Ubuntu工作机使用FlashCache技术加速
作者从Facebook开源的FlashCache项目切入,介绍如何利用一块闲置SSD为Ubuntu等Linux系统的机械硬盘分区提供缓存加速。文章核心解决的是传统磁盘性能不足的问题,方案是在机械硬盘前放置SSD作为写回缓存:数据先高速写入SSD,再由后台异步同步至机械硬盘,从而在保证数据最终落盘安全的前提下,显著提升大容量存储的读写体验。 具体步骤上,文章详细演示了从获取源码、编译安装模块,到使用`flashcache_create`命令初始化缓存设备、设置开机自动挂载的完整流程。作者以加速`/home`分区为例,提供了清晰的命令行操作指南,并提醒了数据迁移时需注意的权限问题。 文章最后指出了该方案的权衡点:SSD空间将完全用于缓存而非存储文件,因此只适合拥有空余SSD容量的用户。整体而言,这为拥有多硬盘或闲置SSD的用户,提供了一个低成本、高可靠性的系统加速思路。
缓存为王
这篇讲的是Web性能优化中一个常被低估的选手:缓存。作者从“快速Web应用的关键是Ajax、优化JavaScript和更好的缓存”这一观点出发,做了一项有趣的实测,想看看这三招在实际网站里到底谁最管用。 他用WebPagetest工具模拟不同网络环境,对Alexa前1000网站进行了对比测试。结果有点出乎意料:缓存模式表现最强,页面加载中位数只需3.46秒,远快于“快速网络”(4.13秒)和“禁用JavaScript”(4.74秒)。核心原因在于,缓存直接将90个HTTP请求削减到仅32个,大部分资源从本地读取,彻底避免了网络传输。 文章进一步分析,当前很多网站虽配置了缓存,但有效期很短,导致优势局限于“重复浏览”。作者由此提出,未来的方向是延长缓存时间,并探索预读技术,让性能优势更持久。这提醒我们,在追求新技术的同时,扎实做好缓存这一“基本功”,往往能带来最显著的收益。
概率语言模型及其变形系列-LDA及Gibbs Sampling
这篇讲的是概率语言模型系列的第二篇,聚焦于LDA(Latent Dirichlet Allocation)及其参数推断方法Gibbs Sampling。文章从LDA的核心思想切入:如何通过无监督学习,从文本中发现隐含的“主题”结构,从而解决“一词多义”和“一义多词”的语义匹配问题,让搜索结果在语义层面真正相关。 理解LDA的关键在于其概率基础。文章深入剖析了“随机生成过程”视角,解释了文本如何被看作词项的样本集合。重点阐述了多项分布(Multinomial)与其共轭先验狄利克雷分布(Dirichlet)的特性与计算优势——后者被称为“分布之上的分布”,其样本恰好是多项分布的参数。这些数学工具共同构成了LDA模型的基石。 作为PLSA到变形LDA之间的承上启下之作,文章不仅厘清了基础概念,也为后续探讨Twitter LDA、Labeled-LDA等各类变形模型铺平了道路。对于想从理论层面掌握主题模型的读者,这篇系统性的推导提供了扎实的起点。
概率语言模型及其变形系列-PLSA及EM算法
这篇从LSA(隐性语义分析)的SVD方法入手,分析了其处理一词多义和一义多词问题时的不足——通过低秩逼近虽然能降维去噪,但缺乏严谨的统计基础且计算耗时。由此自然引入Hofmann提出的PLSA模型。 PLSA采用概率图模型重新表述文档生成过程:先以一定概率选中文档,再从中抽取主题,最后根据主题生成单词。文档和主题都被建模为多项分布,而EM算法则负责估计这些隐含参数。文章不仅推导了PLSA的数学框架,还通过简单的混合Unigram模型与高斯混合模型(GMM)类比,帮助理解EM算法“期望步-最大化步”的迭代精髓。 整个系列其实计划覆盖从PLSA、LDA到各类变形模型(如Twitter LDA、Labeled-LDA等)的演进脉络,这篇作为开篇,扎实地奠定了概率主题模型的基础认知。
php缓存与加速分析与汇总
这篇讲的是PHP网站缓存加速的实战指南,作者基于Win7+Apache+PHP的测试环境,从浏览器端缓存机制入手,深入剖析了HTTP头域中Expires、Last-Modified与Etag的工作原理与差异。文章通过浏览器监听的实际截图,清晰展示了首次请求、未过期缓存命中以及304状态码等不同场景下的网络交互细节。 作者对比了Apache处理静态文件与动态文件的默认行为差异,并详细演示了通过PHP代码设置 Expires 头域来实现时间缓存的具体方法。更有趣的是,文章还探讨了在PHP中同时设置Expires与启动Session时出现的一个特殊缓存现象,揭示了看似简单的缓存设置背后可能隐藏的复杂交互。整体内容基于作者的亲自动手验证,将理论与实际监听结果相结合,对理解前端性能优化中的浏览器缓存策略有不错的参考价值。
YSLOW法则中,为什么yahoo推荐用GET代替POST?
