Erlang公平调度的误解
这篇讲的是Erlang引以为傲的“公平调度”哲学,在实际工程中可能并不像想象中那么完美。作者从Erlang虚拟机(BEAM)的时间片分配、抢占式调度说起,点明了它在云计算等场景下保障用户体验的初衷。 但文章的重点在于“祛魅”。作者指出,尽管Erlang的BIF、NIF等模块都在努力维护公平,但一些基础设计环节却可能无意中打破这种平衡。例如,消息队列的无保护单向队列结构,在极端负载下可能导致队列暴增和内存激增;而内存分配器在向系统申请内存时使用的锁,以及SMP架构下难以避免的锁竞争,都可能成为公平性的破坏者。文章最终总结,这些实现细节上的“坑”影响了Erlang在某些情况下的公平性表现,也解释了为何近期Erlang引入dirty scheduler等新机制来应对。 作者最后将视角拉高,提醒架构师需从上到下,在业务层面也进行“公平”设计,才能与系统哲学和谐统一。世界没有绝对公平,但理解其边界至关重要。
erlang和其他语言读文件性能大比拼
这篇讲的是不同语言在处理大文件读取时的性能较量,主角是Erlang。作者从公司一次技术比武的真实案例出发——有同事用Erlang处理1.1GB文本的词频统计耗时55秒,而用C只需2.6秒,Java为3.2秒——引出了一个普遍疑问:Erlang读文件真的这么慢吗? 为了重新验证,作者准备了一个1GB的测试文件,详细对比了多种读取策略的性能。数据很有说服力:在单线程缓冲读取模式下,Erlang耗时0.322秒,与C语言的dd命令(0.264秒)处于同一量级;而启用多线程并发读取后,耗时缩短至0.214秒,性能甚至超越了C语言。但反例也很明显,如果以4KB小块读取,耗时会骤增至3.56秒,性能急剧下降。 文章揭示了性能差异背后的核心机制:Erlang的文件IO通过efile驱动实现,本质是轻量级的C封装,但每次操作都涉及“发消息→驱动执行→等待结果”三个阶段。这种设计在IO操作粒度过小时,消息传递开销会被放大,违背了Erlang“小消息,大计算”的原则。因此,性能的关键在于使用大块缓冲区读取,并充分利用异步线程池并行化IO,从而将Erlang的IO性能推到理论极限。
Linux下如何知道文件被那个进程写
这篇讲的是一个运维中常见的棘手场景:Linux下文件持续增长,但用lsof等工具却找不到对应的写入进程。作者从一位同学的实际困扰出发,指出问题的普遍性,并给出了一个基于内核视角的解决方案。 核心思路是,既然用户态工具难以追踪(可能是进程很快打开又关闭了文件),那就直接在内核的虚拟文件系统层进行监控。文章推荐使用SystemTap工具包中的inodewatch.stp脚本,它通过探测vfs.write事件,能根据文件所在的设备号(major/minor)和inode号,精准定位到正在执行写操作的进程。 作者随后用一个生动的实验进行了演示:用dd命令在后台持续写入一个测试文件,通过stat命令获取其inode和设备信息,然后运行stap脚本。终端立刻输出了正在执行vfs_write的dd进程信息(进程名、PID),瞬间“破案”。整个排查过程清晰直观,展现了SystemTap在内核级故障排查中的强大能力。
Erlang集群全联通问题及解决方案
