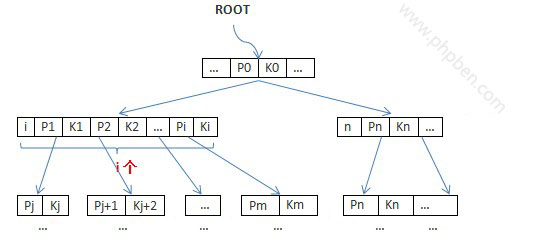
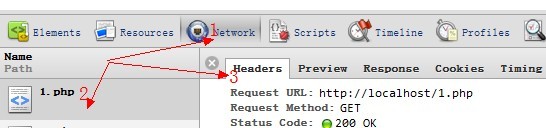
php缓存与加速分析与汇总
这篇讲的是PHP网站缓存加速的实战指南,作者基于Win7+Apache+PHP的测试环境,从浏览器端缓存机制入手,深入剖析了HTTP头域中Expires、Last-Modified与Etag的工作原理与差异。文章通过浏览器监听的实际截图,清晰展示了首次请求、未过期缓存命中以及304状态码等不同场景下的网络交互细节。 作者对比了Apache处理静态文件与动态文件的默认行为差异,并详细演示了通过PHP代码设置 Expires 头域来实现时间缓存的具体方法。更有趣的是,文章还探讨了在PHP中同时设置Expires与启动Session时出现的一个特殊缓存现象,揭示了看似简单的缓存设置背后可能隐藏的复杂交互。整体内容基于作者的亲自动手验证,将理论与实际监听结果相结合,对理解前端性能优化中的浏览器缓存策略有不错的参考价值。