逻辑回归算法学习与思考
本文是作者对于逻辑回归算法的学习和思考,主要介绍:逻辑回归的算法介绍、逻辑回归的数学原理、逻辑回归的实际应用、逻辑回归的总结以及网络安全场景预测,欢迎大家参考讨论。 、
逻辑回归的算法介绍
逻辑回归(Logistic regression)是机器学习分类算法的其中一种,核心思想是利用现有数据对分类边界建立回归方程,以此进行分类。回归可以理解为最佳拟合,是一种选择最优分类的算法。
逻辑归回中会有一些新词汇需要理解。
h函数: 根据输入的数据预测类别的函数,Andrew Ng的公开课中称为hypothesis function。
j函数: 我们需要一个机制去评估我们的h函数的好坏,j函数的作用是评估h函数的好坏,一般这个函数称为损失函数(loss function)或者错误函数(error function)。
逻辑回归的数学原理
h函数相关(预测函数)
首先,我们先看看逻辑回归的预测函数,h函数!
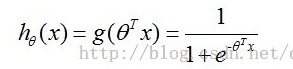
]1 lr_2
其中含有θ (又称:theta)的变量为(当x0=1时,可以进行矩阵变换):
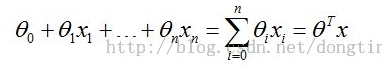
]2 lr_1
h函数的原型函数为sigmoid函数,展示如下:
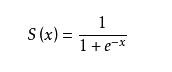
]3 sigmoid_function
sigmoid方程的图形如下,sigmoid函数的取值范围为 (0,1)
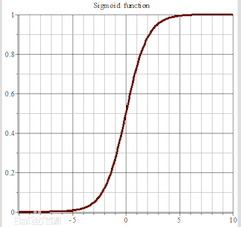
]4 sigmoid_pic
这里进行下小结,逻辑回归的预测函数使用sigmoid函数作为原型函数,然后对sigmoid函数的x进行替换,替换为一个多元一次方程。其中多元一次方程的θ为我要寻找最优组合的内容。
j函数相关
j函数的目标就是找到一组最佳θ,使得J(θ)的值最小。
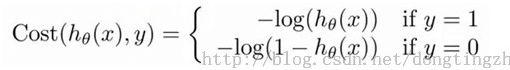
]5 lr_4
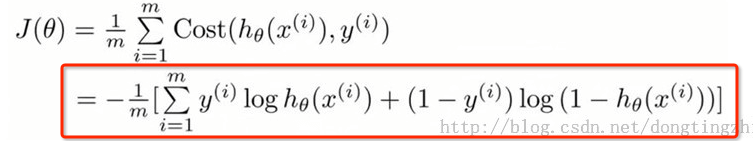
]6 lr_5
我们可以利用梯度下降算法来求得J(θ)的值最小,根据梯度下降法可得θ的更新过程。j=0 时,代表更新j向量的第0分量,j=1 时,代表更新j向量的第1分量,以此类推,为了方便理解,可以把j看成数组vector_j,j=0,就是更新vector_j[0]。α为学习步长。
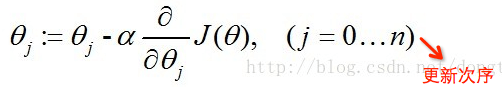
]7 lr_6
经过一些数学推导的最终形式如下(推导过程为对θ求偏导数)。
ps:xj为x向量的第j分量,还可以理解为x数组的第j项,其实下图是对θ数组的第j项进行更新的算式,然而真正代码角度是对整个θ数组进行更新,也就是下下图的样子。
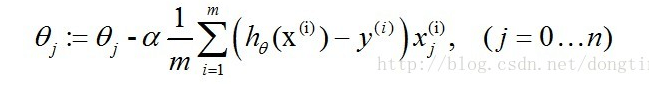
]8 lr_7
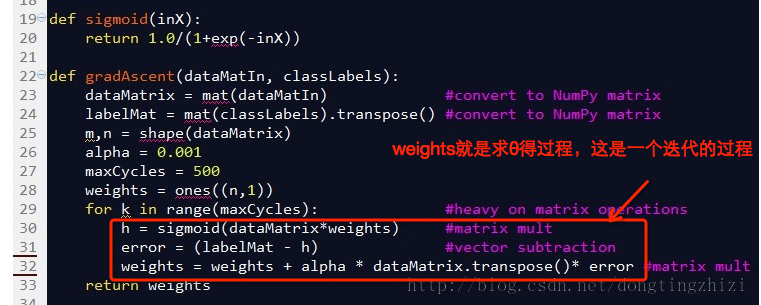
当我们把上式向量化处理就得到了代码可以处理的形式。
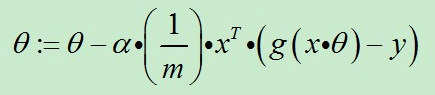
]9 lr_8
对比着代码看(代码出自《机器学习实战》)
]10 lr_9
这里进行下小结,我们为了寻找最佳的θ组合,设置了J(θ)函数,我们利用已知数据(建模的训练数据)来寻找最优的θ组合使得J(θ)最小,而我们找最优θ组合的算法为梯度下降算法。
逻辑回归的实际应用
目前单机使用机器学习算法的python库为sklearn库,实例如下。
使用该模型,需要手工调整函数的参数,这个需要对算法进行理解。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from sklearn import linear_model from sklearn.metrics import classification_report from sklearn.metrics import precision_recall_curve, roc_curve, auc
def main(): train_data = [] train_result = [] for i in open('train_data.txt').readlines(): ''' 29119 3.440948 0.078331 1 前三位为训练数据,最后一位为训练结果 ''' r = i[:-2].split('\t') train_data.append(r[:3]) train_result.append(r[-1])
clf = linear_model.LogisticRegression(max_iter=10000, C=1e5)
clf.fit(train_data, train_result)
