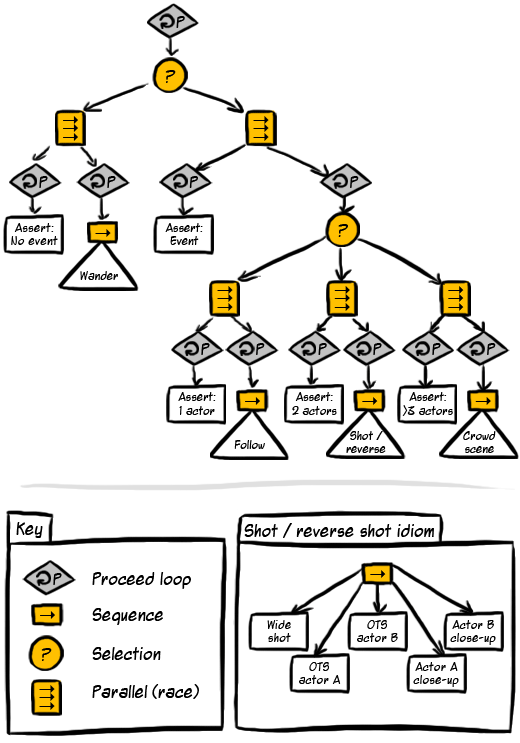
行为树及其实现
这篇讲的是作者如何将游戏AI中的行为树概念落地为一段具体的C代码实现。文章从游戏开发中传统状态机的扩展性难题切入,引出了行为树作为解决方案的背景。 作者梳理了行为树的核心结构:由负责逻辑判断的中间节点(如顺序、优先级)和执行动作的叶子节点构成,并通过“黑板”机制在节点间共享数据。重点在于其实现部分——作者对比了800行的C++实现,认为其封装偏深,因此用约400行C代码,以组合而非继承的方式完成了一个更轻量的版本,并解释了核心API如创建节点、分支与执行tick的设计。 文章还透露了行为树在工业实践中往往依赖可视化编辑器生成JSON描述,为后续扩展埋下了引子。整体而言,这是一次从理论到轻量级代码的实践记录。
kmemcache源码浅析
这篇讲的是memcache的Linux内核移植版kmemcache的源码实现。作者深入分析了这个不走寻常路的高性能缓存项目,重点剖析了它如何摒弃了常见的epoll通知机制,转而利用网络数据包 skb 的回调函数,实现了更细粒度的 packet 级调度。 文章的核心在于揭示kmemcache独特的网络模型设计:一个dispatcher(调度器)与多个worker(工作线程)协同工作。其中dispatcher专门负责处理TCP和Unix域套接字,并将新建的连接分配给特定的worker;而所有的UDP请求也由这些worker直接处理。 在实现细节上,文章拆解了用户态守护进程umemcached与内核模块kmemcache.ko之间,如何通过Netlink机制完成启动参数传递等关键交互。作者结合具体的代码结构(如cn_entry、cn_queue),清晰地展示了“请求-应答”的同步通信流程,以及其中涉及的序列号管理和回调处理等巧妙设计。 整体来看,这是一篇扎实的内核级源码剖析,它不仅解释了kmemcache“做了什么”,更细致地拆解了它是“怎么做到的”,对于想理解Linux内核网络子系统优化或高性能缓存实现的读者来说,提供了非常具体的参考。
fatcache源码浅析
这篇讲的是Twitter开源的缓存服务fatcache,可以把它理解为一个“SSD版的Memcached”。作者从其源码出发,剖析了它如何用有限的内存索引,去管理大容量的SSD存储。 文章详细解读了fatcache的核心设计。它使用通用的队列(generic queue)来管理资源池,底层则采用了经典的slab allocator内存模型。作者拆解了slabclass、slab和item等关键结构,并说明了fatcache如何在内存中用哈希表快速索引key,而实际的value数据则可能存储在内存或磁盘的slab里。 最精巧的部分在于其读写与淘汰机制。为了适配SSD,fatcache设计了一套基于FIFO的淘汰策略。在写入时,它能将内存中的slab成片地交换到磁盘,巧妙地将随机写转化为顺序写,提升了IO效率。对于删除操作,它只在索引层面标记删除,而不立即修改SSD数据,等待后续自然淘汰,这种设计充分避免了不必要的随机写入。 整个设计体现了对硬件特性的深刻理解,用相对简单的队列和slab管理,在缓存层实现了高效的数据存取。
libevent源码浅析: http库
这篇讲的是开发者常常忽略的 libevent 库内置的 http 模块。作者从如何用最少的代码搭建一个 http 服务器这个实用问题出发,带我们深入其源码。 文章的核心是揭示这个 http 库如何巧妙地建立在 libevent 本身的事件驱动架构之上。分析从初始化一个事件监听器开始,追踪了一个新连接到来后,如何被接管并封装为一个内部事件对象。重点剖析了请求解析、响应生成,以及最关键的——如何将处理逻辑注册为事件回调,从而无缝融入整个事件循环。其中,对连接生命周期和状态机(如等待请求头、等待请求体等)的管理,展示了实现高效、非阻塞网络服务的典型思路。 通过拆解这些实现细节,文章不仅说明了如何使用,更清晰地展现了“事件驱动”与“http 协议处理”相结合的具体编码实践,对理解这类网络库的设计模式很有启发。
