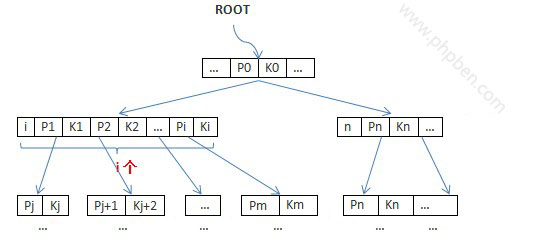
Oracle字符类型存数字及查询数字时使用单引号走不走索引的问题
这篇文章解决的是一个在实际数据库开发中容易产生争议的问题:用varchar2类型存放的数字字段,在查询条件中给数字加上单引号,到底会不会导致索引失效?作者从团队内部的实际分歧出发,通过在Oracle 11.2.0.4.0版本上进行测试来验证结论。 文章首先通过建表和数据准备,复现了讨论的场景。核心对比点在于两种常见的错误认知:一种是认为“char类型存数字,查询不加单引号不走索引”;另一种则想验证“varchar2类型存数字,查询加单引号是否还会走索引”。作者通过具体的执行计划截图(文中虽未显示但提到测试信息),清晰地展示了不同写法下的索引使用情况。 最终得出了明确的结论:对于varchar2类型字段,无论在查询时是否为数字加上单引号,都能正常走索引。这个结果厘清了一个常见的误解,并为后续将varchar2字段改为number类型的设计决策提供了数据支持。对于DBA和开发人员而言,理解数据库在处理隐式类型转换时的具体行为,有助于编写出既准确又高效的SQL语句。