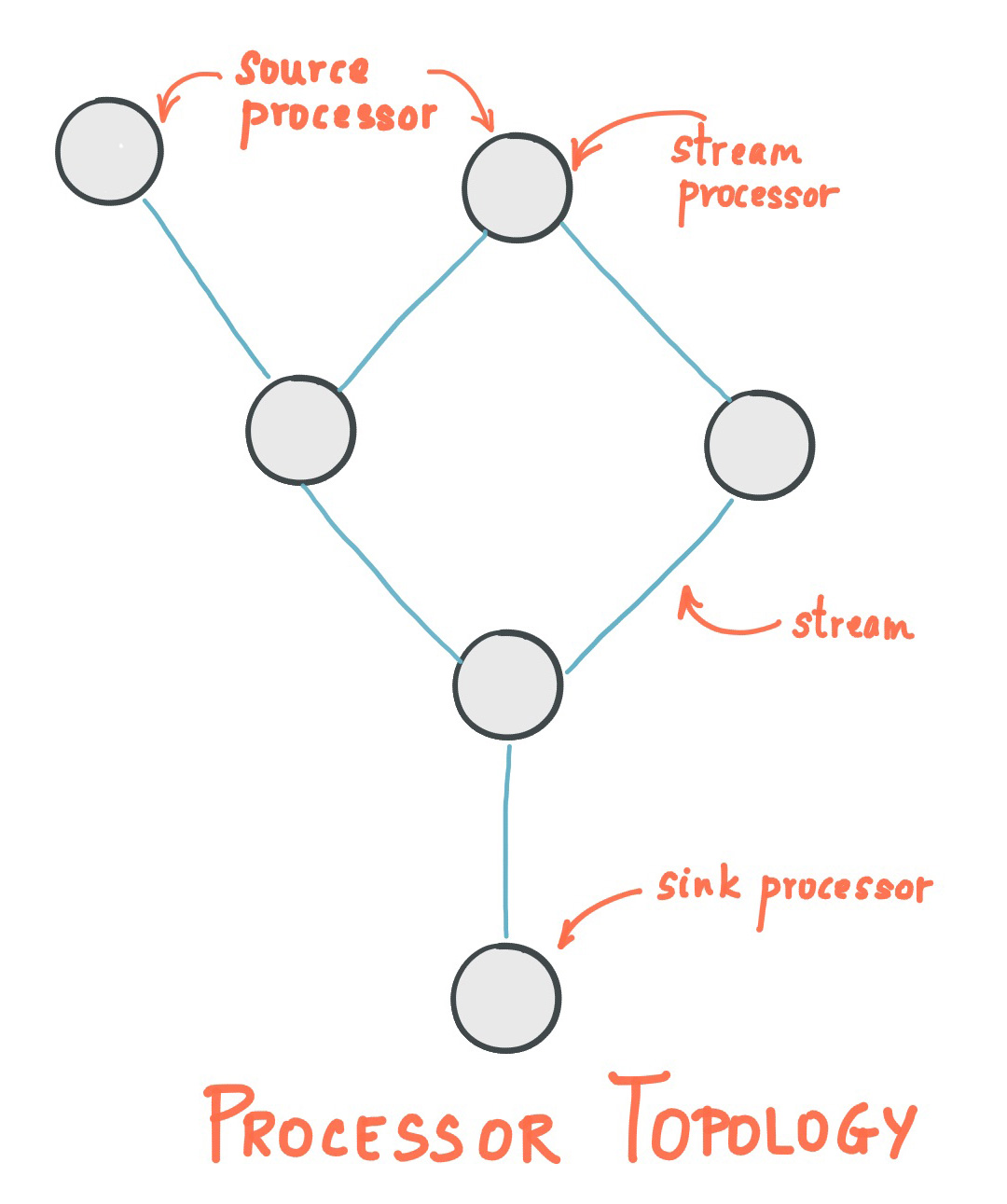
TCP 滑动窗口 与窗口缩放因子(Window Scaling)
这篇讲的是TCP滑动窗口协议中一个常被忽略但影响重大的参数:窗口缩放因子(Window Scaling)。文章指出,TCP窗口字段本身只有16位,最大值为65535字节。在“高带宽-长延迟”的网络中,这个上限会成为性能瓶颈——比如在10Mbps、单向延迟80ms的链路上,理想窗口需要约100KB,但65KB的窗口迫使发送方必须等待确认,白白浪费了带宽。 为了解决这个问题,窗口缩放选项被引入。它通过在TCP握手中协商一个“缩放因子”,将接收到的窗口值左移该因子位,从而将最大窗口理论上扩展至约1GB(缩放因子最大为14)。文章通过计算示例说明,原先65KB的窗口经过缩放后,能够匹配高带宽网络的实际吞吐需求。 作者在实战中也验证了其效果:对一个上传服务进行调优,增大TCP缓冲区并启用窗口缩放后,上传一个8MB视频文件的时间从1分30秒显著缩短至20秒,体现了在特定网络环境下对此参数进行调优的实际价值。