您现在的位置:首页
--> 系统架构
把网络游戏服务器分拆成多个进程,分开部署。这种设计的好处是模块自然分离,可以单独设计。分担负荷,可以提高整个系统的承载能力。缺点在于,网络环境并不那么可靠。跨进程通讯有一定的不可预知性。服务器间通讯往往难以架设调试环境,并很容易把事情搅成一团糨糊。而且正确高效的管理多连接,对程序员来说也是一项挑战。前些年,我也曾写过好几篇与之相关的设计。这几天在思考一个问题:如果我们要做一个底层通用模块,让后续开...
1、文件存贮的问题对于一些支持文件上传的2.0的站点,在庆幸硬盘容量越来越大的时候我们更多的应该考虑的是文件应该如何被存储并且被有效的索引。常见的方案是对文件按照日期和类型进行存贮。但是当文件量是海量的数据的情况下,如果一块硬盘存贮了500个G的琐碎文件,那么维护的时候和使用的时候磁盘的Io就是一个巨大的问题,哪怕你的带宽足够,但是你的磁盘也未必响应过来。如果这个时候还涉及上传,磁盘很容易就over了。 2、海...



数据库的可用性和扩展性一直是数据库厂商和用户最关注的问题。过去我们采用高端的设备,比如使用小型机和大型存储来保证数据库的可用 性。而扩展性主要采用向上扩展(Scale up)的方式,通过增加CPU,内存,磁盘等方式提高处理能力。这种集中式数据库的架构,使得数据库成为了整个系统的瓶颈,已经越来越不适应海量数据对计 算能力的巨大需求。近些年来,分布式系统成为了一种趋势,我们...
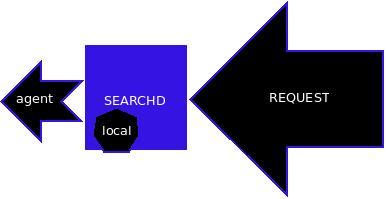
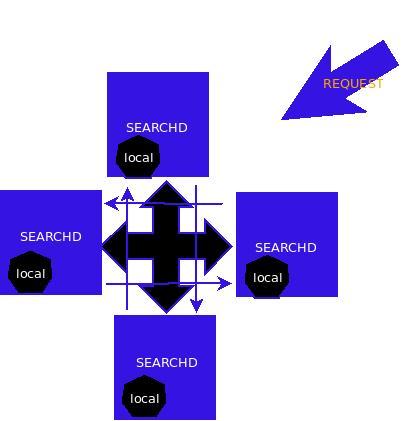
来自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级),实测千万级数据在0.0X秒和0.00X秒占大多数。 Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,实测30W线上复杂的blog数据需要5分钟,创建1000万条记录的索引可以在50分钟内完成,实测时间比这个更长得多,而只包含最新10万条记录的增量索引,重建一次只需几十秒,实测十万条在一分钟不到的时间。 Sphinx 是一个基于 GPL 2 协议颁发的免费开源的全文搜索引擎.它是专门为更好的整合脚本语言和SQL数据库而设计的.当前内置的数据源支持直接从连接到的 MySQL 或 PostgreSQL 获取数据, 或者你可以使用 XML 通道结构(XML pipe mechanism , 一种基于 Sphinx 可识别的特殊xml格式的索引通道) 。
Twitter的调整对于MySQL业界来说或许是一大利好,MySQL虽然受近期Oracle收购阴影的影响,但是对于目前大多数拥有海量数据访问的网站依然是他们第一选择。MySQL简单,可靠,安全,配套工具完善,运维成熟。业界碰到的大部分可扩展性方面的问题在MySQL中其实都有清晰明确的解决方法。虽然重复sharding的问题很烦,增删机器相关的运维工作也很繁琐,但是这些工作量还是在可以接受的范围内。
tmdb 是一个类似于 dbm/gdbm/ndbm/sdbm 的小hash数据库,用来存储一些简单,最好是只读的Key-Value数据,本文讲解了tmdb的基本原理和和实现。
C 语言,从 1970 年代设计并实现之初,它就注定了带有强烈工程师文化的语言,而缺乏一些学术气息。它的许多细节设计,都带有强烈的实用化痕迹。C 语言因 UNIX 操作系统而生,是 UNIX 系统的母语。这导致在这个广泛应用的操作系统上开发,必须通过 C 语言的形式和系统进行交互。这不仅影响了 UNIX 一个平台上的软件,既而也影响了后来世界上最大的桌面系统 Windows ,以及越来越多的嵌入式平台。
• 淘宝图片存储架构
今天中午花一小时看了下章文嵩博士写的<淘宝海量图片存储与CDN系统>,没有做过大容量的存储系统,也没有做过分布式的应用,只是从学习的角度去思考下未来可能学习的方向和一些点.对比公司的图片服务,其实在技术实现上都有共性:1:imageserver:(1)缓存和图片处理具体使用apache和nginx都无所谓,imageserver的负载在于图片的转换,以及部分中间缓存的读取.GraphicsMagick可以未来尝试使用,另外为提高imageserver的命中率通过lvs...

