HashMap解决hash冲突的方法
源码分析
HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置。当程序执行 map.put(String,Obect)方法 时,系统将调用String的 hashCode() 方法得到其 hashCode 值——每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。源码如下:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//判断当前确定的索引位置是否存在相同hashcode和相同key的元素,如果存在相同的hashcode和相同的key的元素,那么新值覆盖原来的旧值,并返回旧值。
//如果存在相同的hashcode,那么他们确定的索引位置就相同,这时判断他们的key是否相同,如果不相同,这时就是产生了hash冲突。
//Hash冲突后,那么HashMap的单个bucket里存储的不是一个 Entry,而是一个 Entry 链。
//系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),
//那系统必须循环到最后才能找到该元素。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}当系统决定存储 HashMap 中的 key-value 对时,完全没有考虑 Entry 中的 value,仅仅只是根据 key 来计算并决定每个 Entry 的存储位置。这也说明了前面的结论:我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可
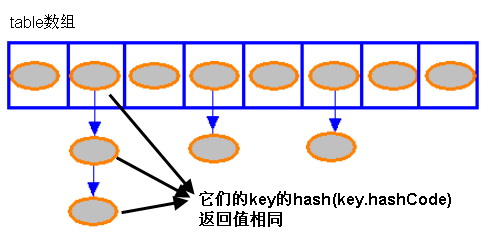
链表法
Hashmap里面的bucket出现了单链表的形式,散列表要解决的一个问题就是散列值的冲突问题,通常是两种方法:链表法和开放地址法。链表法就是将相同hash值的对象组织成一个链表放在hash值对应的槽位;开放地址法是通过一个探测算法,当某个槽位已经被占据的情况下继续查找下一个可以使用的槽位。java.util.HashMap采用的链表法的方式,链表是单向链表。形成单链表的核心代码如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}上面方法的代码很简单,但其中包含了一个设计:系统总是将新添加的 Entry 对象放入 table 数组的 bucketIndex 索引处——如果 bucketIndex 索引处已经有了一个 Entry 对象,那新添加的 Entry 对象指向原有的 Entry 对象(产生一个 Entry 链),如果 bucketIndex 索引处没有 Entry 对象,也就是上面程序代码的 e 变量是 null,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链。
HashMap里面没有出现hash冲突时,没有形成单链表时,hashmap查找元素很快,get()方法能够直接定位到元素,但是出现单链表后,单个bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
建议继续学习:
- 关于memcache分布式一致性hash (阅读:11328)
- 关于使用STL的红黑树map还是hashmap的问题 (阅读:8467)
- MinHash原理与应用 (阅读:6624)
- 无锁HashMap的原理与实现 (阅读:6215)
- LVS hash size解决4096个并发的问题 (阅读:5980)
- 如果用户在5分钟内重复上线,就给他发警告,问如何设计? (阅读:5553)
- Ubuntu 下Hash校验和不符问题的解决 (阅读:5161)
- 分布式系统hash策略 (阅读:4576)
- redis源代码分析 - hash table (阅读:4130)
- 一致性hash算法 (阅读:3838)
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:Eric 来源: JavaRanger - 专注JAVA高性能程序开发、JVM、Mysql优化、算法
- 标签: hash HashMap
- 发布时间:2014-12-30 12:29:21

-
 [882] WordPress插件开发 -- 在插件使用
[882] WordPress插件开发 -- 在插件使用 -
[136] 解决 nginx 反向代理网页首尾出现神秘字
-
[57] 整理了一份招PHP高级工程师的面试题
-
[55] 分享一个JQUERY颜色选择插件
-
[54] Innodb分表太多或者表分区太多,会导致内
-
[54] 用 Jquery 模拟 select
-
[54] 如何保证一个程序在单台服务器上只有唯一实例(
-
[52] jQuery性能优化指南
-
[52] CloudSMS:免费匿名的云短信
-
[52] 海量小文件存储