这篇讲的是Erlang集群一个看似“贴心”但可能致命的设计:默认全联通。 作者从Erlang集群节点加入时的“引荐”机制讲起,新节点会被介绍给所有现有节点,从而建立一个完全连接的网状拓扑。问题在于,这种全联通连接数(N*(N-1)/2)会随节点数增加而爆炸式增长,不仅消耗大量系统资源,更因定期的心跳检测引发网络风暴,严重制约集群规模。 解决这个问题的方案出人意料地简单:在节点启动参数中加入“-hidden”标志,使其成为“隐藏节点”。如此一来,节点间的连接不会被主动发布,从而有效避免了不必要的全联通。 不过,作者特别提醒了一个关键细节:隐藏节点的行为是“或”逻辑——只要通信双方中有一方是隐藏节点,global模块就不会进行自动引荐。这个特性在实际部署和故障排查时必须留意。文章最后指出,社区已开始正视并规避这一设计带来的问题,对从事大规模分布式Erlang开发的工程师来说,这个经验颇具价值。
Erlang集群RPC通道拥塞问题及解决方案
当Erlang集群采用默认的全联通架构时,节点间通过RPC通道的密集调用可能引发严重的通道拥塞。文章从社区主流的分层服务架构出发,指出大量节点间消息流易导致dist端口忙,进而阻塞发送进程——由于RPC模块基于单进程gen_server,这种阻塞会直接拖累系统响应时间。 作者指出,这类问题可通过`erlang:system_monitor`的`busy_dist_port`事件及时感知,例如Riak系统便利用此机制告警。解决关键在于调整`dist_buf_busy_limit`参数:默认1MB的分布缓冲区上限可能不足,通过启动参数`+zdbbl`将其调大(如Riak案例中增至8MB),即可显著缓解阻塞、提升吞吐。文章结合监控实践与参数调优案例,提供了从问题定位到彻底解决的完整路径。
gen_tcp发送缓冲区以及水位线问题分析
这篇讲的是一个线上 Erlang 服务器遇到的具体困惑:为什么按预期,客户端发送第 4 字节就该阻塞,实际上却到了第 7 字节才阻塞?作者从这个问题出发,深入剖析了 gen_tcp 的发送缓冲区与水位线(high_watermark/low_watermark)机制。 文章指出,理解的关键在于 ERTS 内部 port 的消息队列模型。发送数据(send)实质是向 port 发消息,当队列数据达到高水位线时,port 进入“忙碌”状态,调用者进程会被挂起,直到数据降至低水位线。文章结合参数设置详细推演了缓冲区与水位线的实际交互过程,并澄清了一个常见误解:高水位线更多是一个“软”限制,用于流程控制,而非精确的阻塞点;最终发送端的阻塞,很大程度上取决于接收端的 recv 行为。 作者通过源码与机制分析,将配置选项、内部数据流与观察到的行为串联起来,为理解 Erlang 网络编程中的流量控制提供了清晰的视角。
gen_tcp如何限制封包大小
这篇讲的是如何在Erlang的TCP服务器(基于gen_tcp)中,从底层实现上来限制单个数据包的大小,以防范潜在的安全风险和资源耗尽问题。 文章从两种包接收模式入手。对于同步接收({active, false}),作者指出,当使用gen_tcp:recv时,实际上内核会为接收分配一个缓冲区。通过源码可以看到,这个缓冲区大小存在一个硬编码的上限:TCP_MAX_PACKET_SIZE(64MB),一旦请求超过此限制,就会直接返回ENOMEM错误。这可以看作是系统级的防线。 而对于更常见的异步消息投递({active, true}),控制则发生在协议解析层面。