MySQL源代码的海洋中游弋 初探MySQL之SQL执行过程
导读:
2012年5月12日,MySQL技术群-北京技术圈的MySQL爱好者,聚集搜狐公司,举办MySQL数据库技术沙龙,本文内容为搜狐DBA团队古雷(外号:古大师,因研究佛学而来)分享的MySQL之SQL执行过程,先整理成文章的方式供大家阅读,古大师也是mysqlops中文网的技术编辑之一。
序言:
不积跬步,无以至千里;不积小流,无以成江海——《劝学》荀子
吾生也有涯,而知也无涯。以有涯随无涯,殆已——《养生主》庄子
Group by
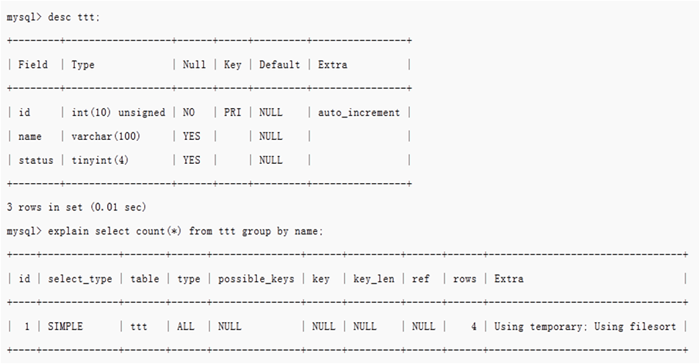
select name1 from test group by name1;
从InnoDB存储引擎表读出一条记录,写入临时表,循环往复
临时表中,group by的key(本例中为name1)
-每个KEY值只有一行记录
-(相同KEY值写入,检测到重复键错误,忽略此错误并继续)
从临时表中读取记录(全部或KEY)
排序(filesort)
发送排序结果
Group by + sum
select sum(id) from test group by name1;
从InnoDB存储引擎表读取一条记录,写入临时表,循环往复
临时表中group by的key(本例中为name1)
-有一个hash索引
-每个KEY值只有一行记录
-写入临时表每行记录时,更新相同KEY的sum值
以group by的key对临时表排序(filesort)
发送排序结果
If you use GROUP BY, output rows are sorted according to the GROUP BY columns as if you had an ORDER BY for the same columns. To avoid the overhead of sorting that GROUP BY produces, add ORDER BY NULL
临时表写入的痕迹1
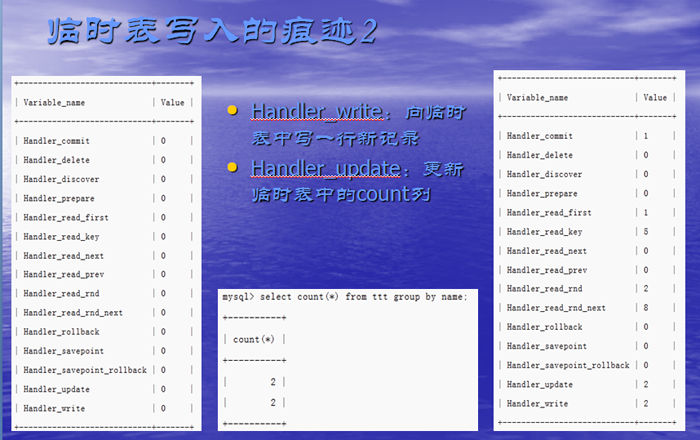
group by使用索引时,不需要临时表
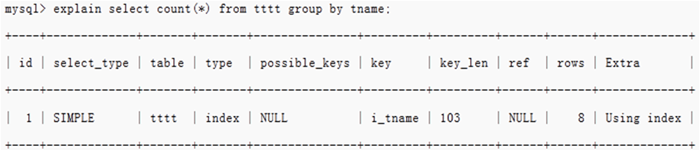
从索引中读取记录,计算count,由于索引是按照group by的key排序的,因此可以边读记录边计算当前key的count,当读的key值要变化时,则刚刚计算的count值就是那个key的最终count值,把结果发送给客户端,再继续从索引读以下记录。
什么是Nested Loop Join(嵌套循环算法)
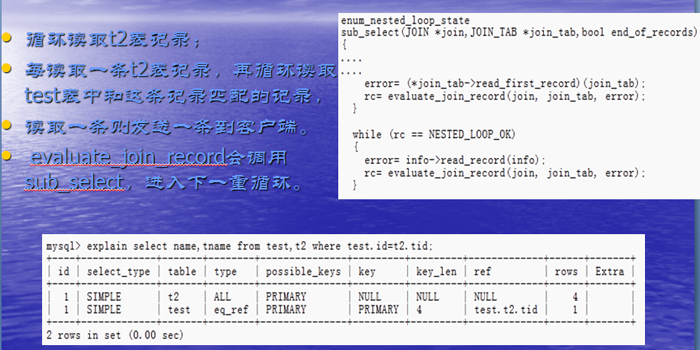
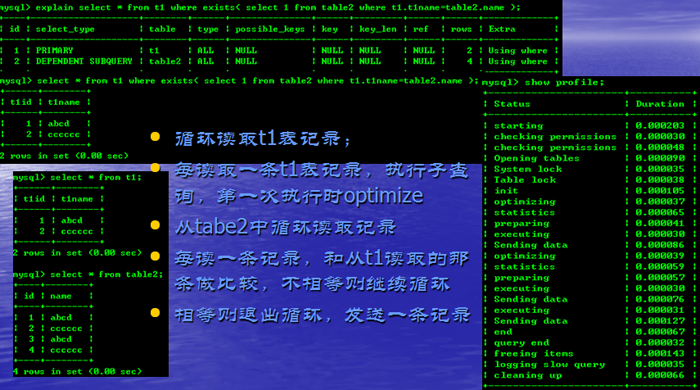
DEPENDENT SUBQUERY
DERIVED(派生表)
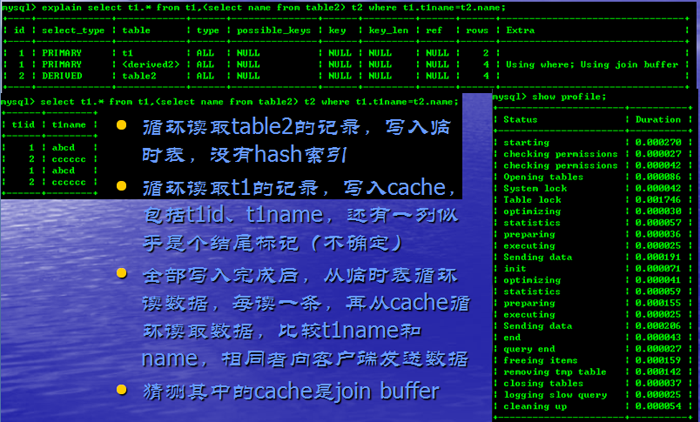
两表JOIN + ORDER BY

