二级索引与索引Join是多数业务系统要求存储引擎提供的基本特性,RDBMS早已支持,NOSQL阵营也在摸索着符合自身特点的最佳解决方案。
这篇文章会以HBase做为对象来讨论如何基于Hbase构建二级索引与实现索引join。文末同时会列出目前已知的包括0.19.3版secondary index, ITHbase, Facebook方案和官方Coprocessor的介绍。
理论目标
在HBase中实现二级索引与索引Join需要考虑三个目标:
1,高性能的范围检索。
2,数据的低冗余(存储所占的数据量)。
3,数据的一致性。
性能与数据冗余,一致性是相互制约的关系。
如果你实现了高性能地范围检索,必然需要靠冗余索引数据来提升性能,而数据冗余会导致更新数据时难以实现一致性,特别是分布式场景下。
如果你不要求高效地范围检索,那么可以不考虑产生冗余数据,一致性问题也可以间接避免,毕竟share nothing是公认的最简单有效的解决方案。
理论结合实际,下文会以实例的方式来阐述各个方案是如何选择偏重点。
这些方案是经过笔者资料查阅和同事的不断交流后得出的结论,如有错误,欢迎指正:
1,按索引建表
每一个索引建立一个表,然后依靠表的row key来实现范围检索。row key在HBase中是以B+ tree结构化有序存储的,所以scan起来会比较效率。
单表以row key存储索引,column value存储id值或其他数据 ,这就是Hbase索引表的结构。
如何Join?
多索引(多表)的join场景中,主要有两种参考方案:
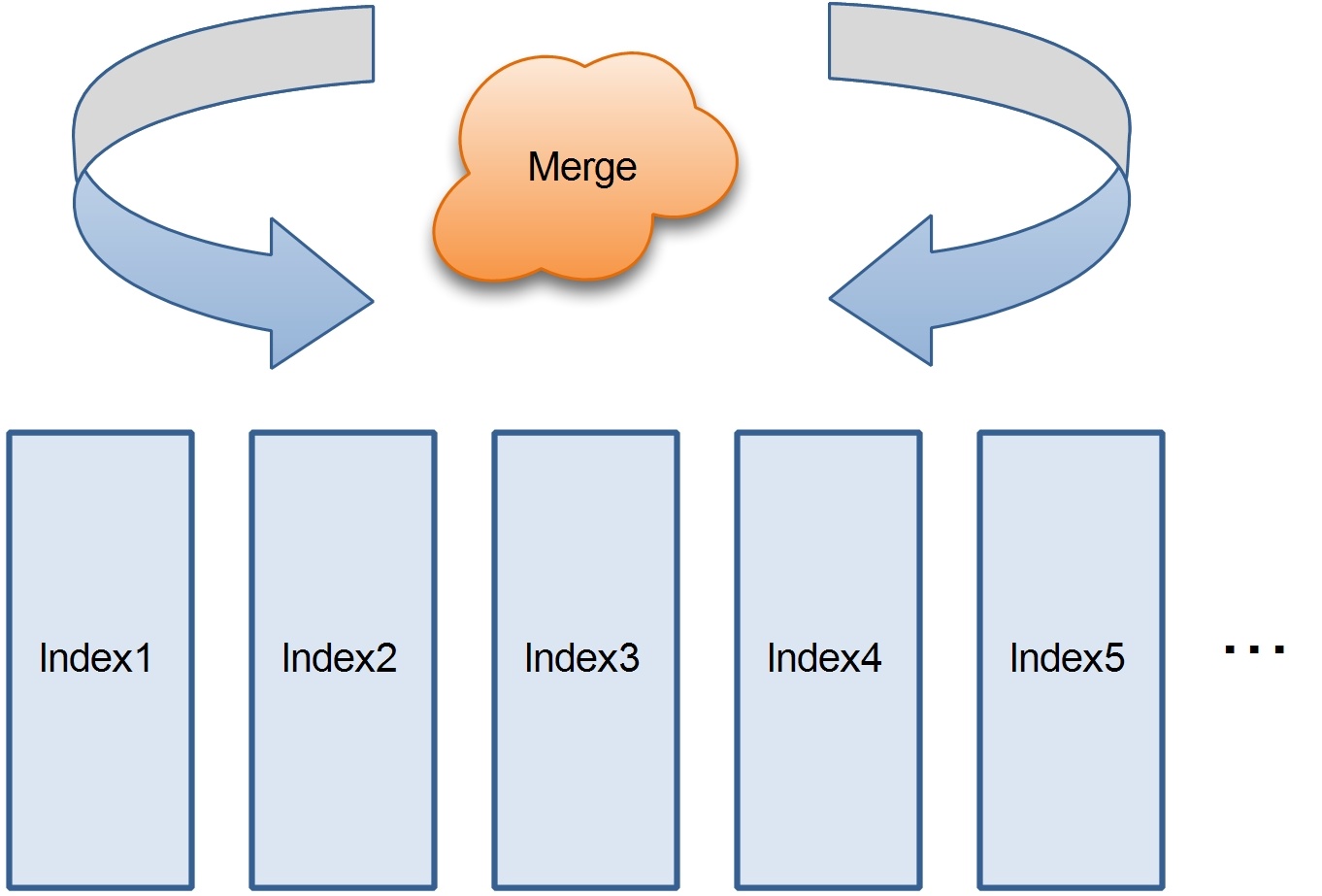