通过inet:setopts设置的packet_size选项,会在数据解析时被检查。文章通过追踪tcp_remain等函数的源码揭示了这一机制:当解析器发现包头声明的长度超过了设定的psize值,这个数据包就会被判定为无效。 核心巧妙之处在于,这两种机制一个在缓冲区分配时卡住,一个在协议解析时拦截,共同构成了对包大小的纵深防御。文章通过解读底层C驱动代码,让读者清晰地看到这些看似简单的应用层选项是如何被严格实现的,对于需要定制或深入理解Erlang网络编程的开发者来说,提供了扎实的内部视角。
gen_tcp接收缓冲区易混淆概念纠正
这篇讲的是 Erlang/OTP 中 `gen_tcp` 模块几个缓冲区参数之间的常见混淆。很多开发者看到 `buffer`、`sndbuf` 和 `recbuf` 这三个选项时容易困惑:它们到底是什么关系?文档的简要说明往往不足以理清头绪。 作者选择直接深入 C 驱动层源码(`inet_drv.c`)来寻找答案。通过分析 `inet_set_opts` 函数的实现,文章揭示了核心事实:`sndbuf` 和 `recbuf` 设置的是内核 Socket 层的发送与接收缓冲区大小,这符合常规理解。而 `buffer` 选项则完全不同,它设置的其实是 Erlang VM 内部、应用层用于暂存从 Socket 读上来的原始数据的缓冲区大小提示(`desc->bufsz`)。 文章一个巧妙的发现是,源码中存在自动调整逻辑:当显式设置 `sndbuf` 或 `recbuf` 后,`buffer` 的值会被自动更新为两者中的较大值,以确保应用层缓冲区足够容纳内核传上来的数据。但其影响范围仅限于接收路径——因为发送数据可以利用队列,无需类似的额外缓冲。 通读全文,它厘清了一个关键结论:这三个参数分属不同层级,`buffer` 专注于控制 Erlang 侧接收数据的临时缓存大小,其默认值和动态扩容策略都围绕接收场景设计,而不直接影响内核的 Socket 缓冲区。对于需要精细调优 TCP 通信性能的开发者,理解这层区别至关重要。
whatsapp深度使用Erlang有感
当很多人还在争论Erlang是否过于小众、能否胜任大规模商业系统时,WhatsApp用事实给出了响亮的回答。这篇文章分享了作者对WhatsApp深度使用Erlang技术栈的观察与思考。 文章的核心是一个极具说服力的案例:一个以Erlang为主的后台架构,支撑了数亿用户。作者通过引用WhatsApp主要开发者Rick Reed的分享,揭示了一个有趣的成长故事——这位有深厚系统性能背景的工程师,在2011年加入WhatsApp时竟是一位Erlang新手,但短短两三年后,他已能将Erlang的虚拟机、集群、Mnesia数据库等特性运用到极致。 文中列举的数据令人印象深刻:仅用两台服务器承载百万级的长连接、Mnesia数据库支撑起巨大的数据集,以及背后惊人的消息吞吐量。作者指出,Rick Reed的工作并非创造了全新的魔法,而是将Erlang已知的特性进行了系统化整理并坚决落地于商业系统,这是从理论到实践的巨大飞跃。 文章最终的结论很直接:任何系统开发到最后,都是在操作系统和硬件能力的边界内解决同类问题,Erlang为解决高并发、高可用等特定规模问题提供了坚实的基础。作者鼓励读者停止对它的怀疑,因为它在正确的场景下确实能带来巨大的价值。