循环读取ttt表的记录,写入cache,直至都写完
循环从tttt表中读取记录
每读一条,再循环读取cache中记录,并做比较
满足条件的记录写入临时表
对临时表排序
发送结果

Using join buffer是循环读取big表并与join buffer中的保存的table2记录比较
Using temporary是保存匹配的记录,然后需要排序
总结
之前看手册上的诸多概念,有空中楼阁的感觉
通过跟踪源码,则逐渐有脚踏实地的感觉
希望真正看懂explain的输出
不积跬步,无以至千里;不积小流,无以成江海——《劝学》荀子
吾生也有涯,而知也无涯。以有涯随无涯,殆已——《养生主》庄子
建议继续学习:
- SQL里是否可以使用JOIN (阅读:6197)
- Nginx源码分析-事件循环 (阅读:5690)
- Hive的入口 -- Hive源码解析 (阅读:5485)
- Storm源码浅析之topology的提交 (阅读:5362)
- Hive源码解析-之-语法解析器 (阅读:5097)
- Nginx源码分析-内存池 (阅读:4894)
- Nginx源码分析-Epoll模块 (阅读:4630)
- Lua GC 的源码剖析 (2) (阅读:4604)
- Lua GC 的源码剖析 (4) (阅读:4208)
- ExtJS源码研究笔记之总评 (阅读:3914)
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:MySQLOPS 数据库与运维自动化技术分享 来源: MySQLOPS 数据库与运维自动化技术分享
- 标签: SQL 源码
- 发布时间:2012-05-15 23:30:12

-
 [927] WordPress插件开发 -- 在插件使用
[927] WordPress插件开发 -- 在插件使用 -
[133] 解决 nginx 反向代理网页首尾出现神秘字
-
[52] 如何保证一个程序在单台服务器上只有唯一实例(
-
[52] 整理了一份招PHP高级工程师的面试题
-
[50] 全站换域名时利用nginx和javascri
-
[50] 海量小文件存储
-
[50] 用 Jquery 模拟 select
-
[49] CloudSMS:免费匿名的云短信
-
[48] Innodb分表太多或者表分区太多,会导致内
-
[47] jQuery性能优化指南
