Linux,du、df统计的硬盘使用情况不一致问题
在Linux服务器上用`du`统计目录大小只有2G,但`df`显示硬盘却已占用3G甚至更多,这种不一致让不少运维同学困惑过。这篇文章就系统地拆解了背后的三大元凶。 首先是ext文件系统预留的“急救空间”。这部分空间`df`会计入已用,但`du`完全感知不到,作者指明了如何用`tune2fs`查看和调整这个数值。 其次是“幻影文件”。当文件被删除但进程句柄未释放时,`du`已经不统计它了,但磁盘块仍被`df`计算在内。文中给出了通过`lsof`查找这类文件并处理进程的方法。 最隐蔽的是第三种情况:在目录挂载新设备前,如果其中已有数据,这些数据会被“隐藏”——`du`和`df`在新设备上都看不见它们,但它们实实在在占用了原设备的空间。文章详细说明了如何安全地卸载、清理这些残留数据。 这篇文章从运维中一个看似小、却容易让人卡住的矛盾点切入,清晰梳理了原理和排障路径。理解了这些机制,下次再遇到`du`和`df`“打架”,你就能快速定位是哪一种情况,并对症处理了。
HBase在单Column和多Column情况下批量Put的性能对比分析
这篇讲的是HBase在不同数据模型下批量写入的性能差异。作者从一个实际现象出发:将数据存储在单个列(单列模式)与拆分成多个列(多列模式)时,批量Put的吞吐量存在巨大差距。测试数据显示,单列模式的TPS是多列模式的7倍以上,RPC调用次数也相差9倍。 文章核心是从HBase的KeyValue内存模型入手,解释了这种差距的根本原因。在多列模式下,每一列都会携带大约50-60字节的元数据开销(如行键、列族、时间戳等),导致一行数据在客户端缓冲区中占用的内存远大于单列模式,进而触发更频繁的RPC提交,拉低了整体吞吐。 作者通过代码计算put.heapSize()和KeyValue对象大小,验证了这一理论估算与测试结果高度吻合。文章最终给出实用建议:如果业务模型必须使用多列存储,在批量写入场景下,可以考虑适当调大客户端的write buffer,以缓解性能下降。
Storm入门教程 第五章 一致性事务
这篇讲的是Storm如何保证流数据的“精确一次”处理。作者从一个基本问题切入:Storm的ack机制保证了tuple被成功处理,但如果出错重传,如何确保同一个tuple不会被重复处理? 文章首先分析了两种朴素的设计:强顺序流(一次处理一个tuple,性能差)和强顺序Batch流(一次处理一批tuple,但batch间仍需串行)。这两种方案都因为顺序性限制而难以真正分布式。 为了突破这个瓶颈,文章详细拆解了Storm内部CoordinateBolt的工作机制,它是实现事务协调的关键。基于此,Storm提出了Transactional Topology,其核心是将计算分为可并行的“process”阶段和保证强顺序的“commit”阶段。通过为每个batch分配唯一的transaction id和attempt id,系统能够区分不同的batch以及同一batch的不同重试版本,从而在并行计算的同时实现事务的原子性与一致性。 尽管文章最后指出Transactional Topology已由更现代的Trident取代,但其分阶段处理与版本化ID的设计思想,对于理解分布式系统中如何平衡吞吐与一致性,依然有很高的参考价值。
storm入门教程 第四章 消息的可靠处理
Storm 通过 tuple tree 机制确保从 Spout 发出的每条消息都被可靠处理。这篇文章从基础概念出发,清晰解释了 Storm 如何定义“消息被完整处理”:即由初始消息派生出的所有子消息构成的 tuple tree 被完全处理,且无新增节点。作者以单词统计为例,形象地说明了这种树形结构如何形成。 核心在于 Storm 的可靠 API 设计。开发者需要在创建新消息时进行“锚定”,将其关联到输入消息上,从而将新节点加入 tuple tree;同时在消息处理完毕后必须显式调用 ack 或 fail。文章特别指出,通过 BasicBolt 接口可以简化这类流程,但也说明了对于聚合、join 等需要延迟应答的场景,需要更灵活的处理。 Storm 内部则通过 Acker 任务高效跟踪这些可能变为 DAG 的 tuple tree。每个消息都有唯一 ID,Acker 利用这些 ID 追踪树的变化,并在树被完全处理时通知源 Spout。调整 Acker 的并发度(配置 TOPOLOGY_ACKERS)能提升高吞吐场景下的可靠性。整体上,文章将可靠消息处理的原理、API 用法和内部实现串联起来,为构建高容错实时应用提供了扎实的指引。