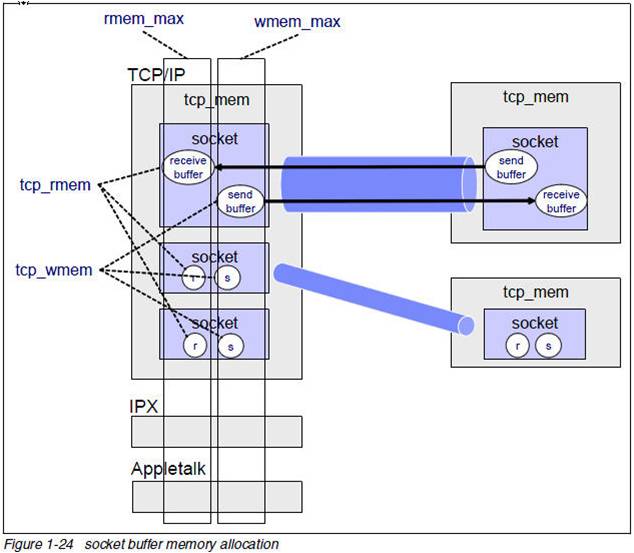
网络栈内存不足引发进程挂起问题
这篇讲的是高并发场景下,一个隐蔽但影响巨大的“坑”:当服务器需要支撑C1M(百万)级别连接时,TCP服务可能出现超时,甚至高达100ms的延迟。 问题的根源往往在于Linux内核的网络栈内存。文章开篇就点明,TCP的发送和接收缓冲区并非“想设多大就多大”,它们受到一系列sysctl参数(如net.ipv4.tcp_mem)的全局控制。这些内存是不可交换的物理内存,用一点少一点,系统默认值通常偏保守。在连接数暴涨时,可供分配的内存很快耗尽。 一旦内存不足,进程向socket写入数据时,内核就会将其挂起(阻塞),并调用 `sk_stream_wait_memory` 函数等待内存释放。文章直接展示了如何用SystemTap脚本精准定位这一过程——脚本输出会清晰地显示进程“blocked on full send buffer”和“recovered”的时间点,这就是导致应用层超时的直接证据。 最后,文章给出了行动指南:如果观测到了这种内存等待,就需要着手调整协议栈的内存限制参数。它通过一个具体的案例强调,面对复杂的网络问题,定量的工具与分析比猜测更可靠。
nicstat 网络流量统计利器
这篇讲的是 nicstat 这个被称作“网络接口的 iostat”的流量监控工具。作者从 Brendan Gregg 的性能分析 PPT 引出它,详细说明了如何将这个原本在 Solaris 下的工具移植并安装到 Linux 环境中。文章核心对比了 nicstat 和常见的 netstat,指出其关键优势在于:能同时报告字节与数据包流量、将数据归一化为每秒速率、统计所有接口、并尝试估算网卡利用率(%Util)与饱和度(Sat)。这些特性让实时监控和诊断更直观。 文中展示了具体的安装过程(需针对64位系统修改编译参数)和多个使用示例,例如用 `enicstat -l` 查看网卡状态,用 `-M` 切换为兆比特单位显示,以及用 `-t` 获取 TCP 连接统计。特别值得注意的是,nicstat 通过读取 `/proc/net/dev`、`snmp` 等文件来获取数据,并提供了如重传率(%ReTX)、连接数等 TCP 层面信息,对排查网络问题很实用。文章最后也坦诚说明了在 Linux 下其饱和度统计的局限性,提示读者结合使用率和数据包速率进行综合判断。
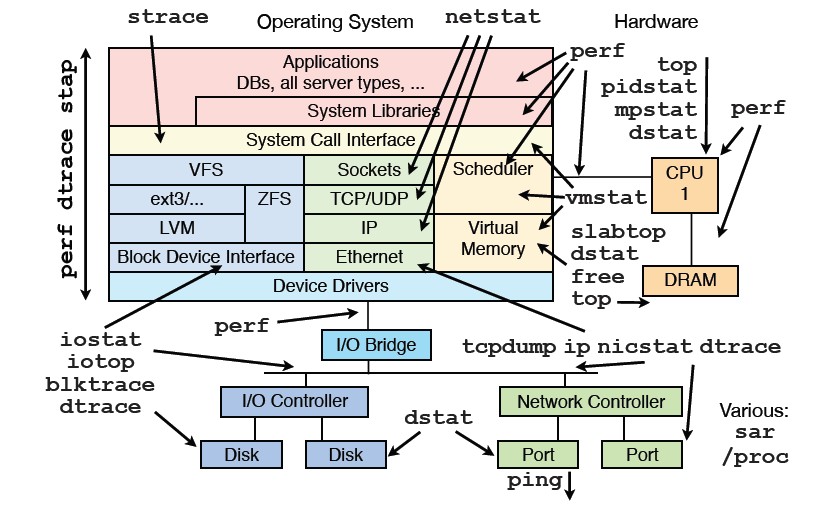
Linux常用性能调优工具索引
这篇盘点了Linux性能调优的“武器库”,源自Brendan Gregg经典的性能分析图谱。作者并未止步于理论图表,而是结合自身多年的运维与优化实践,将图中提到的数十款核心工具与自己的实战笔记一一关联。 从监控网络流量的nicstat,到剖析内核函数的perf与systemtap,再到排查I/O瓶颈的iotop和blktrace,文章为每一个工具都提供了可直达的深度解读链接。它更像一个精心整理的工具箱导览,涵盖了从宏观系统监控(如top、vmstat、dstat)到微观进程追踪(如strace、pidstat)的完整工具链。 对于系统工程师和开发者而言,这份索引省去了逐一搜寻的功夫,提供了按需取用的便利入口。当你在面对CPU、内存、磁盘或网络的性能谜题时,可以从这里快速找到那个最称手的工具。
