作者:腾霄 (一淘及搜索事业部-搜索技术-算法技术-主搜索与商城)
一、前言
个性化是搜索技术、计算广告技术以及电子商务领域的一个发展趋势和时髦话题。随着互联网技术的发展,搜索技术越来越为互联网用户所熟悉。但人们已经不满足于一个完全由自己输入而得到返回内容的不聪明的“机器”,人们更希望一个能自动理解、甚至提前猜测自己意图,并能将这种意图准确地体现在返回结果的聪明系统,这个系统在面对不同的用户输入相同的搜索语句时,能够根据用户的差异,展现用户最希望看到的结果。要实现这个聪明的个性化的系统,至少需要做到以下两点:
1. 对用户属性、意图和兴趣的理解或用户所在群体特点的理解。这是实现个性化的根本。
2. 在理解用户的基础上,如何将用户的数据和具体的应用结合,设计一个合理的个性化推荐算法或者对检索结果的个性化排序算法,将用户最感兴趣的产品或者广告展给用户,决定了我们的系统是否能为用户带来良好的体验。
一个成熟的个性化系统,将不仅提供个性化的数据,也要提供个性化推荐或者个性化排序的方法。
在淘宝的环境下,用户主要的目的是购物或了解商品信息。不同的用户群体在淘宝上的行为存在着很大的差异,因为用户之间的性别、年龄、地域、收入、职业等等的差别,就会在他们选择商品时,体现出对商品的类目、性别属性、价格、风格的不同需求和偏好。我们可以通过获取用户的这些固有或相当长一段时间不变的属性,也可以通过用户的过往的购物相关的行为挖掘用户的偏好,在商品的展现或者推送上进行属性、偏好的匹配。但即便是相同属性的用户或者过往购物行为相似的用户,在不同时间或者情景下,也存在个体的巨大差异。
一个人的兴趣偏好是随时处在变化中的。这就要求个性化系统不仅需要较高的准确性、较高的覆盖率、同时还需要具备良好的实时性,将用户最新的行为和偏好,反馈给系统,并体现在随后的搜索结果中。一个具备良好实时性的系统不仅可以更准确地把握用户的兴趣偏好,对那些新的用户,包括新注册用户及清除过cookie无法获取用户过往历史信息的用户,实时系统也能对他们进行个性化的影响。
本文我们将主要介绍个性化实时分析系统PORA,介绍其系统的框架,计算内容,如何在淘宝的搜索排序上进行应用,以及取得的效果和不足,并对后续的改进给出计划。
二、个性化实时计算系统(PORA)
1. 简介
PORA是Personal OfflineRealtime Analysis的简称。我们之所以称其定义为Offline是针对其架构而言,PORA系统只负责分析和计算用户最近的行为偏好,将计算的结果存入数据库中,由应用方来调用,应用方不需要在线调用PORA系统进行online计算,而是直接获取已经存在的数据。PORA系统更像是一个忠实的幕后工作者,默默地获取用户的数据,默默地进行计算,默默地把数据存入到数据库,然后循环往复,这些对应用方来说都是透明的,应用方看到的只是数据库中的用户数据,甚至都不知道其背后有这一套系统在运行。但是PORA又是一个高效、可靠的实时计算系统,用户刚刚发生过的一次行为,就能马上被PORA获知,并将这次行为合并到用户之前已经发生过的行为中,实时更新到用户的数据中。正常状况下,从用户的行为发生到最后的数据更新,整个过程用时在300ms左右,对于正常的用户(不是爬虫),这个时间已经足以对用户的下一次行为进行反馈。
2. PORA框架
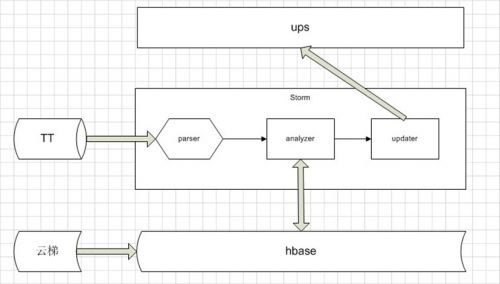
(图1 PORA框架)