1,按索引的种类扫描各自独立的单索引表,最后将扫描结果merge。
这个方案的特点是简单,但是如果多个索引扫描结果数据量比较大的话,merge就会遇到瓶颈。
比如,现在有一张1亿的用户信息表,建有出生地和年龄两个索引,我想得到一个条件是在杭州出生,年龄为20岁的按用户id正序排列前10个的用户列表。
有一种方案是,系统先扫描出生地为杭州的索引,得到一个用户id结果集,这个集合的规模假设是10万。
然后扫描年龄,规模是5万,最后merge这些用户id,去重,排序得到结果。
这明显有问题,如何改良?
保证出生地和年龄的结果是排过序的,可以减少merge的数据量?但Hbase是按row key排序,value是不能排序的。
变通一下 - 将用户id冗余到row key里?OK,这是一种解决方案了,这个方案的图示如下:
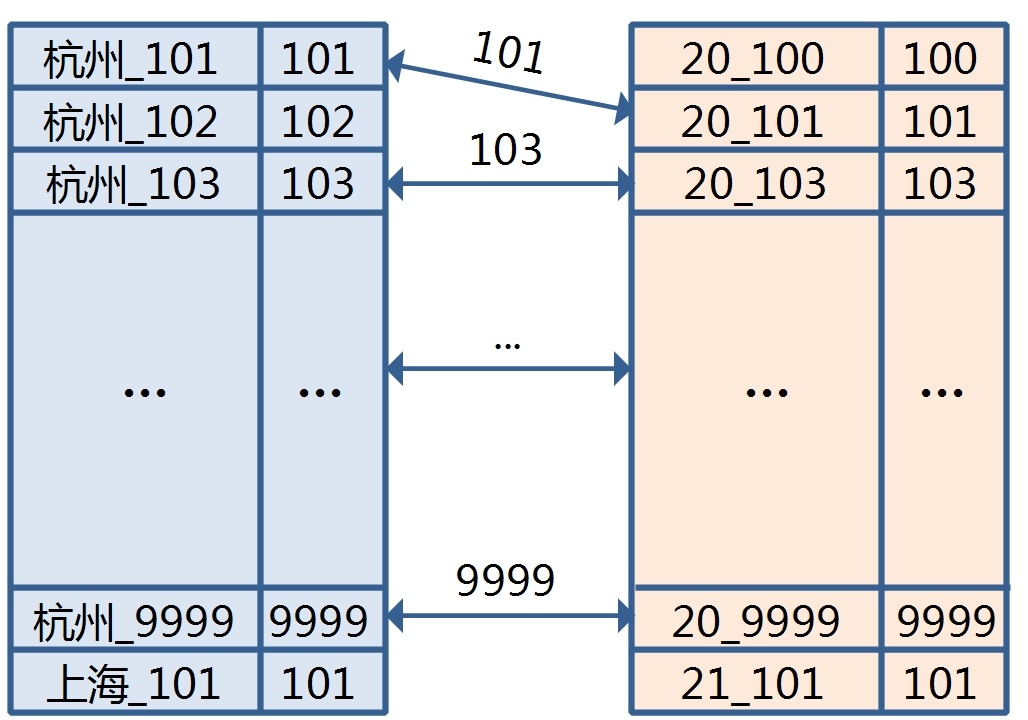
merge时提取交集就是所需要的列表,顺序是靠索引增加了_id,以字典序保证的。
2, 按索引查询种类建立组合索引。
在方案1的场景中,想象一下,如果单索引数量多达10个会怎么样?10个索引,就要merge 10次,性能可想而知。
解决这个问题需要参考RDBMS的组合索引实现。
比如出生地和年龄需要同时查询,此时如果建立一个出生地和年龄的组合索引,查询时效率会高出merge很多。
当然,这个索引也需要冗余用户id,目的是让结果自然有序。结构图示如下:
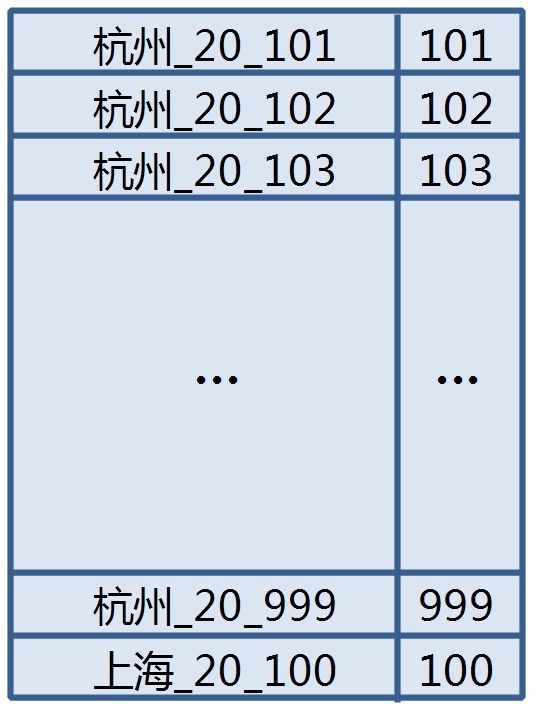