NoSQL其实并不是什么妖魔鬼怪,相反的,NoSQL的真谛其实应该是Not Only SQL,其产生是在数据量和访问量的增大下,人为地去添加机器、切分数据到不同的机器,变得越来越困难,人力成本越来越高,于是便开始有了这样的项目,本意是提高数据存储的自动化程度,减少人为干预的时间,让负载更加均匀。在国际上,真正的代表之作有来自Google的 BigTable 和Amazon 的Dynamo,他们分别使用了不同的基本原理。
Author:NinGoo posted on NinGoo.net 对于传统的关系数据库Oracle/MySQL等,NoSQL一个相当大的不足是文档资料的缺失。相对而言,Cassandra还能找到不少资料,这个ppt是我根据网上一些资料,结合这几天浏览...
对于互动类产品,性能是最重要的,最近半年也一直致力于优化.说到优化,不能为了优化而优化.需要找到最影响性能的点.对于大型网站,对于server端的优化是有限的(相对来说),因为这涉及到底层架构改造,从时间和效果来看,并不能立竿见影.服务器端的优化更倾向于伸缩性和可扩展性,那么最利于优化,最见效果的优化属于前端的优化. 对于博客这样的内容提供网站,提供了外部组件的嵌入,提供了各种各样的布码.简单的来说,就是页面元素过多...

出自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
Sphinx 0.9.9及以前的版本,原生不支持实时索引,一般的做法是通过主索引+增量索引的方式来实现“准实时”索引,最新的1.10.1(trunk中,尚未发布)终于支持real-time index,查看SVN中文档,我们很容易利用Sphinx搭建一个按需索引(on demand index)的全文检索系统。 参考文章:http://filiptepper.com/2010/05/27/real-time-indexing-and-searching-with-sphinx-1-10-1-dev.html 首先,从sphinxsearch的SVN下载最新的代码,编译安...
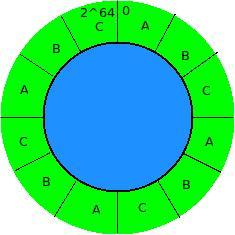
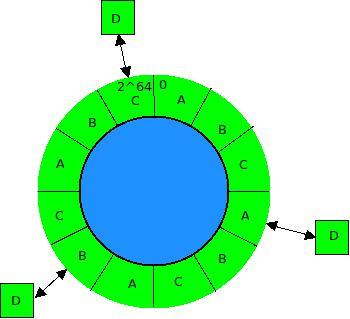
将Cassandra用于实际的生成环境,一个必须要考虑的关键问题是Token的选择。Token决定了每个节点存储的数据的分布范围,每个节点保存的数据的key在(前一个节点Token,本节点Token]的半开半闭区间内,所有的节点形成一个首尾相接的环,所以第一个节点保存的是大于最大Token小于等于最小Token之间的数据。
今天是在公司的四周年,未来一段工作重心也将有所变化,从以前的开发逐渐要转变,希望能够适应,也能看淡,总之要更加专业化.最近半年的工作经历比较有典型意义,成长不少.也做了很多事情,从技术层面上来说,主要有五点.(1)静态化,静态化的目的主要是减低解析,元素离页面更近.(2)接口Cache化,接口合并:目的建立对外部服务的优化,减少客户端的渲染.(3)服务一致化:简单的说不管采用哪种技术(不管有没有缺点),那你所有的应用就往这上面靠...
在面试过程中,我时常会问一道简单的题目:请找出如下程序不妥之处:void s_c(const char *s, const char *p){ while (*s) { *p = *s; }}首先,这道简单的题目考察的是找错能力,比如结束符和const的应用。其次,考察的是接口设计能力,这也是重点。没有返回值,因此对于一些异常现象不好对外表现,const是否应用正确,函数名使用是否见其名知其意,函数参数是否见其名知其意,有没有对接口的简述,指针,引用,就量传...


Xapian API是相当复杂的,而且在索引和搜索时,QueryParser,Term,document values 经常困惑着人们.要特别指出的是,Xapian本身并无一个”field”的概念,field这东西是flax的组件做的更高层次的抽象和封装.Xapian只是有Document ,包含一个整数标识ID,document包含:
Terms (通常是词或短语,可以带位置信息,带位置信息的叫POST),
VAlue (通常是一个简短的字符串,也可能是包含的二进制数据),以及
data (可以是任何数据,但往往是一些适合显示的文本)。
今天和同事在群里讨论“QQ上传大文件/QQ群发送大文件时,可以在极短的时间内完成”是如何做到的。有时候我们通过QQ上传一个几百M的文件,竟然只用了几秒钟,从带宽上限制可以得出,实际上传文件是不可能的。实现的思路肯定是根据文件内容生成一个“唯一的标识符”,根据这个标识符去判断服务器上是否已经存在这个文件,如果存在,则不需要再...
近3天十大热文
-
 [14] 浏览器的工作原理:新式网络浏览器幕后揭秘
[14] 浏览器的工作原理:新式网络浏览器幕后揭秘 -
[14] 界面设计速成
-
[13] iOS下自己动手造无限循环图片轮播
-
[13] Spark性能优化——和shuffle搏斗
-
[13] Android设计中的.9.png
-
[13] iOS可视化编程 Tips 之“无需代码设置
-
[12] 最萌域名.cat背后的故事:加泰与西班牙政府
-
[12] 我的git笔记
-
[12] Go Reflect 性能
-
[11] 内网穿透神器frp
赞助商广告