开源压缩算法Zopfli介绍
这篇讲的是谷歌近期推出的一款名为Zopfli的开源压缩算法。它本身是一款deflate格式的兼容性压缩器,灵感来源于WebP图像压缩中的无损压缩技术优化,因此能与广泛使用的zlib、gzip完全兼容,这意味着几乎所有浏览器和解压工具都能直接处理Zopfli生成的数据。 文章重点剖析了Zopfli的两个核心特点:一是压缩性能,其输出文件比gzip 9压缩的结果小约3.7%到8.3%;二是压缩速度,比gzip 9慢了81倍。这是一个典型的用时间换空间的权衡。 作者指出,这种“高压缩率、解压完全兼容”的特性,使其特别适合Web服务器的数据存储与分发。虽然单个文件压缩率的提升看似不大,但在海量数据的场景下(如大型网站、CDN),由此带来的带宽与存储成本节约将非常可观。文章末尾还附上了简要的命令行用法,方便读者快速上手测试。
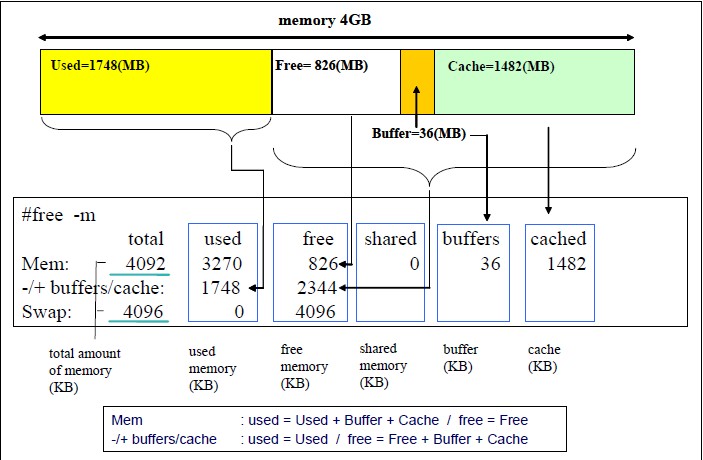
Linux Used内存到底哪里去了?
这篇讲的是Linux运维中一个经典困惑:用`free`命令看到内存已用7-8G,但`ps aux`统计的进程RSS总和却不到30M,多出的内存到底去哪了? 作者从同事的实际问题出发,逐步拆解。先解释`free`输出的含义,指出buffer/cache虽被计入used但可回收;然后通过工具如nmon、top分析,发现进程RSS确实占了大头,但还有剩余。进一步揭示内核开销:slab缓存用于对象池,通过`slabinfo`计算消耗了约900MB;页表管理物理页面,从`/proc/meminfo`读取占了58MB;加上struct page等固定消耗。通过编写脚本累加进程RSS、页表和slab,结果与`free`的used基本吻合,但略多171MB,原因是RSS计算中共享库被重复计算。 文章最后澄清了内存计算的迷糊账,教会读者如何用`slabinfo`、`/proc/meminfo`等工具自查,理解Linux内存管理的底层细节。对于遇到类似问题的开发者,这是一次清晰的排查示范。
dropwatch 网络协议栈丢包检查利器
这篇讲的是,当Linux服务器出现网络超时,用tcpdump或wireshark抓包能看到丢包,但往往很难定位到内核协议栈深处的具体丢包位置。作者介绍了一个专门解决此痛点的利器:dropwatch。 dropwatch的核心能力是精准定位数据包在Linux网络协议栈中“被丢弃”的内核函数位置。文章演示了在RHEL系系统上,通过简单的yum安装后,以交互模式启动`dropwatch -l kas`,就能实时看到诸如`netlink_unicast`、`unix_stream_recvmsg`等函数的丢包计数,并直接对应到内核源码,大大缩小了排查范围。 它的原理巧妙地利用了内核的kprobe机制。工具会监控内核中关键的`kfree_skb`函数调用(该函数在协议栈多个层次被用于释放数据包)。当监控到此函数被调用时,即视为一次丢包,dropwatch会记录并通知用户空间显示发生丢包的内核函数符号信息。文章还指出,要让dropwatch工作,内核需要打特定的补丁以区分“正常释放”和“丢包释放”,并通过Netlink将信息传递给用户空间。对于运维和网络开发人员来说,这是一个深入内核腹地、直击丢包根源的高效诊断工具。
深度剖析告诉你irqbalance有用吗?
