用sphinx轻松搞定方便管理的多节点过亿级数据搜索
概述
来自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级),实测千万级数据在0.0X秒和0.00X秒占大多数。 Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,实测30W线上复杂的blog数据需要5分钟,创建1000万条记录的索引可以在50分钟内完成,实测时间比这个更长得多,而只包含最新10万条记录的增量索引,重建一次只需几十秒,实测十万条在一分钟不到的时间。 Sphinx 是一个基于 GPL 2 协议颁发的免费开源的全文搜索引擎.它是专门为更好的整合脚本语言和SQL数据库而设计的.当前内置的数据源支持直接从连接到的 MySQL 或 PostgreSQL 获取数据, 或者你可以使用 XML 通道结构(XML pipe mechanism , 一种基于 Sphinx 可识别的特殊xml格式的索引通道) 。
sphinx安装
配置多节点协同工作
第一点,原理
在sphinx.conf中可以配置index段落里的local和agent两个参数,local = blog_1表示使用本地索引名为blog_1的索引,agent = 10.1.1.1:3312:blog_2表示使用10.1.1.1这个机器的3312端口上服务的blog_2索引。这两个参数均可在此段落中重复出现。
利用这两个参数,可进行节点与节点间的配置。如图1所示,一个searchd服务在接到请求时两种使用索引的示意图。
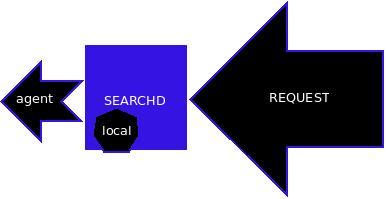
图1 一个searchd服务在接到请求时两种使用索引的示意图
第二点,架构
利用agent参数,可以灵活配置去代理取满足搜索条数的超时时间等等。
如图2,只需要将索引灵活分布,各自除了自己的local索引以外,全部连成相互的agent,使得别的节点也可以得到自己的索引搜索结果,以此得到分布式的处理结果。
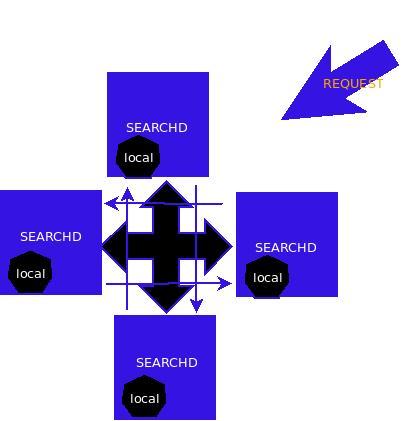
图2 一个简单的分布式搜索的例子
第三点,性能
分布索引的情况下,实测千万数据量,大致在500qps左右,没有做容灾的方案,如果想容灾,可以考虑将索引做成在某些节点上重复。总得来说,性能还算可以,更具体的架构方案,可能要和具体的业务来分布效果会更好。
建议继续学习:
- 怎样用好Google进行搜索 (阅读:15551)
- 淘宝搜索:定向抓取网页技术漫谈 (阅读:9201)
- 简析搜索引擎中网络爬虫的搜索策略 (阅读:7114)
- 几种常见的基于Lucene的开源搜索解决方案对比 (阅读:5823)
- 基于用户行为分析的搜索引擎自动性能评价 (阅读:5479)
- 用Sphinx快速搭建站内搜索功能 (阅读:5417)
- 百度搜索URL参数解析 (阅读:5422)
- 附近地点搜索初探 (阅读:5017)
- 互联网网站的反爬虫策略浅析 (阅读:4964)
- Xapian搜索体系结构 (阅读:5037)
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:54chen 来源: 五四陈科学院-坚信科学,分享技术
- 标签: Sphinx 搜索
- 发布时间:2010-07-14 09:53:06

-
 [781] WordPress插件开发 -- 在插件使用
[781] WordPress插件开发 -- 在插件使用 -
[60] Java将Object对象转换为String
-
[59] cookie窃取和session劫持
-
[58] 学习:一个并发的Cache
-
[57] 你必须了解的Session的本质
-
[54] 再谈“我是怎么招聘程序员的”
-
[51] Linux如何统计进程的CPU利用率
-
[50] 解读iPhone平台的一些优秀设计思路
-
[50] 最萌域名.cat背后的故事:加泰与西班牙政府
-
[49] 一句话crontab实现防ssh暴力破解
