Puppet 的类参数传递
这篇讲的是如何通过为类添加参数来提升 Puppet 配置的灵活性。作者从使用 ENC(外部节点分类器)管理 Puppet 的实践出发,发现仅传递一个全局的 role 参数在面对频繁修改的配置时,操作起来并不方便。 因此,他考虑引入类参数。文章通过修改前后的代码对比,清晰地展示了这一转变:将原本硬编码在 `nginx::loadbalancer` 子类中的 `iplist` 变量,提升为父类 `nginx` 的一个参数,并逐层传递下去。这样在 ENC 中,就可以直接为 `nginx` 类指定 `iplist` 的值,实现了配置的灵活注入。 文章还总结了三个关键要点: ENC 传递的参数值需要从父类层层传递到真正使用的子类;在 ENC 中为类传参时,类声明必须采用哈希形式;而接受参数的类在调用时,则必须使用资源声明式的语法,而不能再使用 `include`。这个方法巧妙地利用了 Puppet 的类继承和参数特性,在保持 ENC 输出结构相对简洁的同时,显著提高了配置管理的灵活性。
为比特币绘制 MACD、BOLL、KDJ 指标图
这篇讲的是,作者如何用 Python 从零开始,为比特币行情绘制一套像股票软件那样的技术分析指标图。 核心要解决的问题是数据源的“坑”:比特币中国的 API 返回的最高价、最低价和成交量,是基于过去24小时统计的,但比特币市场根本没有休市概念。作者的设计思路是,参照股市习惯,采用4小时为一个周期进行数据处理和绘图。 文章详细分享了从获取数据、存储到计算指标的全流程。作者先编写程序,将实时交易数据和计算出的4小时周期K线(OHLC)数据存入MySQL数据库。随后,重点展示了 MACD 指标的计算算法:如何通过收盘价序列依次计算出12日和26日指数移动平均线(EMA),得到差离值 DIF,再计算 DIF 的9日EMA作为信号线 DEA,最终求出 MACD 柱状图。整个实现过程逻辑清晰,代码完整。 作者将这套自己的实现与后来 btc123 平台上线的官方指标图作了对比,并大方地将源码分享在博客,为同样在学习 Python 或量化交易的朋友提供了一个不错的实践参考。
用 LEK 组合处理 Nginx 访问日志
这篇讲的是作者在使用 Logstash 处理 Tengine/Nginx 通过 syslog 发送的访问日志时,遇到的几个实际性能瓶颈及优化方案。文章首先指出,在高压力下 Logstash 的 Grok 插件容易成为瓶颈,因此作者建议在日志格式可控时,优先考虑用分隔符格式配合 Ruby 脚本或自定义 LogFormat 来替代 Grok 解析。 然而真正的坑在后面:运行后发现日志接收带宽异常低,排查发现是 Logstash 的 syslog input 插件采用了单线程 UDP 监听,导致接收队列(Recv-Q)持续堆积。作者对比了 Fluentd 的异步实现,并考虑到 Logstash 基于 JRuby 的扩展复杂性,最终选择了一个更直接的方案:用 Perl 的高性能 AnyEvent 库重写了一个专门的异步日志收集脚本。这个脚本同样将日志输出为 Elasticsearch 兼容格式,使得原有的 Kibana 仪表盘无需任何改动。最终效果立竿见影,日志接收带宽从瓶颈时的 60 MBps 恢复到了正常的 300 MBps。
在 Perl6 脚本中并发执行 ssh 命令
这篇讲的是作者在 Perl6 中并发执行 SSH 命令时的一次实战尝试。由于找不到合适的现有模块,且底层 C 库不兼容其 Kerberos 认证环境,作者决定绕开高层并发 API(如 Promise/Supply),直接使用更底层的 Thread 和 Channel 来实现。 文章围绕一个简洁的 OpenSSH 类展开,展示了如何通过多方法实现单个主机与多主机的命令执行。作者特别指出,虽然 Perl6 宣传了高级并发模型,但 API 迭代较快,有时选择更稳定的底层原语反而更可靠。 代码示例串联了不少 Perl6 语法点:类的属性定义、字符串连接符 `~`、用于捕获错误的 `try`/`CATCH`、执行系统命令的 `qqx{}`,以及 `>>` 操作符在数组上的线程化 finish 操作。作者也坦诚,示例代码较为简陋,例如依赖密钥登录且未使用线程池调度。 整体来看,这是一份结合了具体需求、实现思路与语法讲解的笔记,既分享了在 Perl6 中集成系统命令与并发控制的方法,也客观分析了语言特性在实际场景下的应用考量。
