irqbalance项目的主页在这里
irqbalance用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于 Performance mode 或 Power-save mode。处于Performance mode 时,irqbalance 会将中断尽可能均匀地分发给各个 CPU core,以充分利用 CPU 多核,提升性能。
处于Power-save mode 时,irqbalance 会将中断集中分配给第一个 CPU,以保证其它空闲 CPU 的睡眠时间,降低能耗。
在RHEL发行版里这个守护程序默认是开机启用的,那如何确认它的状态呢?
# service irqbalance status
irqbalance (pid PID) is running…
然后在实践中,我们的专用的应用程序通常是绑定在特定的CPU上的,所以其实不可不需要它。如果已经被打开了,我们可以用下面的命令关闭它:
# service irqbalance stop
Stopping irqbalance: [ OK ]
或者干脆取消开机启动:
# chkconfig irqbalance off
下面我们来分析下这个irqbalance的工作原理,好准确的知道什么时候该用它,什么时候不用它。
既然irqbalance用于优化中断分配,首先我们从中断讲起,文章很长,深吸一口气,来吧!
SMP IRQ Affinity 相关东西可以参见 这篇文章
摘抄重点:
SMP affinity is controlled by manipulating files in the /proc/irq/ directory.
In /proc/irq/ are directories that correspond to the IRQs present on your
system (not all IRQs may be available). In each of these directories is
the “smp_affinity” file, and this is where we will work our magic.
说白了就是往/proc/irq/N/smp_affinity文件写入你希望的亲缘的CPU的mask码! 关于如何手工设置中断亲缘性,请参见我之前的博文: 这里 这里
接着普及下概念,我们再来看下CPU的拓扑结构,首先看下Intel CPU的各个部件之间的关系:
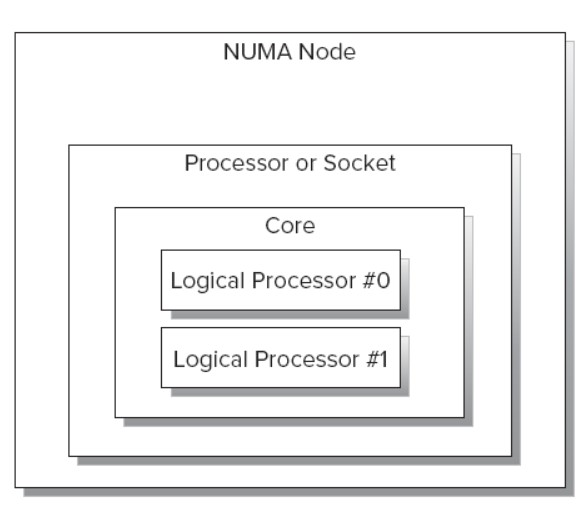
一个NUMA node包括一个或者多个Socket,以及与之相连的local memory。一个多核的Socket有多个Core。如果CPU支持HT,OS还会把这个Core看成 2个Logical Processor。
可以看拓扑的工具很多lscpu或者intel的cpu_topology64工具都可以,可以参考 这里 这里
这次用之前我们新介绍的Likwid工具箱里面的likwid-topology我们可以看到:
./likwid-topology
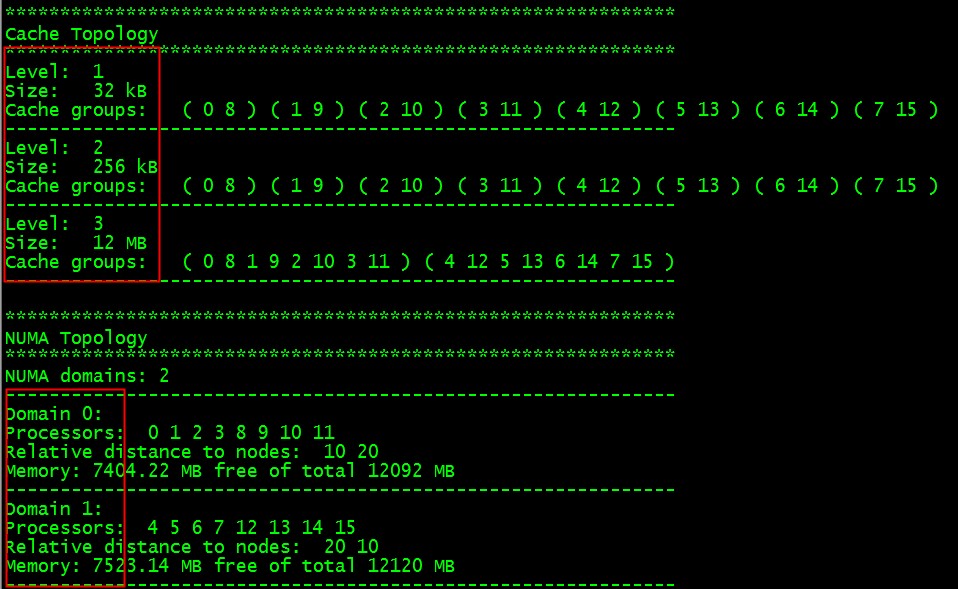
CPU的拓扑结构是各种高性能服务器CPU亲缘性绑定必须理解的东西,有感觉了吗?