你一定听过“POST请求会被拆分成两个TCP包发送”这个经典结论,它常被用来解释为什么Yahoo的YSLOW优化法则推荐在AJAX中使用GET。但作者没有止步于此,他决定亲手验证一下这个看似权威的说法。 通过Wireshark抓包分析,作者确实观察到,在IE8等浏览器中,一个POST请求的HTTP头部和正文数据会被分开发送,形成两个独立的数据包。这初步印证了Yahoo的优化建议。 然而,实验出现了转折。当作者测试Firefox 5浏览器时,发现POST请求的头部和数据被合并到了一个TCP包中发送,与IE8的行为截然不同。这意味着,那个“POST必被拆分”的结论并非普适真理,其实际表现高度依赖于浏览器的具体实现。 这篇文章的价值在于,它带领读者完成了一次从盲从规范到动手验证的技术探索。作者的实测表明,即使是像“GET优于POST”这样被广泛接受的前端优化法则,其底层原理也可能因环境而异。这提醒我们,在技术选型时,不能只看结论,了解其在不同场景下的实际表现或许更重要。
阿里巴巴国际站P4P引擎系统简介
这篇讲的是阿里巴巴国际站P4P(外贸直通车)广告引擎的整体技术架构。文章的出发点是如何为国际站卖家提供精准的付费推广服务,核心在于构建一个高效、可扩展的广告在线查询与结算系统。 作者详细拆解了这个系统背后的多个协同模块。业务平台负责卖家开户与管理;核心的iMatch引擎则基于分布式搜索架构,通过离线全量构建索引(利用Hadoop/HBase降低数据库压力)与实时增量更新相结合的方式,保证广告信息的及时性与查询性能。算法模块为引擎提供匹配、质量预估等模型支持。在线查询系统则由Blender、Merger、Searcher等组件协作完成请求处理、结果聚合与排序。 文章还深入到了点击过滤与结算的闭环:系统实时拦截并分析点击流量,通过规则与模型进行反作弊校正,并将结算数据反馈给业务平台。整个架构设计考虑了全量与增量数据的同步补偿、在线服务的可扩展性,为国际站广告业务的稳定运行和后续演化提供了扎实的技术基座。

一个登陆认证系统
从代理项目《狂刃》的登录认证需求出发,作者描述了一个在时间压力下临时设计的简化认证协议。该协议基于HTTP,旨在为非Web应用在不安全信道上建立认证流程。核心设计包含游戏服务器(G)、认证平台(E)和客户端(C)三方交互:G生成一次性盐值(salt),C用用户密码对盐值进行加密签名后发送给E验证;E验证通过后,用相同算法生成发给G的认证令牌,最终由C转发给G完成双向确认。这种设计让G和E无需保持通信,只需预共享密码,降低了服务器状态管理的复杂度。 文章的重点落在实际部署中的一次“拍脑袋”引发的事故。合作方在未通知的情况下,使用作者用Lua快速编写的调试用认证服务器,对600人进行了压力测试。初期认证大面积失败,排查发现根因在于服务器的网络配置:该服务器配有电信和网通双线IP,而作者最初将服务绑定地址(bind address)默认设为127.0.0.1,合作方在部署时仅将其改为了服务器的其中一个IP,导致部分客户端无法连接。最终将绑定地址改为0.0.0.0才解决了问题。这个意外插曲揭示了一个常见陷阱:内部开发用的快速工具一旦被外部环境直接使用,其默认配置或简化实现可能成为隐形炸弹,即使核心逻辑(如作者后续补上的并发处理)经受住了压力,但外围配置的疏漏同样会导致生产事故。
两个精彩的比喻:吞吐量和延迟、信号量和互斥锁
