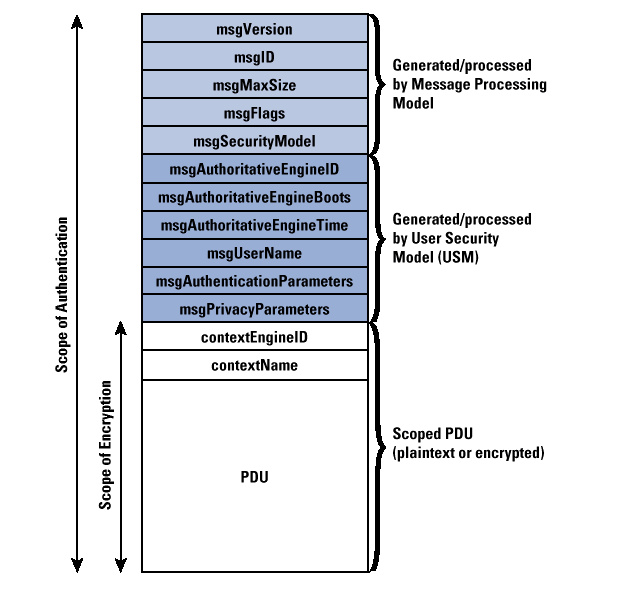
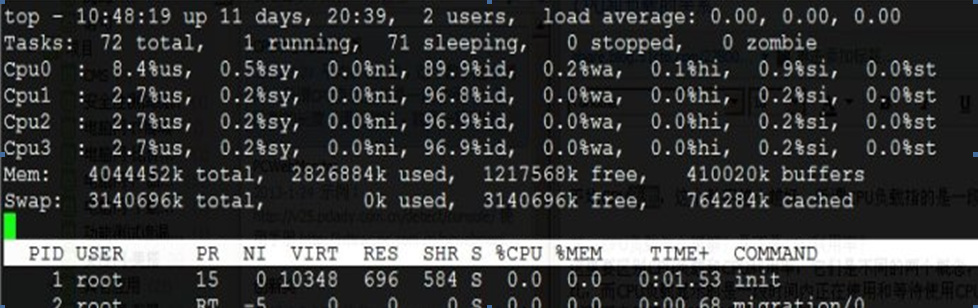
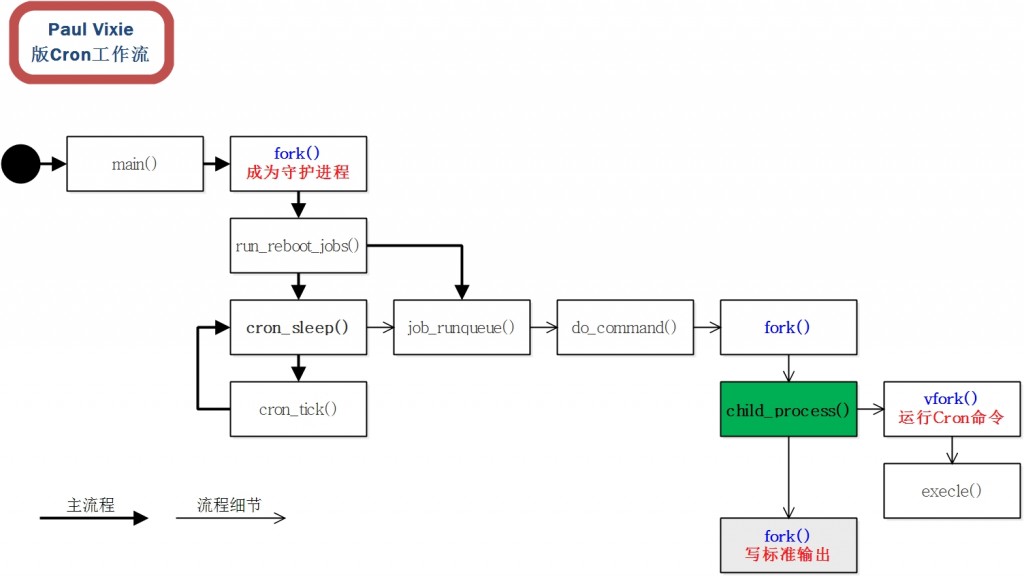
Linux发展编年表
这篇讲的是Linux如何从芬兰学生Linus的个人项目,一步步成长为驱动当今世界的关键力量。作者用一条清晰的时间线,梳理了这个“24年计算机革命”中的关键节点。 摘要里,你可以看到Linux内核的第一个版本如何诞生,以及为何Linus认为将它切换到GPL协议是“做过的最正确的事”。文章也记录了早期关于微内核与宏内核的著名论战,以及第一个成功发行版Slackware和Debian的出现。从Red Hat开始商业化,到Google搜索引擎基于Linux构建,再到2007年Android的发布,文章勾勒出Linux如何从服务器走向桌面、手机和云端。 这些里程碑事件不仅是技术演进,更是一段开源社区与商业力量交织的成长史。文章最后停在2013年Valve推出基于Linux的SteamOS,记录了Linux在游戏领域的新尝试。整篇文章像是为开源爱好者准备的一份详尽档案,让读者能直观感受一个理想如何改变世界的技术底座。