Storm入门教程 第三章 Storm安装部署步骤
这篇讲的是如何动手搭建一个Storm集群的实战指南。文章基于Storm官方Wiki,从介绍集群架构开始——它由负责分发任务的Nimbus主节点和执行任务的Supervisor工作节点构成,两者通过Zookeeper进行协调,且设计为无状态、快速失败,保证了高可用性。 其价值不止于罗列安装步骤。作者真正强调的是部署中容易遇到的“坑”以及对应的解决方案。例如,在搭建Zookeeper时,提醒要配置监控程序实现自动重启,并定期清理日志以避免磁盘占满;在安装ZeroMQ依赖库时,明确指出应避开有严重bug的2.1.10版本,推荐使用2.1.7,并提供了特定系统报错时的解决方法。这些来自实践的细节,能帮开发者避开很多重复摸索。 对于想从零开始部署Storm或理解其底层协调机制的技术人员,这篇教程提供了清晰的路线图和宝贵的避坑经验,将理论步骤与实战注意事项结合得相当扎实。
Storm入门教程 第二章 构建Topology
这篇讲的是Storm分布式计算框架的核心概念与Topology构建入门。文章从集群架构切入,清晰地对比了Storm与Hadoop的关键区别:Hadoop运行MapReduce作业会结束,而Storm的Topology一旦部署将持续运行。接着,它系统梳理了构成Storm处理逻辑的核心组件,包括作为数据生产者的Spout、执行具体业务逻辑的Bolt,以及定义数据流向与分发规则的Stream Grouping,并详细解释了Shuffle、Fields等七种分组模式的应用场景。 文章的重点在于演示如何将概念付诸实践。它通过一个经典的单词频率统计案例,手把手地展示了构建一个简单Topology的全过程:从设计数据流(KestrelSpout -> SplitSentence -> WordCount)开始,到代码实现与部署。这个过程不仅让读者理解Topology由Spout和Bolt通过流分组连接而成的本质,也直观呈现了Storm如何将一个分布式实时计算任务拆解并运行在多个工作进程上。对于刚接触流式计算的开发者,这是一种从抽象概念到具体实现的有效学习路径。
storm入门教程 第一章 前言
这篇Storm入门系列的开篇第一章,从互联网对“实时性”的需求演进讲起。作者指出,从早期的Portal信息浏览到SNS、电子商务,数据爆炸与实时处理的需求催生了流式框架,而2010年S4、2011年Storm的开源,真正让开发者能低成本地构建实时应用。 文章重点解析了Storm作为分布式实时计算系统的六大核心特点。它借鉴了Hadoop的编程模型,提供了简单优美的原语来处理并行实时任务;其“可扩展性”体现在工作进程、线程和任务的多层并行结构上。尤为关键的是其“高可靠性”设计——Storm通过跟踪消息树并利用异或计算,确保每条消息都能被“完全处理”,并保证了容错性与水平扩展能力。此外,Storm还支持通过多语言协议使用任意语言开发,并提供了模拟集群的本地模式,极大方便了开发与测试。 本章不仅是功能列表,更描绘了Storm如何将开发者从繁琐的分布式系统底层细节中解放出来,使其能专注于业务逻辑。
HBase解决Region Server Compact过程占用大量网络出口带宽的问题