有了前面的各种基础知识和名词的铺垫,我们就可以来调查irqbalance的工作原理:
//irqbalance.c
int main(int argc, char** argv)
{
/* ... */
while (keep_going) {
sleep_approx(SLEEP_INTERVAL); //#define SLEEP_INTERVAL 10
/* ... */
clear_work_stats();
parse_proc_interrupts();
parse_proc_stat();
/* ... */
calculate_placement();
activate_mappings();
/* ... */
}
/* ... */
}从程序的主循环可以很清楚的看到它的逻辑,在退出之前每隔10秒它做了以下的几个事情:
1. 清除统计
2. 分析中断的情况
3. 分析中断的负载情况
4. 根据负载情况计算如何平衡中断
5. 实施中断亲缘性变跟
好吧,稍微看下irqbalance如何使用的:
man irqbalance
-oneshot
Causes irqbalance to be run once, after which the daemon exits
-debug
Causes irqbalance to run in the foreground and extra debug information to be printed
在诊断模型下运行irqbalance可以给我们很多详细的信息:
#./irqbalance -oneshot -debug
喝口水,我们接着来分析下各个步骤的详细情况:
先了解下中断在CPU上的分布情况:
$cat /proc/interrupts|tr -s \' \' \'\\t\'|cut -f 1-3
CPU0 CPU1
0: 2622846291
1: 7
4: 234
8: 1
9: 0
12: 4
50: 6753
66: 228
90: 497
98: 31
209: 2 0
217: 0 0
225: 29 556
233: 0 0
NMI: 7395302 4915439
LOC: 2622846035 2622833187
ERR: 0
MIS: 0输出的第一列是中断号,后面的2列是在CPU0,CPU1的中断次数。
但是我们如何知道比如中断是98那个类型的设备呢?不废话,上代码!
//classify.c
char *classes[] = {
"other",
"legacy",
"storage",
"timer",
"ethernet",
"gbit-ethernet",
"10gbit-ethernet",
0
};
#define MAX_CLASS 0x12
/*
* Class codes lifted from pci spec, appendix D.
* and mapped to irqbalance types here
*/
static short class_codes[MAX_CLASS] = {
IRQ_OTHER,
IRQ_SCSI,
IRQ_ETH,
IRQ_OTHER,
IRQ_OTHER,
IRQ_OTHER,
IRQ_LEGACY,
IRQ_OTHER,
IRQ_OTHER,
IRQ_LEGACY,
IRQ_OTHER,
IRQ_OTHER,
IRQ_LEGACY,
IRQ_ETH,
IRQ_SCSI,
IRQ_OTHER,
IRQ_OTHER,
IRQ_OTHER,
};
int map_class_to_level[7] =
{ BALANCE_PACKAGE, BALANCE_CACHE, BALANCE_CACHE, BALANCE_NONE, BALANCE_CORE, BALANCE_CORE, BALANCE_CORE };irqbalance把中断分成7个类型,不同类型的中断平衡的时候作用域不同,有的在PACKAGE,有的在CACHE,有的在CORE。
那么类型信息在那里获取呢?不废话,上代码!