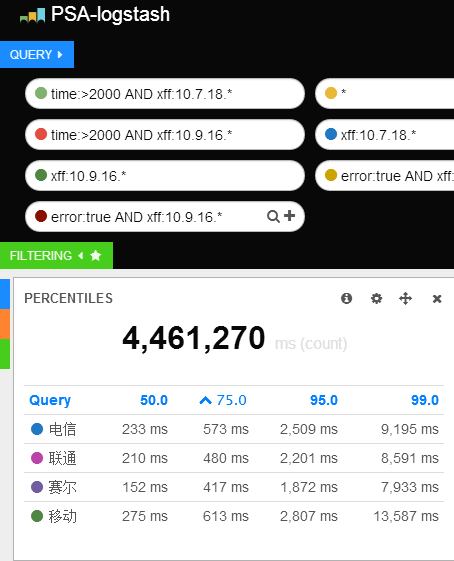
给 Kibana 实现百分比统计图表
这篇讲的是作者如何在一个下班前的冲动下,给 Kibana 3.1 手动添加 percentile 图表类型,以支持 Elasticsearch 的百分比统计功能,结果却挖出了一连串坑。 作者的初衷很直接:利用 Elasticsearch 1.1 新增的 percentile aggregation 来做更细致的日志区间分布分析,并认为这能作为学习 AngularJS 的练手项目。但实际动手后发现,计划中的“简单更新 JS 库”完全行不通。最大的坑在于 Kibana 3.1 内置的 elasticjs 库版本号标注混乱(写着 v1.1.1 实则是旧版),而新版的 elasticsearch.js 代码结构又彻底重构,不再适配 Kibana 使用的 requirejs 模块化方案。 在探索了替换整个库的复杂路径后,作者找到了一个更直接的解决方案:既然 Elasticsearch 是 RESTful 接口,那就绕过这些客户端库,直接用 AngularJS 的 $http 服务手动构建请求。不过,这个过程也撞上了 Elasticsearch 本身的限制——aggregation_name 字段不支持中文字符,迫使作者需要调整 Kibana 原有的别名生成逻辑。 最终,作者用这个看似“不太优雅”但确实有效的方法实现了功能。文章记录的这些具体踩坑细节,比如库版本号陷阱、模块加载冲突以及数据字段命名限制,对同样想在 Kibana 上做定制开发的人来说,都是很实际的参考。
【翻译】用 elasticsearch 和 elasticsearch 为数十亿次客户搜索提供服务
这篇讲的是邮件服务商 Mailgun 如何为数百万客户提供对每月数十亿封邮件事件的实时搜索与分析。面对原有日志 API 的功能短板,他们构建了基于 Elasticsearch 和 Logstash 的新后端。 核心方案是将所有邮件事件(如发送、拒绝、打开等)通过 Logstash 从 Redis 接入,存入 Elasticsearch 集群,从而提供灵活的字段过滤与全文搜索。文章详细分享了几个关键实践:为满足不同账户的数据保留需求,他们设计了灵活的索引轮转策略;为了处理复杂的事件数据结构,他们定义了详细的自定义 mapping,并巧妙运用了 not_analyzed 属性和多字段类型来优化查询与聚合统计。 此外,文章还介绍了如何通过一个名为 Vulcan 的双层代理来解决 Elasticsearch 原生缺乏的认证问题,以及如何利用 Graphite 和自研的 Vör 工具监控集群状态。整个方案最终让 Mailgun 控制面板拥有了强大的实时日志分析能力。
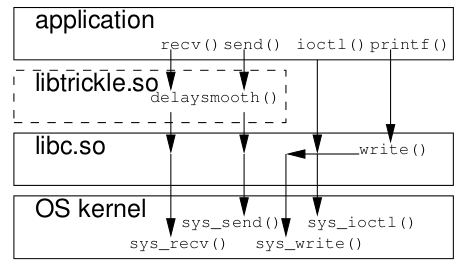
限制单个进程的带宽
这篇文章讲的是如何在Linux系统中限制单个进程的网络带宽,而非传统的端口或全局限速。作者从系统管理员常见的需求出发,对比了几种方案的可行性。 传统的iptables配合owner模块的方法,在现代支持SMP的内核中已因匹配项被移除而基本失效。文章接着推荐了一个名为trickle的工具,它通过ELF preloader机制替换socket库函数来实现限速,用法简单。但作者也明确指出其局限:对静态编译或suid权限的程序无效。 为了解决更复杂的场景——例如对已运行进程动态调整带宽——文章最终引入了cgroup的net_cls控制器。它通过给数据包打标记,再交由tc流量控制工具处理,实现了类似iptables但更灵活、更现代的管理方式。这篇文章为不同环境下的进程带宽限制需求,提供了从传统工具到内核级方案的清晰对比和选型思路。