思考mysql内核之初级系列9---innodb动态数组的实现
在上一篇,bingxi和alex聊了关于list的内容。在本篇里,bingxi和alex会聊到innodb的动态数组,也称为dyn。
对应的文件为:
D:\mysql-5.1.7-beta\storage\innobase\include\dyn0dyn.h
D:\mysql-5.1.7-beta\storage\innobase\include\dyn0dyn.ic
D:\mysql-5.1.7-beta\storage\innobase\dyn\dyn0dyn.c
1)常用结构体
Alex:“bingxi,我们前两篇聊了常用结构hash、list,这两个结构很常见。我们快要开始聊文件空间存储了,在那里面有一个常用结构,我们看一下fsp0fsp.c中函数,比如fsp_get_space_header函数,调用参数里面有mtr_t。
| 以下是代码片段: /************************************************************************** Gets a pointer to the space header and x-locks its page. */ UNIV_INLINE fsp_header_t* fsp_get_space_header( /*=================*/ /* out: pointer to the space header, page x-locked */ ulint id, /* in: space id */ mtr_t* mtr) /* in: mtr */ |
我们接着看一下mtr_struct的定义,在结构体的定义前一行,我们可以看到Mini-transaction,称为mini事务。用于锁信息、mtr日志信息。
| 以下是代码片段: /* Mini-transaction handle and buffer */ struct mtr_struct{ ulint state; /* MTR_ACTIVE, MTR_COMMITTING, MTR_COMMITTED */ dyn_array_t memo; /* memo stack for locks etc. */ dyn_array_t log; /* mini-transaction log */ ibool modifications; /* TRUE if the mtr made modifications to buffer pool pages */ ulint n_log_recs; /* count of how many page initial log records have been written to the mtr log */ ulint log_mode; /* specifies which operations should be logged; default value MTR_LOG_ALL */ dulint start_lsn;/* start lsn of the possible log entry for this mtr */ dulint end_lsn;/* end lsn of the possible log entry for this mtr */ ulint magic_n; }; |
我们将要开始fsp0fsp.c的内容,为了便于内容的独立,会将mtr的内容先剥离,在讲完存储之后,会继续讲B树,然后会到事务。
”
Bingxi:“alex,我赞同这一点。不过我认为还是把该结构体中的一个常用算法讲下,就是动态数组,mtr_t结构体中会有两个这样的结构成员:
| 以下是代码片段: dyn_array_t memo; /* memo stack for locks etc. */ dyn_array_t log; /* mini-transaction log */ |
所谓动态数组,就是一个动态的虚拟线性数组,数组的基本元素是byte,主要用于存放mtr的锁信息以及log。如果对于一个block数组不够存放时,需要增加新的block,每个block对应的存放数据字段的长度是固定的(默认值是512),但是不一定会用完。假设已经用了500个字节,这时候需要继续存放18个字节的内容,就会在该块中存放不了,会产生一个新的block用于存放。从而前一个block使用值为500。
我们先看了结构体的定义:
| 以下是代码片段: typedef struct dyn_block_struct dyn_block_t; typedef dyn_block_t dyn_array_t; …… /*#################################################################*/ /* NOTE! Do not use the fields of the struct directly: the definition appears here only for the compiler to know its size! */ struct dyn_block_struct{ mem_heap_t* heap; /* in the first block this is != NULL if dynamic allocation has been needed */ ulint used; /* number of data bytes used in this block */ byte data[DYN_ARRAY_DATA_SIZE]; /* storage for array elements */ UT_LIST_BASE_NODE_T(dyn_block_t) base; /* linear list of dyn blocks: this node is used only in the first block */ UT_LIST_NODE_T(dyn_block_t) list; /* linear list node: used in all blocks */ #ifdef UNIV_DEBUG ulint buf_end;/* only in the debug version: if dyn array is opened, this is the buffer end offset, else this is 0 */ ulint magic_n; #endif }; |
