科技爱好者周刊(第 400 期):rsync 的争论
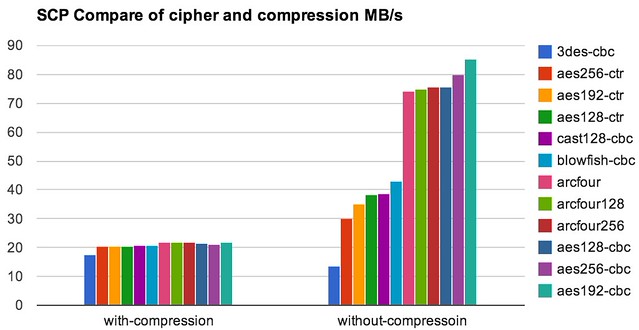
科技爱好者周刊第400期围绕rsync工具最新版本3.4.3由AI模型Claude生成引发的争议展开。社区成员强烈质疑AI生成代码可能引入安全漏洞,威胁基础命令的可靠性。维护者Andrew Tridgell解释,因AI驱动的安全攻击日益复杂,他引入AI以增强rsync防御能力,自身转向编写测试用例确保代码质量,这体现了“AI写代码 + 人类测试”的新兴开发模式,尤其适用于资源有限的开源项目。文章还提及Meta AI客服漏洞案例,显示自动化系统可被提示词攻击修改用户邮箱,突显安全风险。此外,讨论延伸至AI对工作效率的影响,如减少工时可能带来福利提升,以及Siri唤醒事件中苹果通过频率删除避免误唤醒的技术细节。整体聚焦AI在开发中的应用趋势,强调测试与监控的重要性,但周刊性质导致部分话题如避蚊胺实验略分散焦点。