您现在的位置:首页
--> 系统架构





排序中我们需要解决的是什么样的问题?怎么样把用户想要的,好的商品排到前面;怎样调节不同卖家的流量;给质量好,但价格不便宜的商品更多的流量,来引导市场更加规范。需要解决的问题很复杂,但是排序结果好坏难以评判。




一淘第一版的产品搜,有一个关键模块叫PS Server,它的位置就是今天AGG的位置。它有一个AGG今天没有的职能,就是访问产品搜自己的Forest,负责翻译产品搜的类目属性信息。为什么是自己的Forest?因为一淘产品库为了快速迭代,从淘宝SPU库中脱离出来,类目用的是淘宝的后台类目,但SPU的pid/vid是完全独立的一套数据,这么做有利有弊,因此欠下的债我们早晚也要还的。
在数据的世界里,我们看到了很多很牛,很强大也很有趣的案例。但是,数据就像一个王座一样,像征着一种权力和征服,但登上去的路途一样令人胆颤。




Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。其架构如图 1所示,Impala主要由Impalad, State Store和CLI组成。



YARN是Hadoop新版中的资源控制框架。本文旨在深入剖析ResourceManager的调度器,探讨三种调度器的设计侧重,最后给出一些配置建议和参数解释。
本文分析基于CDH4.2.1。调度器这个部分目前还在快速变化之中。例如,CPU资源分配等特性在不就的将来就会加入。








今天才认识到原来JPEG文件有两种保存方式他们分别是Baseline JPEG(标准型)和Progressive JPEG(渐进式)。两种格式有相同尺寸以及图像数据,他们的扩展名也是相同的,唯一的区别是二者显示的方式不同。




对于淘宝网这样的大型电子商务网站,对于图片服务的要求特别的高。而且对于卖家来说,图片远胜于文字描述,因此卖家也格外看重图片的显示质量、访问速度等问题。根据淘宝网的流量分析,整个淘宝网流量中,图片的访问流量会占到90%以上,而主站的网页则占到不到10%。同时大量的图片需要根据不同的应用位置,生成不同大小规格的缩略图。考虑到多种不同的应用场景以及改版的可能性,一张原图有可能需要生成20多个不同尺寸规格的缩略图。
我们都知道加锁是有开销的,不仅仅是互斥导致的等待开销,还有加锁过程都是有系统调用到内核态的,这个过程开销也很大,有一种互斥锁叫Futex锁(Fast User Mutex),Linux从2.5.7版本开始支持Futex,快速的用户层面的互斥锁,Fetux锁有更好的性能,是用户态和内核态混合使用的同步机制,如果没有锁竞争的时候,在用户态就可以判断返回,不需要系统调用,当然任何锁都是有开销的,能不用尽量不用,使用双Buffer,释放链表,引用计数,都可以在一定程度上替代锁的使用。



随着公司业务的飞速发展,集群规模的逐步扩大,各计算系统,存储系统,应用系统也随着业务的发展,一个接一个的被创造了出来。但集群规模扩大以后,却带来很多问题,如自动化部署,集群整体利用率偏低等问题也逐步的暴露出来。所以,迫切的需求一套集群资源调度系统来解决这些问题。各大互联网公司也相继搞出了一些系统,如omega(google),yarn(apache社区,hadooop下面的一个分支,开源),mesos(twitter,开源),torca(腾讯soso), Corona(Facebook)。