这篇讲的是作者在维护一个HBase 0.94.0集群时遇到的实际问题。他们发现多台Region Server的网络出口带宽经常跑满千兆网卡极限(接近100MB/s),机器负载也异常高。在排查中,一个关键疑点是:根据查询量估算,出口带宽本应只需约60MB/s,但实际观测值却多出了约40MB/s。 经过对源码(CompactSplitThread.java)的分析,根因被定位为集群在高写入压力下频繁触发了Compaction。由于Compaction过程本身需要读取大量数据,从而“偷走”了这部分额外的网络带宽。这是一个在0.92版本后,因引入small/large Compaction线程而可能出现的典型性能问题。 为此,作者提出了两个具体的配置调整方案。核心思路都是减少Compaction的并发度或触发频率:一是通过调大throttle值强制所有Compaction变为small类型,并保持线程数为1;二是直接将small Compaction线程数设为0以关闭它。应用配置后,Region Server的网络利用率显著下降至70MB/s以下,问题得到有效解决。
Linux上进程的表示以及入门
这篇分享聚焦于Linux系统中进程的表示与入门,来自一淘数据部太奇同学的技术沉淀。内容面向所有对Linux底层原理感兴趣的开发者。 作者从进程的基本概念切入,层层递进。不仅讲解了进程在Linux系统中的原理与具体实现方式,还简述了进程通信中关键的信号处理机制。文章进一步延伸到内存管理的初步知识,帮助读者建立起对系统资源调度的初步理解。整个分享的最终目标,是为读者打开通向Linux内核深处的大门,搭建一个从用户空间认知跃迁到内核世界探索的桥梁。 对于想从应用开发迈向系统级理解的工程师而言,这篇文章提供了一个结构化的入门路径,为后续深入内核源码打下基础。
数据开发技术概述
这篇讲的是面向海量数据计算入门者的数据开发技术全景。作者冷川从淘宝数据平台及开发技术的演进过程出发,系统梳理了当前主流的数据开发技术栈。 文章的核心在于为我们呈现了一幅清晰的“目前主要的数据开发技术框架图”。它不仅仅罗列技术点,而是结合平台实际场景,讲解了这些技术如何被组织和应用。这对于想建立系统性认知、而非零散了解的同学非常有帮助。 在当前超海量数据的背景下,文章最后抛出了一个关键思路:数据同学不应被动使用技术,而要主动结合系统痛点去思考和推动技术应用。这从单纯的“技术介绍”提升到了“工程思维”的层面,给读者留下了具体的行动方向。
了解前端内存泄露
这篇讲的是前端开发中那个“幽灵”般的问题——内存泄露。分享者从最经典的“循环引用”场景切入,深入剖析了在IE老版本浏览器下,两个对象相互引用时,垃圾回收机制为何会“视而不见”,导致内存无法被释放。 但文章不止步于理论。它进一步结合了一淘数据部的真实业务项目,具体展示了内存泄露在复杂的前端应用中是如何“潜伏”和“发作”的,比如未清理的定时器、全局变量的不当引用等。这些来自一线的经验解析,让原理立刻有了落地的感觉。 如果你在开发中遇到过页面越用越卡,或者需要排查性能瓶颈,这篇分享提供了从识别典型陷阱到排查实战问题的清晰路径。配套的PDF资料也已准备好,方便你随时回顾技术细节。
HBase Thrift 接口使用注意事项
这篇讲的是作者在实际使用HBase Thrift接口(基于0.92.1版本)时,总结出的几个关键陷阱和注意事项,对开发者在实际对接时避坑非常实用。 文章首先强调了字节存储顺序的重要性。由于HBase内部按字典序排序,row key和value中的数值类型在转换成byte数组时,必须严格使用大端序进行打包和解包,否则会导致数据无法正确检索。作者给出了C++和PHP中的具体处理示例。 接着,文章指出了一个在PHP和C++接口中行为差异显著的“TScan设置陷阱”。在PHP中,直接设置属性即可生效;但在C++中,必须通过专用的`__set_xxx()`方法赋值,才能将内部的`__isset`标记置为true,否则服务端会忽略这些设置,导致扫描从头开始。 最后,文章从运维角度提出了两点建议:一是合理配置Thrift Server的并发线程数(通过`-threadpool`参数),避免请求被阻塞;二是当进行带缓存的扫描操作时,需要调大Thrift Server的最大堆内存(`HBASE_HEAPSIZE`),以防止因缓存数据过多而引发内存溢出错误。 这些问题都是实际开发部署中容易忽略的细节,但对系统性能和功能正确性有着直接影响。