这篇深度技术剖析探讨了irqbalance这个中断平衡守护进程的实际价值。文章从“是否有必要开启它”这一实际运维问题切入,通过解读源码揭示了irqbalance的工作机制:它每10秒循环收集/proc/interrupts的中断分布数据,并根据设备类型(如网卡、存储设备)与CPU拓扑结构,动态计算并调整中断的CPU亲缘性。 作者指出,在特定高性能场景下(如应用已绑定CPU核),irqbalance的自动调整可能并非最优甚至不必要,因此需要理解其原理来做出正确取舍。文章深入解析了irqbalance如何利用SMP Affinity接口、区分中断类型在Package、Cache或Core级别进行平衡,将原本黑盒的守护进程逻辑清晰展现出来。对于需要精细调优系统中断分布的工程师而言,这些底层细节是做出判断的关键依据。
低成本和高性能MySQL云数据的架构探索
这篇讲的是阿里核心系统数据库团队如何从零打造一个名为UMP的MySQL云服务平台,来同时解决大规模MySQL集群面临的成本与性能难题。 背景是淘宝这样的企业有数千台MySQL服务器,直接扩展成本高昂。他们的UMP系统目标很明确:让开发者能方便地申请和使用资源,而由平台透明地处理主从热备、读写分离、分库分表等复杂运维工作。核心方案是在一台物理机上运行多个MySQL实例以降低成本,并实现资源的弹性隔离与分配。 他们最初的方案基于MySQL-Proxy,但很快发现了它的多线程模型缺陷、功能扩展困难以及社区不活跃等问题。于是,团队果断选择用Erlang语言重写了整个Proxy层。Erlang轻量级的“绿进程”和OTP框架,为他们提供了高并发、高容错且易于热部署的编程模型,完美契合了云服务的需求。 最终的UMP系统架构包含Controller、Proxy、Agent等多个角色,通过RabbitMQ和ZooKeeper协同工作,构成了一个完整的、可伸缩的云数据库服务。文中还透露,这个系统已经在天猫聚石塔等平台落地,为电商业务提供着安全可靠的数据云服务。

BufferedIO和DirectIO混用导致的脏页回写问题
这篇文章源于一次线上问题排查:曲山同学遇到系统性能抖动,最终发现罪魁祸首是 BufferedIO 与 DirectIO 的混用引发的脏页回写风暴。文章详细拆解了问题机制——当文件同时存在两种 I/O 访问路径时,操作系统对脏页的回写策略可能被扰乱,导致大量不必要的刷盘操作与延迟毛刺。作者不仅定位了内核页缓存与 IO 调度层的交互细节,还给出了具体的规避方案:比如统一 I/O 模型、调整文件系统挂载参数,或对关键路径做隔离。对于需要高性能存储或处理海量数据的应用开发者来说,这个案例清晰地展示了底层 IO 选择可能带来的隐性坑点,以及如何通过系统性的分析来规避类似风险。