这篇文章通过两个极其形象的比喻,澄清了计算机领域两对容易混淆的概念:吞吐量与延迟、信号量与互斥锁。 对于吞吐量和延迟,作者用ATM取钱打比方。一个人完成取款的时间是延迟,而整个银行每分钟能服务的人数是吞吐量。比喻生动地说明,增加ATM机数量(提高并行度)可以在延迟不变的情况下大幅提升吞吐量;而取钱后填写问卷(增加串行步骤)则会显著增加延迟,但吞吐量可能保持不变。这清晰地揭示了两者的核心区别:延迟衡量单个任务的体验,吞吐量衡量系统的整体产能。 关于信号量和互斥锁,作者改进了常见的“钥匙”比喻。互斥锁是独占的钥匙,拿到的人拥有唯一打开权。信号量则是一个大公共厕所门口的“可用/已满”指示牌,它代表的是可并发进入的资源数。文章特别指出了原比喻的不足,并用改进后的“牌子”比喻说清了关键差异:二元信号量的牌子(状态标志)可以被任何人翻动,而互斥锁的钥匙只能由拥有者打开。这个细微差别,正对应了状态协作与资源独占的不同使用场景。
PHP业务逻辑层和数据访问层设计
这篇讲的是PHP项目中如何合理设计业务逻辑层与数据访问层。作者从面向对象的基本原则出发,探讨了在MVC架构下,模型(Model)层究竟该承担什么职责。 文章指出,项目规模和复杂度决定了分层的必要性。对于业务简单、数据库固定的小项目,采用表模块或活动记录模式将业务逻辑与数据访问合并,反而更高效。但随着需求膨胀,就需要清晰划分:业务逻辑层应基于“领域模型”来实现,专注于对象属性与行为的描述;数据访问层则为业务层提供数据支持。 在数据访问层的具体模式选择上,作者对比了表数据入口、行数据入口、活动记录和数据映射器等经典方案。考虑到PHP语言特性(如灵活的数组操作、开发者对SQL的偏好)以及多数项目数据库变动少的现实,作者认为“表数据入口”模式是更务实的选择。最终结论是,理想的PHP应用架构是:用领域模型构建业务逻辑,通过表数据入口模式实现数据访问层,让开发能更专注于领域行为本身。
个性化离线实时分析系统pora
这篇讲的是淘宝搜索背后的个性化实时分析系统pora。文章从实际业务痛点出发:为了实现“千人千面”的搜索结果,原先依赖隔天跑批的用户属性计算存在延迟,无法捕捉用户当下的兴趣变化。核心方案是构建一个实时系统,通过Storm处理来自TimeTunnel的实时日志流,并与HBase中的离线全量计算结果合并,最终快速更新用户标签到在线存储中。 作者详细拆解了系统架构与拓扑设计。其亮点在于采用了“框架+插件”的分析模式,让算法逻辑可以灵活插拔;同时,在Joiner和Analyzer环节设计了可配置的微批处理,巧妙地在延迟和HBase的访问性能之间做了平衡。系统最终每天稳定处理几十亿条日志,将用户行为从产生到属性更新的延迟控制在了秒级。 文章末尾分享的经验教训尤为实在,比如为HBase表做预分区、Storm中emit tuple时避免修改list对象等,这些都是经过线上锤炼的宝贵实践。
进程运行于不同的 CPU 核
这篇文章讲的是,如何在多核服务器上,让关键进程更高效地利用 CPU 资源。作者从用 Gearman 搭建 Map/Reduce 的实战场景出发,发现启动多个 daemon 进程后,需要确保它们能够分散运行在不同 CPU 核心上,以避免资源争抢、提升整体性能。 文章的核心方案是利用“CPU 亲和性”,将进程绑定到指定的 CPU 核心。作者不仅展示了如何使用 `taskset` 命令,将已运行的进程或通过脚本启动的进程分配到 CPU#0、#1、#2 上,还特别指出了 Nginx 的配置方式——它支持在 `nginx.conf` 中通过 `worker_cpu_affinity` 为每个工作进程精确绑定 CPU 核心,这是一种更优雅的管理方法。 从基本的 `taskset` 命令操作,到深入探讨 `sched_setaffinity` 系统调用和进程继承机制,文章给出了从“知道怎么做”到“理解为什么”的完整路径。对于追求高并发性能的后端开发者而言,这种对服务器硬件资源进行细粒度控制的能力,是优化服务稳定性和吞吐量的实用技巧。