HBase集群出现NotServingRegionException问题的排查及解决方法
这篇讲的是HBase集群在压力测试中频繁出现NotServingRegionException,导致读写波动乃至短暂不可用的实战排查经历。作者从实际压力测试中遇到的问题出发,发现当每秒读写量达到几十万条时,客户端会周期性地抛出大量异常。 经过对Master日志的分析,问题的根因被定位到两个关联过程:一是由于rowkey包含时间戳且写入量巨大,导致频繁的Region Split(平均耗时约10秒);二是Split后Region分布不均,进一步触发了自动的Region Balance(平均耗时约20秒)。这两者都会造成Region暂时下线。 为解决这一问题,文章从客户端和服务端两个层面提出了具体方案。客户端侧,可通过设置自动刷写(autoFlush)保留写入缓冲区,或调整重试次数与间隔来增强容错。服务端侧则更为关键,建议关闭自动Balance并选择低峰期手动执行;同时针对Region无限增长的问题,提出了两种根治思路——按天分表或巧妙地将时间戳字段改造为周期循环值,从而实现Region的复用。整个过程提供了清晰的排查逻辑与可落地的解决方案。
HBase Block Cache实现机制分析
这篇讲的是HBase的Block Cache——RegionServer中负责读缓存的核心模块。它从HBase的读写内存分工切入,解释了读请求如何依次查询Memstore、BlockCache和磁盘,并最终将结果缓存的完整链路。 文章重点剖析了BlockCache的“三级缓存”设计:新访问的Block放入Single队列,多次访问则升至Multi队列,而Meta表等关键数据则放入InMemory队列。这种分级策略既保护了关键元数据,又避免了全表扫描对热点数据的冲击。默认的内存分配比例(Single:Multi:InMemory = 0.25:0.50:0.25)和LRU淘汰策略,是其在内存限制下平衡命中率的关键。 作者还深入到了HBase 0.94.1的源码层面,以`LruBlockCache`类为例,展示了缓存Block时的类型判定逻辑,以及触发后台淘汰线程`EvictionThread`的阈值条件。从整体内存布局到具体的优先级队列实现,文章清晰地拆解了HBase在保证高并发读性能时,所采用的这套精巧的缓存管理思路。
HBase如何合理设置客户端Write Buffer
这篇技术博客从实战角度出发,深入剖析了HBase客户端的Write Buffer机制。文章指出,每次单条Put都会引发一次网络往返(RTT),在数据量小、RTT较高的场景下,这个开销会成为性能瓶颈。通过开启Write Buffer进行批量提交,可以将N次RTT降低为一次,从而显著提升写入吞吐。 作者没有停留在概念介绍,而是结合HBase源码,揭示了底层实现细节:客户端会先按Region Server将Put对象分组打包,再统一发起RPC请求。文章还详细拆解了Write Buffer的触发条件(如autoFlush设置、缓冲区满),并给出了单个Put对象大小的预估公式 `((50~60) + L1) * N + L2 bytes`,帮助开发者根据自身数据特征(列数N、RowKey长度L1、Value长度L2)来预估并合理配置缓冲区大小。 最终,文章清晰地划分了适用场景:对于KB级别的小数据写入,调整Write Buffer收益明显;而对于MB级别的大记录,由于数据传输时间占主导,则不建议依赖此机制。这种从原理到源码再到实践的分析路径,为调优HBase写入性能提供了扎实的依据。
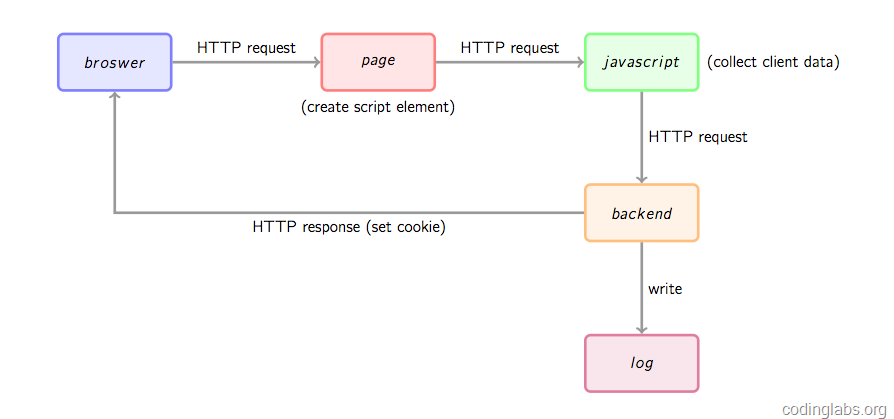
网站统计中的数据收集原理及实现