PORA是基于HBASE+Storm的实时流计算系统,其核心部分是Storm的流计算框架。系统从TT(time tunnel,淘宝实时日志通道)中订阅用户日志数据,并和已经存在的中间数据一起进行计算,并将最终的结果更新到UPS中。Hbase中存放用户的中间计算结果和历史数据,最初的历史数据来源自云梯上计算的用户历史偏好。UPS(User Profile System)是一个分布式的k/v数据库,为应用方提供数据服务。
Storm的实时处理组件如下:
1) Parser组件
实现为storm中的spout.从TT中取日志,解析出需要的四个字段按照用户的id做哈希发送给analyzer使用ack机制,但是失败后不重发,仅仅打印失败的消息数做流量控制。
2) analyzer
实现为storm中的bolt。是整个实时计算系统的核心组件。根据用户的日志数据、结合用户的历史数据计算出用户最新的兴趣偏好。将计算后的用户数据以用户id为哈希发送给updater。
3) updater
实现为storm的bolt,根据用户id和类目将用户属性数据更新到ups中。这里额外补充下,UPS是以用户id为一级key。二级key将有类目,店铺,以及其他类型信息作为区分。
在我们最新的实现中,storm的组件将是一个基于一个框架的插件化模块,可以根据不同的需求,灵活地扩展计算功能。
三、个性化实时数据的应用场景分析
个性化实时数据是最能直接体现用户当前兴趣和意图的数据,直接和用户的下一步行为相关。比如搜索的点击倾向、商品的购买倾向等。过往的数据统计也充分显示,利用用户的实时偏好数据进行行为定向的广告推送往往能取得相比其他方式更好的效果。我们分析实时数据的应用场景大致有以下几种:
1) 个性化推荐。个性化推荐是根据不同的用户自身的偏好,在一个较大的推荐内容候选集中选择用户最感兴趣的内容进行精准投放。在淘宝的环境下,我们就是在在庞大的商品候选集中,选择用户最感兴趣的商品展现给用户。这种推荐又分多种,一种是搜索页的推荐,即在搜索的正常展现结果之外,再额外推荐和用户当前搜索及用户过去兴趣都相关的商品,增加用户购买商品的数量。二是在用户发生具体的商品行为(浏览、收藏或者购买商品)时,推荐给用户和当前商品相关的商品,因为淘宝商品的丰富程度,和当前商品相关的商品数量可能非常庞大,我们在这个庞大的候选集中,选择和用户最近兴趣最相关的商品,将会有效提高推荐效率。
2) retargeting。在用户没有具体的商品搜索行为或者购物意向时,根据用户历史或近期的行为数据和偏好,将用户最近访问过的店铺或者类目的商品推送给用户,适合于店铺的新品推荐和类目热门商品推荐等。
3) 搜索重排序。如前文所述,不同的用户在搜索同样的query时,他们希望看到的结果不尽相同,用户更希望看到和自己的兴趣最匹配,以图最相关的商品展现在搜索结果的最前面。这是提高用户搜索体验的最好方式,同时也是缩短用户购物路径的有效方式。我们在商品的正常的相关性排序基础上,增加用户个性化的因素对商品进行重排序,使得排序结果直接和用户意图相关,尤其是和用户最近的兴趣相关,使用户实时感受到数据的动态变化和调整。
四、个性化实时数据的应用尝试和效果分析
为了验证我们的实时数据,我们在搜索的环境下进行应用尝试,使我们的搜索排序结果满足个性化在提升用户的体验,缩短用户的购物路径上的需求。这需要我们在排序时将用户的个性化偏好体现在搜索结果的排序上。为了实现这个目标,我们在正常的搜索排序的基础上,增加了重排序(resort)模块。