ulimit -t 引起的kill血案
这篇讲的是一个由系统资源限制 `ulimit -t` 引发的生产事故。作者从一次线上服务进程被莫名“kill”的异常现象出发,逐步抽丝剥茧。他们发现,罪魁祸首是在启动脚本中被悄悄设置的 `ulimit -t`(限制进程的CPU时间)。一旦进程累积的CPU时间超过该阈值,系统就会毫不留情地将其终止。 文章详细复盘了整个排查过程:如何从监控指标中的“被信号终止”线索,追溯到用户进程的资源限制配置,最终定位到这个看似无害却容易被忽略的参数。关键在于,许多开发者并不清楚 `-t` 的具体语义,且它在多数现代发行版中默认值极高,一旦被显式设置一个较小的值(比如300秒),对于计算密集型任务就可能成为致命陷阱。 作者的结论很明确:在容器化和云原生环境中,CPU资源应通过 cgroup 或 Kubernetes 的资源配额来精细管理,而不是依赖这种传统的、作用域模糊的 shell 级限制。这篇文章提醒我们,在优化服务时,那些隐藏在启动脚本深处的 legacy 配置,可能正埋着下一次“血案”的种子。
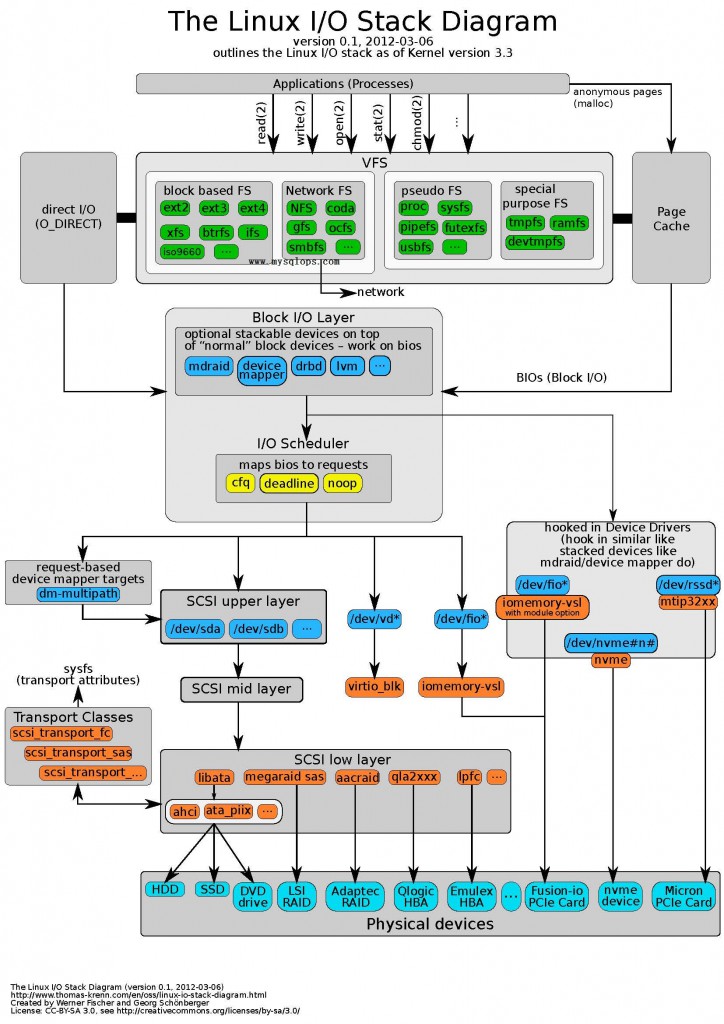
Linux IO协议栈框图
这篇分享的核心是一张珍贵的Linux内核IO协议栈全景图。作者从同事的PPT中偶然发现了这张框图,其源头来自Thomas Krenn的一份技术文档。这张图之所以值得特意贴出,是因为它清晰地勾勒出了从用户空间的应用程序发起读写请求,到数据最终落盘或返回的完整路径。 你可以直观地看到请求是如何穿越VFS层、具体的文件系统、Page Cache、通用块层,最终到达设备驱动和物理磁盘的。图中对同步IO与异步IO、缓冲IO与直接IO等不同路径做了区分,将内核中原本分散且复杂的处理流程串联成了一幅连贯的“地图”。对于想深入理解系统性能瓶颈或调试IO问题的工程师来说,这种结构化的呈现比阅读分散的源码或文档效率高得多,能快速建立起整体认知框架。 这张图的原始PDF链接在文中提供,方便读者获取更高清的版本。它适合作为手边常备的参考资料,无论是梳理知识体系还是排查具体问题,都能提供清晰的导航。