在这个结构体中,我们可以看到上一篇聊到的list结构,可以通过list查找prev、next。
Alex,这里面就带来了一些问题:1) dyn_array_t与dyn_block_t是同样的定义,而一个动态数组只有一个首结点,那么UT_LIST_BASE_NODE_T(dyn_block_t) base成员是不是每个结构体都是有效的,2)一开始分配的时候只分配了一个结构体,也就是512字节的大小,如果不够用,则扩展了一个,插入到链表里面,链表成员是1个还是2个?3)使用的时候,如何判断一个block已经使用满了,比如前面我们说到一个情况:500个字节剩下了12个不够18个时候,产生了一个新的block,假设这时候要使用其中的10个字节,两个block都是符合,用哪个?如果用后一个,怎么标识前一个是满的。”
Alex:“你的问题太多了,呵呵。我们先放下问题,看一下动态数组的初始化过程。这里面,我们还需要主意一点。虽然数据结构用的是同一个dyn_block_struct,但是我们称第一个节点为arr,表明这个是动态数据的头节点。其它的节点,我们称为block节点。
现在开始进行debug,在 mtr0mtr.ic文件中的mtr_start函数体内设置断点,这里也是动态数组创建的唯一入口,设置断点进行调试。
| 以下是代码片段: /******************************************************************* Starts a mini-transaction and creates a mini-transaction handle and a buffer in the memory buffer given by the caller. */ UNIV_INLINE mtr_t* mtr_start( /*======*/ /* out: mtr buffer which also acts as the mtr handle */ mtr_t* mtr) /* in: memory buffer for the mtr buffer */ { //会创建两个动态数组,在两个创建的任一个设置断点 dyn_array_create(&(mtr->memo)); dyn_array_create(&(mtr->log)); mtr->log_mode = MTR_LOG_ALL; mtr->modifications = FALSE; mtr->n_log_recs = 0; #ifdef UNIV_DEBUG mtr->state = MTR_ACTIVE; mtr->magic_n = MTR_MAGIC_N; #endif return(mtr); } |
点击F11进入函数,查看动态数据的创建过程:
| 以下是代码片段: /************************************************************************* Initializes a dynamic array. */ UNIV_INLINE dyn_array_t* dyn_array_create( /*=============*/ /* out: initialized dyn array */ dyn_array_t* arr) /* in: pointer to a memory buffer of size sizeof(dyn_array_t) */ { ut_ad(arr); ut_ad(DYN_ARRAY_DATA_SIZE < DYN_BLOCK_FULL_FLAG); arr->heap = NULL; arr->used = 0; #ifdef UNIV_DEBUG arr->buf_end = 0; arr->magic_n = DYN_BLOCK_MAGIC_N; #endif return(arr); } |
执行该函数之后,结构体的情况见图1:

创建完成之后,我们就可以使用该动态数组了。作为例子,我们在mtr_memo_push函数体内设置断点。
| 以下是代码片段: /******************************************************* Pushes an object to an mtr memo stack. */ UNIV_INLINE void mtr_memo_push( /*==========*/ mtr_t* mtr, /* in: mtr */ void* object, /* in: object */ ulint type) /* in: object type: MTR_MEMO_S_LOCK, ... */ { dyn_array_t* memo; mtr_memo_slot_t* slot; ut_ad(object); ut_ad(type >= MTR_MEMO_PAGE_S_FIX); ut_ad(type <= MTR_MEMO_X_LOCK); ut_ad(mtr); ut_ad(mtr->magic_n == MTR_MAGIC_N); memo = &(mtr->memo); //从动态中分配大小为sizeof(mtr_memo_slot_t)的空间 //然后对获取的空间进行赋值 slot = dyn_array_push(memo, sizeof(mtr_memo_slot_t)); slot->object = object; slot->type = type; } |
从中我们可以得知dyn_array_pus是分配空间的地方(dyn_array_open函数有这样的功能,本文后面会提到),我们按F11进入该函数体。