resort的逻辑位置如下图所示:
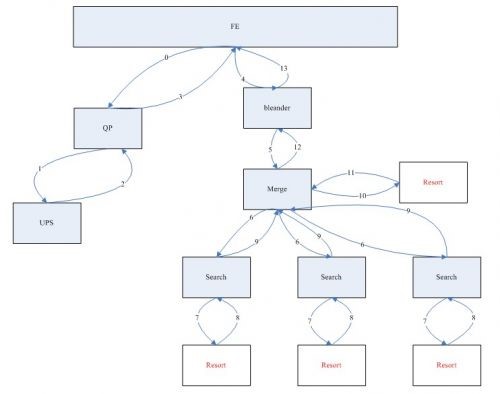
(图2 resort模块逻辑位置图)
图中,FE是展现前端,QP是搜索query的处理模块,同时负责调用UPS中的用户信息。blender是前端和引擎之间的中间处理模块,将搜索引擎的结果根据不同的调用需求进行不同的处理,分离具体业务和引擎之间的逻辑关系。Resort在search端和merge端都会被调用。在search端的调用,Resort会进行个性化分数的计算,并将个性化分数和商品的质量分,相关性分数等进行融合,得到一个排序分数,并对商品进行排序。同样在merge端我们也会做相应的排序调整。
同时为了使得我们的实时计算能够得到充分的反馈,我们将排序内容进行混合,展现在同一个页面的商品,留有部分不受个性化的影响。这是为了避免因为个性化计算可能存在的偏差,造成错误学习的不断加强。增加不受个性化影响的商品展现可以通过比较用户对两部分商品的不同点击偏好来检验我们的算法正确性,并对可能的错误进行反馈和学习,自我纠正。
为评估效果,我们取了功能上线之后的一周数据统计结果。在访问UV保持不变的情况下,影响成交UV的是访问-成交即成交转化率,如果访问-成交比例保持不变,则访问UV受到CTR的影响。因此影响我们最终的交易金额的因素有CTR、成交转换率、以及客单价。我们希望提升ctr、成交转换率,同时客单价也得到提升。或者其中一项得到提升,而另一项基本保持不变。
我们统计一周的结果发现,我们的系统在整体的成交金额上有2%左右的提升,其中成交转换和转化率基本上保持不变,且随着时间的推移和系统的不断学习,出现缓慢的提升。而成交金额则带来了相对明显的提升。这是因为我们目前的个性化计算中,最主要的两个影响因素是性别和价格偏好。前者主要影响点击率、转化率,后者则主要以提高客单价为目标。根据我们的统计,在淘宝站内的搜索上,能受到性别影响的流量占比不到15%。这主要受到几个方面的影响:
1、有部分用户没有办法获知其性别,这个比例占20%以上。这主要是因为这部分用户的行为数据不够充分,属于新用户或者是活动非常不活跃用户。
2、有性别因素的query占比较少,大多数的query不存在性别差异,如“冰箱”、“糖果”等,或本身已经有明确的性别如 “衬衫男”,这写query占据绝大部分。需要性别进行影响的query只占总数的20%。
3、商品本身性别区分不明显,或者性别填写不准确。受这些影响,我们的ctr和成交转换率的变化并不明显。客单价提升较为明显的原因是价格因素的影响覆盖较广,因为价格是所有query、商品都受到影响的。
从目前来看,效果提升还比较有限,我们未来需要在以下两个方面进行优化:
1. 增加个性化信息的挖掘和应用。目前我们实时系统挖掘比较充分的是性别和价格,实时计算的其他属性偏好,类目偏好,店铺偏好的数据还需要进一步完善。
2. 优化排序逻辑,动态调整展现比例。目前的排序上人为地把商品分成了2个部分,且展现的比例无法动态调整,展现的商品之间存在比较明显的差异,这些都可能是造成用户体验不佳的因素。根据用户个性化信息的强弱动态决定个性化影响商品的比例,同时将两部分商品打散在一起进行混合排序,减少突兀感。
提示:本文发布于阿里技术嘉年华微信号{alibabatech},敬请关注。