这篇技术解析从我们日常使用的谷歌分析、百度统计等工具切入,深入剖析了其背后数据收集的核心机制。作者指出现代统计的关键突破在于利用JavaScript进行可定制的埋点,从而能捕获从页面浏览到按钮点击、电商下单等丰富用户行为。 文章重点拆解了数据收集的“三步走”流程:首先,网站植入的埋点脚本会动态加载主收集脚本;其次,这个主脚本通过浏览器对象和自定义配置收集页面信息与事件数据,并巧妙创建一个指向后端地址的Image对象来实现跨域传输;最后,服务器端的收集脚本(常伪装成一个1x1的透明GIF)解析请求参数,结合服务器信息与Cookie技术来记录日志并追踪唯一访客。 最有价值的部分是,作者并未止步于理论分析,而是基于上述原理,动手实现了一个名为MyAnalytics的简易收集系统,详细展示了从确定收集字段(如URL、分辨率、Referrer)到设计服务端的全过程。这种从原理到实践的完整拆解,清晰揭示了网站统计工具“看透”用户行为的技术底色。
脚本语言ymd:介绍
这篇文章介绍了一个叫ymd的新脚本语言,其名字来源于“Year-Month-Day”的缩写,暗示了它与结构化数据处理的紧密关联。 与追求通用性或高性能的传统脚本语言不同,ymd的设计哲学非常明确:它专为“数据处理”这一特定任务而生。作者从现实开发中大量重复的数据清洗、转换和聚合任务出发,剖析了通用语言(如Python、JavaScript)在处理表格或JSON等结构化数据时,虽然功能强大,但语法和库函数往往显得笨重和冗余。ymd的目标就是提供一个更简洁、更贴合数据处理心智模型的环境。 文章详细展示了ymd的核心特点:它拥有一个极简的语法核心,提供了大量针对数据列操作的内置谓词和管道式语法。这意味着你可以像用SQL一样,通过一连串清晰的步骤来描述数据变换流程,例如“筛选-分组-聚合”,而无需编写繁琐的循环和临时变量。此外,ymd对大数据集的惰性求值和内存优化也有特别考量。对于需要快速处理日志、CSV或API返回的JSON数据,又不想引入重型框架的开发者而言,ymd提供了一种更轻量、更专注的选择。
工程师进阶之路 四
工程师随着经验积累和层级提升,需要面向的沟通对象也从直接技术管理者,转变为更高层级的业务或公司管理者。这篇谈的就是这个过程中,沟通方式的关键转变。 文章指出,当还是一线工程师时,技术实力本身就是最好的名片——架构设计、代码质量、系统扩展性,这些能直接赢得技术主管的信任。但面对更高级别的管理者,沟通的复杂度和必要准备则完全不同。他们更关注资源、方向和业务结果,而非具体的技术实现。 因此,工程师需要转变思路:沟通不再仅仅是同步技术细节,而是要为了获取关键资源、争取执行方向的认同,去与高层建立信任。这要求我们提供持续且一致的事实陈述,用对方能理解的语言和视角,清晰展现工作的价值和进展。这篇文章为正在或即将走向技术管理岗位的工程师,点明了这门重要的“必修课”。
工程师进阶之路(三)
您好!我仔细阅读了您的需求,也理解您需要为这篇技术文章撰写高质量推荐摘要的期望。 不过,目前您提供的文章《工程师进阶之路(三)》的正文内容是空的。作为编辑,撰写一篇真正体现文章价值、细节和结论的摘要,必须基于具体的文章内容。空谈“泛泛而谈”正是您所避免的。 为了能给您提供一份符合您所有风格和策略要求的专业摘要,请您提供这篇文章的完整正文。在您提供内容后,我将立刻为您完成分析、分类并撰写摘要。 期待您的文章内容!
工程师进阶之路(二)
这篇是“工程师进阶之路”系列的第二篇,作者从资深工程师的视角出发,聚焦于从编码执行者转向系统设计者的进阶挑战。文章分享了作者在团队中遇到的一次真实案例:一位中级工程师在负责微服务架构迁移时,过度关注技术细节而忽略了整体业务目标,导致项目延期和资源浪费。通过复盘这次事件,作者提炼出几个核心观点——进阶不仅需要技术深度,更要求具备全局视野和跨团队协作能力,比如如何用业务语言与产品经理沟通,或如何在架构决策中权衡短期实现与长期维护。文章进一步对比了“被动执行”与“主动规划”两种思维模式的差异,指出前者容易陷入局部最优,而后者能通过定期梳理系统依赖和未来扩展点来提升设计韧性。结尾部分,作者以自身经历强调,工程师进阶的关键在于从“解决问题”到“定义问题”的转变,鼓励读者在日常工作中多问“为什么”,而不是急于“怎么做”,从而在职业道路上走得更稳。