到13年6月为止,已经负责API接近两年了,这两年中发现现有的API存在的问题越来越多,但很多API一旦发布后就不再能修改了,即时升级和维护是必须的。一旦API发生变化,就可能对相关的调用者带来巨大的代价,用户需要排查所有调用的代码,需要调整所有与之相关的部分,这些工作对他们来说都是额外的。如果辛辛苦苦完成这些以后,还发现了相关的bug,那对用户的打击就更大。如果API经常发生变化,用户就会失去对提供方失去信心,从而也会影响目前的业务。
• 回调还是消息队列
socket 底层有一个 poll 的 api ,通过 epoll 或 kqueue 或 select 取得一系列的事件。用 lua 怎么封装它呢?一个比较直接的想法是注入一个 callback function ,对于每个事件回调一个 lua 函数。但这容易引起许多复杂的问题。因为回调函数很不可控,内部可能抛出异常,也可能引起函数重入,或是做了一些你不喜欢去做的事情。
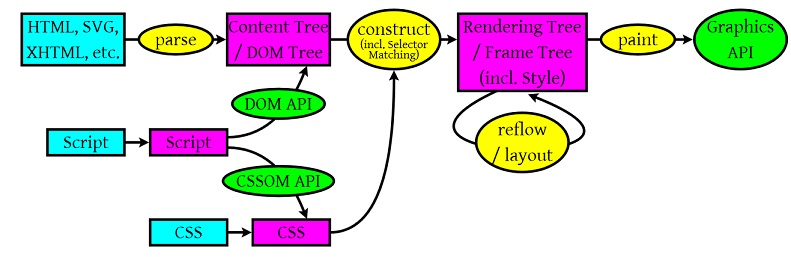
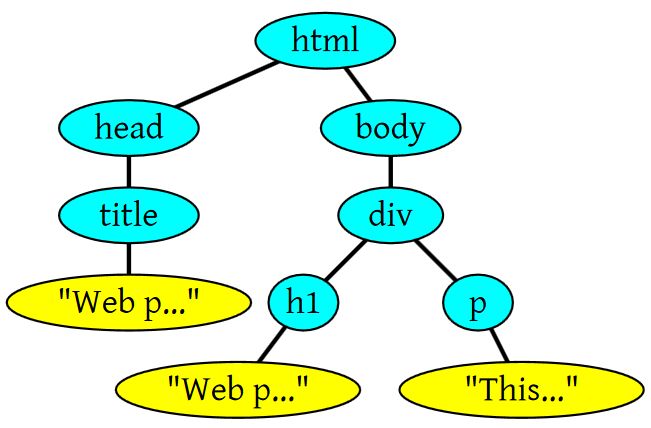
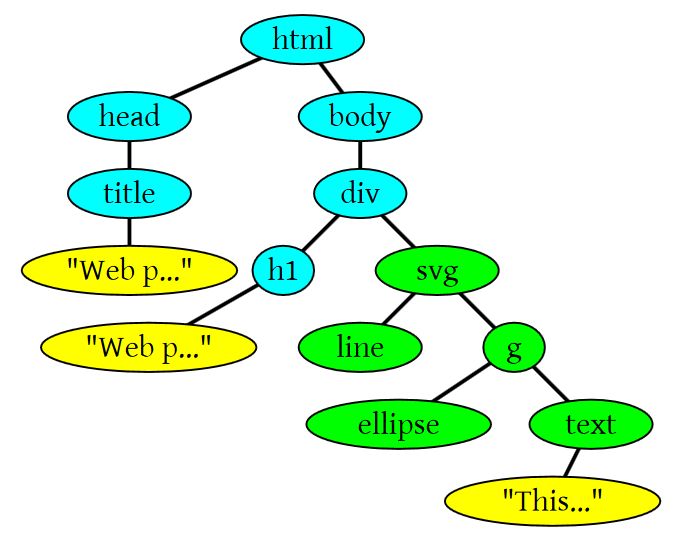
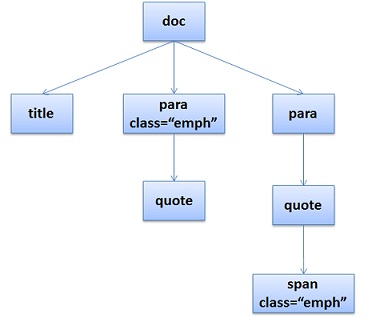
看到这个标题大家一定会想到这篇神文《How Browsers Work》,这篇文章把浏览器的很多细节讲得很细,而且也被翻译成了中文。为什么我还想写一篇呢?因为两个原因,
1)这篇文章太长了,阅读成本太大,不能一口气读完。
2)花了大力气读了这篇文章后可以了解很多,但似乎对工作没什么帮助。
所以,我准备写下这篇文章来解决上述两个问题。希望你能在上班途中,或是坐马桶时就能读完,并能从中学会一些能用在工作上的东西。

• 页缓存概述
页缓存是Linux内核一种重要的磁盘高速缓存,它通过软件机制实现。但页缓存和硬件cache的原理基本相同,将容量大而低速设备中的部分数据存放到容量小而快速的设备中,这样速度快的设备将作为低速设备的缓存,当访问低速设备中的数据时,可以直接从缓存中获取数据而不需再访问低速设备,从而节省了整体的访问时间。
通过一番辛苦,tps终于从120升到了810,并且tps曲线平衡(几乎时条直线),cpu资源的利用率也很平衡80%的us和20%的sys。要提高tps,首先要保证单个请求响应时间不能过长。响应时间过大,tps较难提升。更少的上下文切换和更少的系统内核调用,更少的IO操作可以换得更大的tps。通过strace可以统计出调用了哪些系统内核调用,帮助你优化应用。减少上下文切换最有效的办法就是减少进程数量。
更小的静态资源(js、css、png、gif),意味着更少的网络传送时间。构建的时候,可以把这些静态资源进行压缩优化(不像gzip/deflate压缩),使之更小化。有很多相应的开源工具帮助你完成这项工作。
总结
1.UglifyJS压缩比YUI Compressor更小,比Google Closure Compiler更安全。不想冒险,还是应该选择UglifyJS。若想最小化,可以选择Google Closure Compiler
2.YUI Compressor压缩css文件。但CSSTidy也很不错
3.optipng -o3 *.png |advpng -z -4 *.png |advdef -z -4 *.png 将最大化压缩优化png图片
4.网页尽量使用png格式图片,并且压缩优化它,使之最优
近3天十大热文
-
 [115] Go Reflect 性能
[115] Go Reflect 性能 -
[20] [译]Google Chrome中的高性能网
-
[17] 在FreeNAS/BSD搭建基于Nginx+
-
[16] 关于Linux的文件系统cache
-
[14] Linux常用系统信息查看命令
-
[14] 最近总结的一些技巧(vim,python,s
-
[12] PHP加速器 eaccelerator 缓存
-
[11] 精于图片处理的10款jQuery插件
-
[11] 什么是DNS劫持和DNS污染?
-
[10] nginx.conf控制指定的代理ip和ip
赞助商广告