libevent源码浅析: 定时器和信号
这篇讲的是libevent事件库中定时器与信号处理机制的实现细节。作者在先前讨论了基本I/O事件处理之后,将视线转向了另外两种核心事件类型。 文章聚焦于libevent如何高效地管理定时任务和信号响应。对于定时器部分,重点剖析了其内部的时间堆数据结构与管理策略,解释了如何通过最小堆来快速定位最近到期的事件,以及事件重复与移除的具体实现逻辑。对于信号处理,则深入探讨了libevent如何利用管道或信号垫片机制,将异步信号转化为可由事件循环统一处理的读事件,从而优雅地解决了信号处理与多线程、多事件循环的兼容性问题。 通过对这些源码层面实现思路的梳理,文章揭示了libevent在设计上追求统一事件源和高效调度的核心思想。其巧妙之处在于,将看似异质的I/O、定时、信号事件抽象为一致的事件模型,并嵌入到同一个高性能的事件循环中,为上层应用提供了简洁而强大的编程接口。这对于理解高性能网络库的设计模式很有参考价值。
我的大学
这篇讲的不是技术干货,而是一段极度个人化的大学生活自述。作者以近乎“man show”的坦率笔触,回顾了大学期间那些不加修饰的真实片段——可能是迷茫的选择、笨拙的尝试,或是意料之外的成长轨迹。 它毫不掩饰地自称“毫无营养”,这意味着你不会从中找到明确的技能提升路径或解决方案。但这恰恰是它的特点:剥离了功利性的技术叙事,直面那些构成技术人底色的、混乱而鲜活的青春记忆。文章更像一面镜子,照出的或许是你我共有的、在成为“工程师”之前那段充满试错与可能性的混沌时期。 如果你期待一篇结构清晰的教程,这确实不是你要找的。但如果你想在技术文章之外,窥见一位同行者走过的非标准路径,感受那些未被代码定义的时光,那么这篇毫无矫饰的坦白,或许能带来一点共鸣或会心一笑。
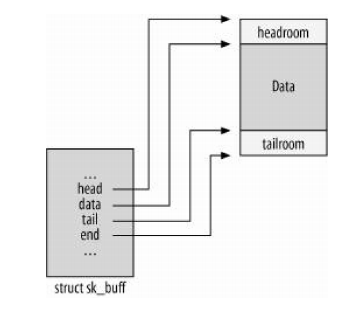
初探Linux网络协议栈
这篇讲的是Linux网络协议栈的核心脉络。作者从数据包的旅程出发,清晰梳理了从网卡接收到应用层处理,再到发送出去的完整路径。文章特别聚焦于内核中几个关键的数据结构,比如 `sk_buff` 如何串联起整个数据包生命周期,以及协议栈各层(如IP、TCP)如何协作处理数据。 它不仅解释了协议栈“是什么”,更深入探讨了“为什么这样设计”。例如,在讨论TCP层时,文章点出了拥塞控制与流控机制如何在内核中被具体实现,并对比了不同拥塞算法(如Reno和Cubic)在处理网络抖动时的策略差异。这种从设计哲学到代码实现的剖析,让抽象的网络概念变得具体可感。 读完后,你不仅能对Linux处理网络数据的流程有宏观认知,更能理解那些高性能服务器调优参数背后的原理——为什么调整某个内核参数会显著影响并发连接数。对于想从“会用”Linux网络迈向“理解”其内核实现的开发者而言,这篇提供了扎实的切入点。
vim入门,进阶与折腾
这篇讲的是作者基于长期使用vim的亲身体验,对这款“编辑器之神”从入门到深入应用的经验梳理。文章直面vim那令人头疼的陡峭学习曲线,但并非泛泛而谈,而是将过程拆解为“入门”、“进阶”与“折腾”三个具体阶段。作者从实际的文本编辑场景出发,分享了如何在初期建立正确的心智模型、熟悉核心操作,进阶到通过配置与脚本提升效率,并最终大胆尝试插件开发或功能定制等“折腾”过程的心得与教训。 其中,文章没有回避学习过程中的挫折感,而是将之转化为可复用的备忘与路径指引。它尤其适合那些已经听闻vim强大却迟迟不敢上手,或是刚入门便因复杂操作而望而却步的开发者。通过作者总结的经验,读者能更清晰地看到学习重点,知道哪些“坑”可以避免,从而更平滑地度过最痛苦的初期阶段,逐步解锁vim真正的生产力潜能。
