晰展现了编程解决问题的典型路径:将抽象问题拆解为具体步骤,用数据结构和循环控制来实现核心逻辑。对于想了解分词基础原理或练习算法实现的读者来说,这个从简陋到可用的过程本身就是一个不错的参考。
这篇讲的是邮件系统的垃圾过滤与论坛防灌水技术的内在联系。作者从一个比较有趣的角度切入,把这两个看似不同场景下的反垃圾实践放在一起对比讨论。 文章重点从技术层面展开,没有延伸到运营或法律等其他维度。你可以看到,邮件反垃圾主要依赖发件人信誉、内容特征(比如关键词、链接分析)和机器学习模型的动态学习,目标是在海量邮件中高精度识别并过滤垃圾邮件。而论坛防灌水更侧重于实时性,常用验证码、发帖频率限制、行为模式分析(比如短时间内重复发帖)等手段,更强调拦截的即时效果。 尽管目标一致(都是对抗垃圾信息),但两者在技术路径上各有侧重:邮件系统更注重长期、批量的模型准确率,而论坛则需要平衡用户体验与即时防护。这种对比能帮助读者理解,反垃圾策略如何根据不同的应用环境和攻击模式进行适配。