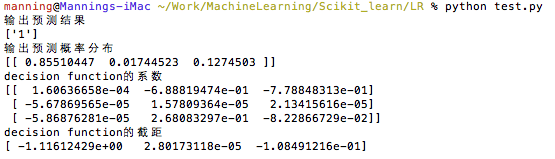
print '输出预测结果'
print clf.predict([[68846, 9, 0.6]])
print '输出预测概率分布'
print clf.predict_proba([[68846, 9, 0.6]])
print 'decision function的系数'
print clf.coef_
print 'decision function的截距'
print clf.intercept_
输出结果为
]11 lr_10
逻辑回归的总结
Logistic Regression算法作为一个二分类算法,主要解决的是线性可分的问题,对于多分类算法,可以利用Softmax Regression算法。
Softmax Regression是一般化的Logistic Regression,可以把Logistic Regression看成Softmax Regression的特例。
那么Softmax Regression和Logistic Regression该怎么选择呢?参考Stanford的文章的内容。
Softmax 回归 vs. k 个二元分类器
如果你在开发一个音乐分类的应用,需要对k种类型的音乐进行识别,那么是选择使用 softmax 分类器呢,还是使用 logistic 回归算法建立 k 个独立的二元分类器呢?
这一选择取决于你的类别之间是否互斥,例如,如果你有四个类别的音乐,分别为:古典音乐、乡村音乐、摇滚乐和爵士乐,那么你可以假设每个训练样本只会被打上一个标签(即:一首歌只能属于这四种音乐类型的其中一种),此时你应该使用类别数 k = 4 的softmax回归。(如果在你的数据集中,有的歌曲不属于以上四类的其中任何一类,那么你可以添加一个“其他类”,并将类别数 k 设为5。)
如果你的四个类别如下:人声音乐、舞曲、影视原声、流行歌曲,那么这些类别之间并不是互斥的。例如:一首歌曲可以来源于影视原声,同时也包含人声 。这种情况下,使用4个二分类的 logistic 回归分类器更为合适。这样,对于每个新的音乐作品 ,我们的算法可以分别判断它是否属于各个类别。
现在我们来看一个计算视觉领域的例子,你的任务是将图像分到三个不同类别中。(i) 假设这三个类别分别是:室内场景、户外城区场景、户外荒野场景。你会使用sofmax回归还是 3个logistic 回归分类器呢? (ii) 现在假设这三个类别分别是室内场景、黑白图片、包含人物的图片,你又会选择 softmax 回归还是多个 logistic 回归分类器呢?
在第一个例子中,三个类别是互斥的,因此更适于选择softmax回归分类器 。而在第二个例子中,建立三个独立的 logistic回归分类器更加合适。
网络安全场景不负责预测
逻辑回归算法作为一个二分类机器学习算法,主要优势是学习速度快,算法好理解,预测速度快等特点,并且神经网络在神经元上也是采用的是逻辑回归算法,因此在这个深度学习的大背景下,安全人员还是要学习逻辑回归算法。
对于在安全攻防上使用逻辑回归算法,我们先要明白逻辑回归算法的本质:逻辑回归是分类算法。
吸星是安全在机器学习实践上一个非常好的例子,由于吸星使用的是朴素贝叶斯分类算法,那么吸星能不能使用逻辑回顾呢?效果如何呢?这是值得实践的。
异常流量识别,由于瞬时流量或者流量区间中会存在非常多的属性,而且异常流量识别属于二分类,逻辑回归对于异常流量监测问题,这也是非常值得实践的。
网站异常URL识别,对于一个网站,URL的形式具有一定特征的,那么如果被种植了webshell,那么webshell的URL可能会与正常URL存在差异,因此利用此逻辑回归也是能解决这类问题的。
其实总结起来就是,只要每一条数据可以有多个属性,就可以利用逻辑回归。
参考内容:
http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
http://blog.csdn.net/dongtingzhizi/article/details/15962797
扫一扫订阅我的微信号:IT技术博客大学习
- 作者:Manning 来源: 绿盟科技博客
- 标签: 回归
- 发布时间:2016-06-06 23:30:03
-
 [928] WordPress插件开发 -- 在插件使用
[928] WordPress插件开发 -- 在插件使用 -
[134] 解决 nginx 反向代理网页首尾出现神秘字
-
[52] 整理了一份招PHP高级工程师的面试题
-
[52] 如何保证一个程序在单台服务器上只有唯一实例(
-
[51] 用 Jquery 模拟 select
-
[50] 海量小文件存储
-
[50] Innodb分表太多或者表分区太多,会导致内
-
[50] 全站换域名时利用nginx和javascri
-
[49] CloudSMS:免费匿名的云短信
-
[47] jQuery性能优化指南
