Spark性能优化——和shuffle搏斗
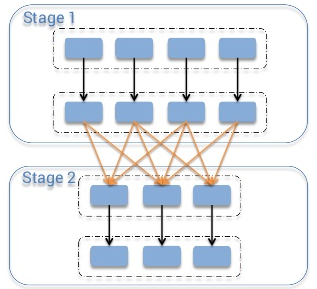
这篇讲的是Spark性能调优中一个最头疼的问题——shuffle。作者把shuffle比作必须击败的“大boss”,因为它会触发大量网络传输和序列化,让原本在内存中飞快的计算慢下来。 文章没有堆砌理论,而是直接切入实战技巧。比如,作者用一个从3小时缩短到20分钟的例子,说明“先各自去重,再合并”为何能大幅减少shuffle数据量;还对比了`mapValues`与`map`、`reduceByKey`与`groupByKey`,点明哪些操作会偷偷引发shuffle,而哪些能保持本地高效计算。 针对常见的大小表join,文章给出了一个巧妙思路:把小表广播出去,用`broadcast`加`filter`直接替代耗时的`join`操作,能完全避免shuffle。对于数据倾斜导致单节点过载的问题,作者也指出了改进key设计的解决方向。 整篇文章就像一位有经验的工程师在分享如何“避坑”,从原理到代码示例都很具体,最后还提醒了关于`collect`、避免RDD嵌套操作等容易忽略的细节。对于用Spark处理大数据的人来说,这些围绕shuffle的优化思路相当实用。