//#define SYSDEV_DIR "/sys/bus/pci/devices"
static struct irq_info *add_one_irq_to_db(const char *devpath, int irq, struct user_irq_policy *pol)
{
...
sprintf(path, "%s/class", devpath);
fd = fopen(path, "r");
if (!fd) {
perror("Can\'t open class file: ");
goto get_numa_node;
}
rc = fscanf(fd, "%x", &class);
fclose(fd);
if (!rc)
goto get_numa_node;
/*
* Restrict search to major class code
*/
class >>= 16;
if (class >= MAX_CLASS)
goto get_numa_node;
new->class = class_codes[class];
if (pol->level >= 0)
new->level = pol->level;
else
new->level = map_class_to_level[class_codes[class]];
get_numa_node:
numa_node = -1;
sprintf(path, "%s/numa_node", devpath);
fd = fopen(path, "r");
if (!fd)
goto assign_node;
rc = fscanf(fd, "%d", &numa_node);
fclose(fd);
assign_node:
new->numa_node = get_numa_node(numa_node);
sprintf(path, "%s/local_cpus", devpath);
fd = fopen(path, "r");
if (!fd) {
cpus_setall(new->cpumask);
goto assign_affinity_hint;
}
lcpu_mask = NULL;
ret = getline(&lcpu_mask, &blen, fd);
fclose(fd);
if (ret <= 0) {
cpus_setall(new->cpumask);
} else {
cpumask_parse_user(lcpu_mask, ret, new->cpumask);
}
free(lcpu_mask);
assign_affinity_hint:
cpus_clear(new->affinity_hint);
sprintf(path, "/proc/irq/%d/affinity_hint", irq);
fd = fopen(path, "r");
if (!fd)
goto out;
lcpu_mask = NULL;
ret = getline(&lcpu_mask, &blen, fd);
fclose(fd);
if (ret <= 0)
goto out;
cpumask_parse_user(lcpu_mask, ret, new->affinity_hint);
free(lcpu_mask);
out:
...
}#上面的c代码翻译成下面的脚本就是:
$cat>x.sh
SYSDEV_DIR="/sys/bus/pci/devices/"
for dev in `ls $SYSDEV_DIR`
do
IRQ=`cat $SYSDEV_DIR$dev/irq`
CLASS=$(((`cat $SYSDEV_DIR$dev/class`)>>16))
printf "irq %s: class[%s] " $IRQ $CLASS
if [ -f "/proc/irq/$IRQ/affinity_hint" ]; then
printf "affinity_hint[%s] " `cat /proc/irq/$IRQ/affinity_hint`
fi
if [ -f "$SYSDEV_DIR$dev/local_cpus" ]; then
printf "local_cpus[%s] " `cat $SYSDEV_DIR$dev/local_cpus`
fi
if [ -f "$SYSDEV_DIR$dev/numa_node" ]; then
printf "numa_node[%s]" `cat $SYSDEV_DIR$dev/numa_node`
fi
echo
done
CTRL+D
$ tree /sys/bus/pci/devices
/sys/bus/pci/devices
|-- 0000:00:00.0 -> ../../../devices/pci0000:00/0000:00:00.0
|-- 0000:00:01.0 -> ../../../devices/pci0000:00/0000:00:01.0
|-- 0000:00:03.0 -> ../../../devices/pci0000:00/0000:00:03.0
|-- 0000:00:07.0 -> ../../../devices/pci0000:00/0000:00:07.0
|-- 0000:00:09.0 -> ../../../devices/pci0000:00/0000:00:09.0
|-- 0000:00:13.0 -> ../../../devices/pci0000:00/0000:00:13.0
|-- 0000:00:14.0 -> ../../../devices/pci0000:00/0000:00:14.0
|-- 0000:00:14.1 -> ../../../devices/pci0000:00/0000:00:14.1
|-- 0000:00:14.2 -> ../../../devices/pci0000:00/0000:00:14.2
|-- 0000:00:14.3 -> ../../../devices/pci0000:00/0000:00:14.3
|-- 0000:00:1a.0 -> ../../../devices/pci0000:00/0000:00:1a.0
|-- 0000:00:1a.7 -> ../../../devices/pci0000:00/0000:00:1a.7
|-- 0000:00:1d.0 -> ../../../devices/pci0000:00/0000:00:1d.0
|-- 0000:00:1d.1 -> ../../../devices/pci0000:00/0000:00:1d.1
|-- 0000:00:1d.2 -> ../../../devices/pci0000:00/0000:00:1d.2