这个方案的优点是查询速度非常快,根据查询条件,只需要到一张表中检索即可得到结果list。缺点是如果有多个索引,就要建立多个与查询条件一一对应的组合索引,存储压力会增大。
在制定Schema设计方案时,设计人员需要充分考虑场景的特点,结合方案一和二来使用。下面是一个简单的对比:
| 单索引 | 组合索引 | |
| 检索性能 | 优异 | 优异 |
| 存储 | 数据不冗余,节省存储。 | 数据冗余,存储比较浪费。 |
| 事务性 | 多个索引保证事务性比较困难。 | 多个索引保证事务性比较困难。 |
| join | 性能较差 | 性能优异 |
| count,sum,avg,etc | 符合条件的结果集全表扫描 | 符合条件的结果集全表扫描 |
从上表中可以得知,方案1,2都存在更新时事务性保证比较困难的问题。如果业务系统可以接受最终一致性的话,事务性会稍微好做一些。否则只能借助于复杂的分布式事务,比如JTA,Chubby等技术。
count, sum, avg, max, min等聚合功能,Hbase只能通过硬扫的方式,并且很悲剧,你可能需要做一些hack操作(比如加一个CF,value为null),否则你在扫描时可能需要往客户端传回所有数据。
当然你可以在这个场景上做一些优化,比如增加状态表等,但复杂性带来的风险会更高。
还有一种终极解决方案就是在业务上只提供上一页和下一页,这或许是最简单有效的方案了。
2,单张表多个列族,索引基于列
Hbase提供了列族Column Family特性。
列索引是将Column Family做为index,多个index值散落到Qualifier,多个column值依据version排列