您现在的位置:首页 --> 查看专题: Redis


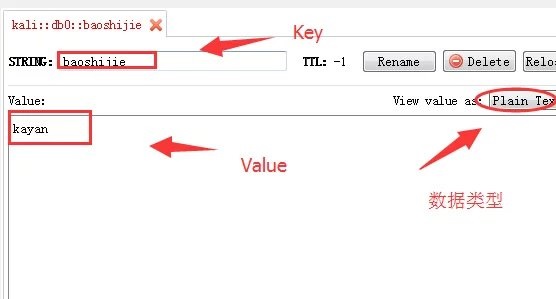


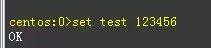
本文作者带大家了解什么是Redis,并且了解Redisc客户端redis-cli、Redis Desktop Manager、Redis的常用的Key操作命令、配置命令,讲解Redis未授权利用配合SSH免密码登录,并且解决利用Redis写公钥依然无法登录的情况以及相关的修复方案,欢迎讨论。
当执行redis的bgsave命令时,redis会fork一个进程把redis中的内存数据写入磁盘。这样的好处是,copy on write,有效的节省了内存占用。但是,bgsave时,如果有数据变更,一样需要申请内存。当申请内存时,如果发现内存不够,可能就会报上面的错误。
如果 MySQL 数据库比较大的话,我们很容易就能查出是哪些表占用的空间;不过如果 Redis 内存比较大的话,我们就不太容易查出是哪些(种)键占用的空间了。
有一些工具能够提供必要的帮助,比如 redis-rdb-tools 可以直接分析 RDB 文件来生成报告,可惜它不能百分百实现我的需求,而我也不想在它的基础上二次开发。实际上开发一个专用工具非常简单,利用 SCAN 和 DEBUG 等命令,没多少行代码就能实现。
最近接触了一下Redis数据,出于好奇看了下它的源码,觉得这是一个值得一读的开源项目。关于Redis的源码分析,已经有很多网友写了各种分析笔记,而且也有相关的书籍《Redis设计与实现》,因此我觉得完整的写一系列的博客就没有必要了,这里主要记录一些个人觉得有意思或者是值得了解的东西(之前面试也有问到一些问题,如果我早一点接触这些东西的话,可以回答的更好)。




Redis支持服务器端的数据操作:Redis相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached里,你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么Redis会是不错的选择。
Redis在分布式应用中占据着越来越重要的地位,短短的几万行代码,实现了一个高性能的数据存储服务。最近dump中心的cm8集群出现过几次redis超时的情况,但是查看redis机器的相关内存都没有发现内存不够,或者内存发生交换的情况,查看redis源码之后,发现在某些情况下redis会出现超时的状况,相关细节如下。。。。
redis 是 key-value 存储系统,其中 key 类型一般为字符串,而 value 类型则为 redis 对象(redis object)。redis 对象可以绑定各种类型的数据,譬如 string、list 和 set。


redis 支持 master-slave(主从)模式,redis server 可以设置为另一个 redis server 的主机(从机),从机定期从主机拿数据。特殊的,一个 从机同样可以设置为一个 redis server 的主机,这样一来 master-slave 的分布看起来就是一个有向无环图 DAG,如此形成 redis server 集群,无论是主机还是从机都是 redis server,都可以提供服务)。




在 redis 中有多个数据集,数据集采用的数据结构是哈希表,用以存储键值对。默认所有的客户端都是使用第一个数据集,如果客户端有需要可以使用 select 命令来选择不同的数据集。redis 在初始化服务器的时候就会初始化所有的数据集.。。。。。


redis 中 zset 是一个有序非线性的数据结构,它底层核心的数据结构是跳表. 跳表(skiplist)是一个特俗的链表,相比一般的链表,有更高的查找效率,其效率可比拟于二叉查找树。

MULTI,EXEC,DISCARD,WATCH 四个命令是 redis 事务的四个基础命令。其中:MULTI,告诉 redis 服务器开启一个事务。注意,只是开启,而不是执行;EXEC,告诉 redis 开始执行事务;DISCARD,告诉 redis 取消事务;WATCH,监视某一个键值对,它的作用是在事务执行之前如果监视的键值被修改,事务会被取消。在介绍 redis 事务之前,先来展开 redis 命令队列的内部实现。
intset 和 dict 都是 sadd 命令的底层数据结构,当添加的所有数据都是整数时,会使用前者;否则使用后者。特别的,当遇到添加数据为字符串,即不能表示为整数时,redis 会把数据结构转换为 dict,即把 intset 中的数据全部搬迁到 dict。
这里所说的数据结构是针对 redis 内部存储 key-value 的,其他诸如 redis 配置相关的数据结构,不在此篇讨论范围。
在 redis 中,允许用户设置最大使用内存大小 server.maxmemory,在内存限定的情况下是很有用的。譬如,在一台 8G 机子上部署了 4 个 redis 服务点,每一个服务点分配 1.5G 的内存大小,减少内存紧张的情况,由此获取更为稳健的服务。redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略。
一台Redis服务器在很短的时间里消耗了几十个G的内存,最终因为SWAP而宕机。因为这台服务器的社会背景比较复杂,所以一时无法判断犯罪嫌疑人到底是谁。 最开始的直觉是认为肯定有人保存了大体积的数据,于是问题就变成了找出哪些键占用的空间比较大,DBA同事用了redis-rdb-tools等工具来分析数据文件。可惜的是虽然找到了一些大体积的键,但最终都排除了嫌疑,问题似乎陷入了僵局。

开始程序运行的非常稳定,稳定到我想送所有说HGETALL是个坑的人一个字:呸!此时的我就像温水里的青蛙一样忘记了危险的存在,时间就这样一天一天的过去,突然有一天需求变了,我不得不把HASH数据的内容从十几个字段扩展到一百多个字段,同时使用了Pipelining一次性获取上百个HGETALL的结果。于是我掉坑里了:服务器宕机。
为什么会这样?Redis是单线程的!当它处理一个请求时其他的请求只能等着。通常请求都会很快处理完,但是当我们使用HGETALL的时候,必须遍历每个字段来获取数据,这期间消耗的CPU资源和字段数成正比,如果还用了Pipelining,无疑更是雪上加霜。
Redis 是一个非常快速和强大的 Key-Value 存储(持久化)系统, 相对于一般的 NoSQL 存储系统, 它最大的特点是支持丰富的数据结构. 特别是其 zset(sorted set)数据结构, 堪称表达能力最强的结构之一(其它强大的数据结构如 sorted hashmap), 可以直接地表达业务逻辑.
近3天十大热文
-
 [254] Go Reflect 性能
[254] Go Reflect 性能 -
[17] [译]Google Chrome中的高性能网
-
[15] 关于Linux的文件系统cache
-
[12] Linux常用系统信息查看命令
-
[12] PHP加速器 eaccelerator 缓存
-
[11] Mac下.apk的反编译
-
[10] PHP上传文件类型彻底判断方案及PHP+ng
-
[10] 最近总结的一些技巧(vim,python,s
-
[10] 在FreeNAS/BSD搭建基于Nginx+
-
[9] webapp网页调试工具Chrome Dev
赞助商广告