| 以下是代码片段: /************************************************************************* Makes room on top of a dyn array and returns a pointer to the added element. The caller must copy the element to the pointer returned. */ UNIV_INLINE void* dyn_array_push( /*===========*/ /* out: pointer to the element */ dyn_array_t* arr, /* in: dynamic array */ ulint size) /* in: size in bytes of the element */ { dyn_block_t* block; ulint used; ut_ad(arr); ut_ad(arr->magic_n == DYN_BLOCK_MAGIC_N); ut_ad(size <= DYN_ARRAY_DATA_SIZE); ut_ad(size); //步骤1:取得使用的used //存在多个节点是,arr表示的是链表中的首节点 block = arr; used = block->used; //步骤2:如果首结点block有足够的空间存储,则返回指针,并修改used值。这种情况只出现在:该动态数组只有一个节点。 // used + size <= DYN_ARRAY_DATA_SIZE表示有足够的空间存储 if (used + size > DYN_ARRAY_DATA_SIZE) { /* Get the last array block */ //步骤3:首结点没有空间存储,则取得base列表的最后一个结点 //该函数等价于:block =UT_LIST_GET_LAST(arr->base); //如果有多个节点,首先肯定不符合used + size <= DYN_ARRAY_DATA_SIZE,在后文中有描述。 block = dyn_array_get_last_block(arr); used = block->used; //步骤4:如果最后一个结点有足够空间,则分配 //否则增加一个新的block if (used + size > DYN_ARRAY_DATA_SIZE) { block = dyn_array_add_block(arr); used = block->used; } } block->used = used + size; ut_ad(block->used <= DYN_ARRAY_DATA_SIZE); return((block->data) + used); } |
该函数的功能就是进行分配空间,如果有足够的空间则分配,否则就调用函数dyn_array_add_block生成一个新的block。假象现在的情形是一个block扩展为两个block的情况。查看该函数的实现。
| 以下是代码片段: /**************************************************************** Adds a new block to a dyn array. */ dyn_block_t* dyn_array_add_block( /*================*/ /* out: created block */ dyn_array_t* arr) /* in: dyn array */ { mem_heap_t* heap; dyn_block_t* block; ut_ad(arr); ut_ad(arr->magic_n == DYN_BLOCK_MAGIC_N); //步骤1:结点是1扩展为2,还是n扩展为 n+1(n>=2) // arr->heap=NULL则是1扩展为 2,将自己作为首结点放在链表上,并分配一个内存堆 if (arr->heap == NULL) { UT_LIST_INIT(arr->base); UT_LIST_ADD_FIRST(list, arr->base, arr); //1扩展为 2的时候,创建一个heap,n扩展 n+1(n>=2)时,则使用该heap arr->heap = mem_heap_create(sizeof(dyn_block_t)); } //步骤2:取得最后一个结点,将该block的used字段进行DYN_BLOCK_FULL_FLAG与操作,表示该结点已经使用满。每增加一个新的block总要将前一个block设置为已满,因此只有最后一个block是可用的。即使如前文所例,500字节不够用时创建了一个新的block,第二次有申请10个字节时,显示显示该块的大小>512了,因为DYN_BLOCK_FULL_FLAG的值为:0x1000000UL block = dyn_array_get_last_block(arr); block->used = block->used | DYN_BLOCK_FULL_FLAG; heap = arr->heap; //步骤3:创建一个新结点,并插入到链表尾 block = mem_heap_alloc(heap, sizeof(dyn_block_t)); block->used = 0; UT_LIST_ADD_LAST(list, arr->base, block); return(block); } |
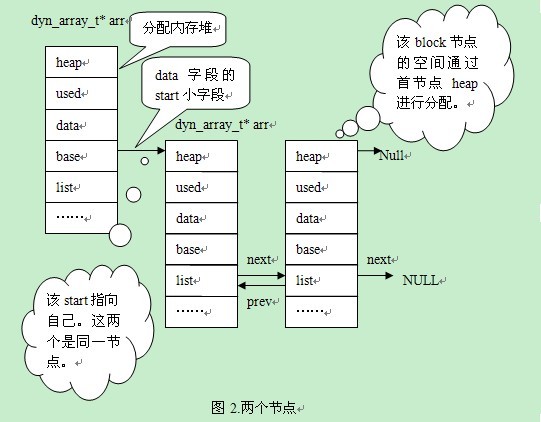
1个结点扩展为2个结点后,见图2(prev和next指向结构的首字节,便于绘图进行了简化,此处加以说明。list的prev和next参考前一篇文章):
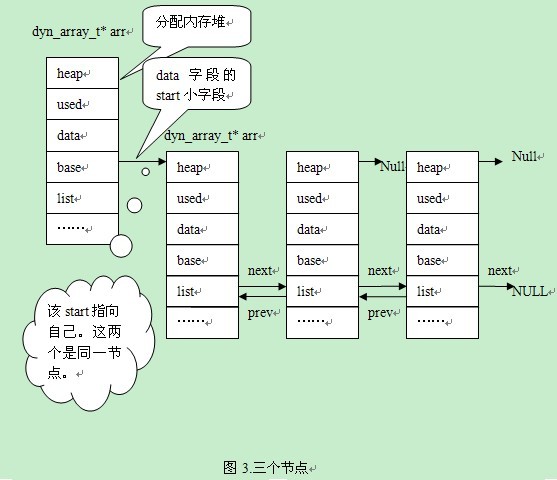
2个结点扩展为3个结点,见图3:
到这里,我们就解决了前面的三个问题。问题1:dyn_array_t与dyn_block_t是同样的定义,而一个动态数组只有一个首结点,那么UT_LIST_BASE_NODE_T(dyn_block_t) base成员是不是每个结构体都是有效的?”