|-- 0000:00:1d.7 -> ../../../devices/pci0000:00/0000:00:1d.7
|-- 0000:00:1e.0 -> ../../../devices/pci0000:00/0000:00:1e.0
|-- 0000:00:1f.0 -> ../../../devices/pci0000:00/0000:00:1f.0
|-- 0000:00:1f.2 -> ../../../devices/pci0000:00/0000:00:1f.2
|-- 0000:00:1f.3 -> ../../../devices/pci0000:00/0000:00:1f.3
|-- 0000:00:1f.5 -> ../../../devices/pci0000:00/0000:00:1f.5
|-- 0000:01:00.0 -> ../../../devices/pci0000:00/0000:00:01.0/0000:01:00.0
|-- 0000:01:00.1 -> ../../../devices/pci0000:00/0000:00:01.0/0000:01:00.1
|-- 0000:04:00.0 -> ../../../devices/pci0000:00/0000:00:09.0/0000:04:00.0
`-- 0000:05:00.0 -> ../../../devices/pci0000:00/0000:00:1e.0/0000:05:00.0
$chmod +x x.sh
$./x.sh|grep 98
irq 98: class[2] local_cpus[00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000]简单的分析下数字:class_codes[2]=IRQ_ETH 也就是说这个中断是块网卡。
那中断的负载是怎么算出来的呢?继续看代码!
//procinterrupts.c
void parse_proc_stat(void)
{
...
file = fopen("/proc/stat", "r");
if (!file) {
log(TO_ALL, LOG_WARNING, "WARNING cant open /proc/stat. balacing is broken\\n");
return;
}
/* first line is the header we don\'t need; nuke it */
if (getline(&line, &size, file)==0) {
free(line);
log(TO_ALL, LOG_WARNING, "WARNING read /proc/stat. balancing is broken\\n");
fclose(file);
return;
}
cpucount = 0;
while (!feof(file)) {
if (getline(&line, &size, file)==0)
break;
if (!strstr(line, "cpu"))
break;
cpunr = strtoul(&line[3], NULL, 10);
if (cpu_isset(cpunr, banned_cpus))
continue;
rc = sscanf(line, "%*s %*d %*d %*d %*d %*d %d %d", &irq_load, &softirq_load);
if (rc < 2)
break;
cpu = find_cpu_core(cpunr);
if (!cpu)
break;
cpucount++;
/*
* For each cpu add the irq and softirq load and propagate that
* all the way up the device tree
*/
if (cycle_count) {
cpu->load = (irq_load + softirq_load) - (cpu->last_load);
/*
* the [soft]irq_load values are in jiffies, which are
* units of 10ms, multiply by 1000 to convert that to
* 1/10 milliseconds. This give us a better integer
* distribution of load between irqs
*/
cpu->load *= 1000;
}
cpu->last_load = (irq_load + softirq_load);
}
...
}相当于以下的命令:
$grep cpu015/proc/stat
cpu15 30068830 85841 22995655 3212064899 536154 91145 2789328 0
我们学习下 /proc/stat 的文件格式!
关于CPU这行摘抄如下:
cpu — Measures the number of jiffies (1/100 of a second for x86 systems) that the system has been in user mode, user mode with low priority (nice), system mode, idle task, I/O wait, IRQ (hardirq), and softirq respectively. The IRQ (hardirq) is the direct response to a hardware event. The IRQ takes minimal work for queuing the “heavy” work up for the softirq to execute. The softirq runs at a lower priority than the IRQ and therefore may be interrupted more frequently. The total for all CPUs is given at the top, while each individual CPU is listed below with its own statistics. The following example is a 4-way Intel Pentium Xeon configuration with multi-threading enabled, therefore showing four physical processors and four virtual processors totaling eight processors.
可以知道这行的第7,8项分别对应着中断和软中断的次数,二者加起来就是我们所谓的CPU负载。
这个和结果和irqbalance报告的中断的情况是吻合的,见图:
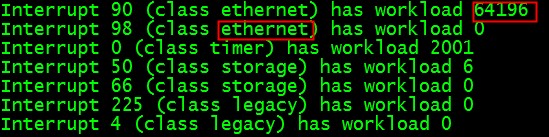
是不是有点晕了,喝口水!
我们继续来看下整个Package层面irqbalance是如何计算负载的,从下面的图结合前面的那个CPU拓扑很清楚的看到:
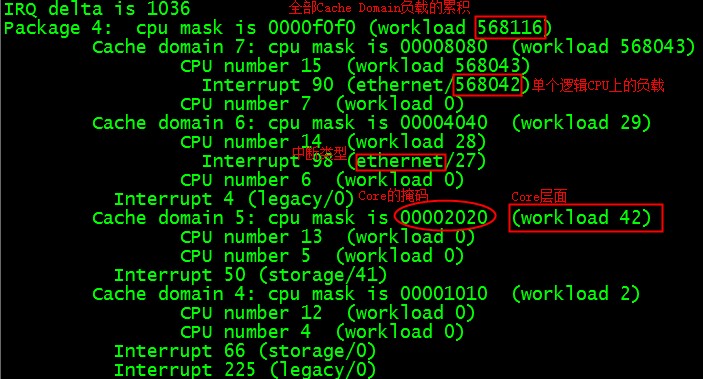
每个CORE的负载是附在上面的中断的负载的总和,每个DOMAIN是包含的CORE的总和,每个PACKAGE包含的DOMAIN的总和,就像树层次一样的计算。
知道了每个CORE, DOMAIN,PACKAGE的负载的情况,那么剩下的就是找个这个中断类型所在作用域范围内最轻的对象把中断迁移过去。
迁移的依据正是之前看过的这个东西:
int map_class_to_level[7] =
{ BALANCE_PACKAGE, BALANCE_CACHE, BALANCE_CACHE, BALANCE_NONE, BALANCE_CORE, BALANCE_CORE, BALANCE_CORE };
水喝多了,等等放下水先,回来继续!
最后那irqbalance系统是如何实施中断亲缘性变跟的呢,继续上代码:
// activate.c
static void activate_mapping(struct irq_info *info, void *data __attribute__((unused)))
{
...
if ((hint_policy == HINT_POLICY_EXACT) &&
(!cpus_empty(info->affinity_hint))) {
applied_mask = info->affinity_hint;
valid_mask = 1;
} else if (info->assigned_obj) {
applied_mask = info->assigned_obj->mask;
valid_mask = 1;
if ((hint_policy == HINT_POLICY_SUBSET) &&
(!cpus_empty(info->affinity_hint)))
cpus_and(applied_mask, applied_maskapplied_mask, info->affinity_hint);
}
/*
* only activate mappings for irqs that have moved
*/
if (!info->moved && (!valid_mask || check_affinity(info, applied_mask)))
return;
if (!info->assigned_obj)
return;
sprintf(buf, "/proc/irq/%i/smp_affinity", info->irq);
file = fopen(buf, "w");
if (!file)
return;
cpumask_scnprintf(buf, PATH_MAX, applied_mask);
fprintf(file, "%s", buf);
fclose(file);
info->moved = 0; /*migration is done*/
}
void activate_mappings(void)
{
for_each_irq(NULL, activate_mapping, NULL);
}上面的代码简单的翻译成shell就是:
#echo MASK > /proc/irq/N/smp_affinity
当然如果用户设置的策略如果是HINT_POLICY_EXACT,那么我们会参照/proc/irq/N/affinity_hint设置
策略如果是HINT_POLICY_SUBSET, 那么我们会参照/proc/irq/N/affinity_hint | applied_mask 设置。
好吧,总算分析完成了!
总结:
irqbalance根据系统中断负载的情况,自动迁移中断保持中断的平衡,同时会考虑到省电因素等等。 但是在实时系统中会导致中断自动漂移,对性能造成不稳定因素,在高性能的场合建议关闭。