Alex:“这个问题我明白,只有首结点的base是有效的。从图1中可以看出,只有一个结点时,base是无效。图2中,arr的base有两个成员,首结点是第一个成员,新增加的结点在首结点的后面。图3中,arr的base有三个成员,新增的成员在链表尾。”
Bingxi:“问题2:一开始分配的时候只分配了一个结构体,也就是512字节的大小,如果不够用,则扩展了一个,插入到链表里面,链表成员是1个还是2个?”
Alex:“从1个扩展到2个,链表的成员是2。”
Bingxi:“问题3:使用的时候,如何判断一个block已经使用满了,比如前面我们说到一个情况:500个字节剩下了12个不够18个时候,产生了一个新的block,假设这时候要使用其中的10个字节,两个block都是符合,用哪个?如果用后一个,怎么标识前一个是满的。”
Alex:“始终只有最后一个结点可能被使用,只有一个成员时,本身就是最后一个结点。新增结点时,会将前一个结点设置为已满。设置方法如下:
| 以下是代码片段: block->used = block->used | DYN_BLOCK_FULL_FLAG; |
这样进行分配操作时候,used + size > DYN_ARRAY_DATA_SIZE这个条件一定为真。表示首结点已经用满了,然后取最后一个结点。该条件只有一种情况为否,就是动态数组只有一个成员。
| 以下是代码片段: if (used + size > DYN_ARRAY_DATA_SIZE) { /* Get the last array block */ block = dyn_array_get_last_block(arr); used = block->used; if (used + size > DYN_ARRAY_DATA_SIZE) { block = dyn_array_add_block(arr); used = block->used; } } |
Bingxi:“good,我现在问第4个问题:我们需要插入三个元素,我们插入一个元素,就需要修改一次used,再插入,又得调用push函数进行操作。频繁的对dyn的数据结构进行操作。这样的效率是很低的。”
Alex:“稍等,我看下代码。找到了,通过dyn_array_open、dyn_array_close函数可以解决这个问题。这两个函数建议大家看下。另外,我也问你第5个问题,是不是大于512字节的数据就不能插入?”
Bingxi:“这个问题,请参考函数dyn_push_string。其它的函数也看一下,养成看函数的习惯,呵呵。今天就到这儿吧。”
Alex:“ok”
建议继续学习:
- Innodb IO优化-配置优化 (阅读:7333)
- Innodb分表太多或者表分区太多,会导致内存耗尽而宕机 (阅读:7096)
- Innodb 表和索引结构 (阅读:5587)
- InnoDB线程并发检查机制 (阅读:5092)
- Innodb如何使用内存 (阅读:4762)
- 快速预热Innodb Buffer Pool的方法 (阅读:4636)
- Innodb文件表空间结构 (阅读:4648)
- InnoDB的缓存替换策略及其效果 (阅读:4424)
- 多版本并发控制:PostgreSQL vs InnoDB (阅读:4272)
- InnoDB之Dirty Page、Redo log (阅读:4121)
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:yzyangwanfu 来源: 杨万富的专栏
- 标签: innodb mysql内核 动态数组
- 发布时间:2010-08-01 20:09:16

-
 [895] WordPress插件开发 -- 在插件使用
[895] WordPress插件开发 -- 在插件使用 -
[136] 解决 nginx 反向代理网页首尾出现神秘字
-
[56] 整理了一份招PHP高级工程师的面试题
-
[54] Innodb分表太多或者表分区太多,会导致内
-
[53] 如何保证一个程序在单台服务器上只有唯一实例(
-
[53] 用 Jquery 模拟 select
-
[52] 海量小文件存储
-
[52] CloudSMS:免费匿名的云短信
-
[52] 全站换域名时利用nginx和javascri
-
[52] 分享一个JQUERY颜色选择插件