基于Redis构建系统的经验和教训
这篇文章从实际应用出发,讨论了Redis的优势与局限,并对比了其他海量数据存储方案。作者指出,Redis的有序集合(zset)等丰富数据结构使其在表达业务逻辑时极为高效,特别适合对性能要求高、数据规模可控的场景,比如消息传递系统的收发件箱。 然而,Redis“所有数据必须存放在内存中”的核心设计,直接导致了容量瓶颈和高昂的硬件成本。作者通过计算说明,对于一个百万级用户系统,数据量轻松超过单机内存极限。由此还引发了一系列问题:持久化时fork进程占用双倍内存,Aof日志写盘可能阻塞系统,以及不成熟的主从复制可能因网络抖动产生全量同步,严重消耗带宽。单机架构也迫使开发者在业务逻辑之外,必须额外设计复杂的数据分片方案。 面对海量数据,文章对比了Cassandra、HBase和MongoDB等方案。作者认为纯键值存储(如Cassandra)对结构化数据的表达能力太弱;而像HBase这类系统,其数据模型提供了更有序的组织方式。文章最终提出的观点是:理想的存储方案应当提供基础的有序数据结构,允许开发者通过“实体”加“有序子集”的方式来自然映射业务逻辑,从而在海量数据规模下,实现高效的数据访问与传输。 因此,Redis应定位在小而美的高性能缓存或结构化存储层,而非追求海量数据的存储目标。
稳定性思考-强弱依赖2
这篇文章从一个实际问题切入:在微服务架构中,如何为弱依赖(如Cache)设置合理的“并发请求数阈值”?作者的分析思路很清晰,核心目标是实现高QPS下的资源消耗最小化,即“高QPS,少线程”。 作者通过一个Cache访问案例,结合公式 QPS=1000/RT * threadNum,做了生动的故障推演。正常时1个线程就能支撑400QPS;一旦Cache故障、RT飙升至3000ms,理论上就需要1200个线程,这会导致调用方线程池耗尽、频繁FullGC,陷入恶性循环。 为此,文章提出的核心方案是:限制访问弱依赖的线程数。例如,将阈值设为10。这样在上述故障中,调用方只会阻塞10个线程,整体服务保持正常,实现优雅降级。结合超时设置,能形成更有效的流控策略。 那么阈值设多少?文章给出了计算方法:根据可接受的RT(如100ms)和目标QPS(400)反推,得到 threadNum = 400 * 100 / 1000 = 40。作者也分享了经验数据:平均50ms的APP,阈值一般不超过60。文章最后点明,响应时间变长往往源于排队,而系统的最高QPS由瓶颈资源决定,盲目增加线程未必有用。
稳定性思考-强弱依赖
这篇讲的是系统稳定性中一个核心却容易被忽视的点:如何正确处理系统间的依赖关系。作者从淘宝复杂的系统依赖场景出发,将依赖清晰地划分为“强依赖”与“弱依赖”,并剖析了二者对系统稳定性的迥异影响。 对于强依赖,文章指出其风险在于“一荣俱荣,一损俱损”。除了主张通过扩展通道来解耦,作者更通过一个生动的分流压测案例揭示了关键发现:一个单机容量为4的系统,在被过载压垮后,其容量会急剧下降至约2.5,且自身难以快速恢复。这源于资源耗尽导致的线程堆积与频繁Full GC,深刻说明了对下游依赖系统进行“流量保护”的必要性。 文章接着探讨了更优的“弱依赖”模式。它细分为两种场景:一是主流程无需等待结果的异步化调用;二是需要等待结果但通过设置超时与最大并发阀值来熔断保护。这两种方式都能在B系统故障时,确保核心链路A的稳定运行。 整体而言,作者用从理论到压测实证,再到具体技术方案的递进逻辑,为如何设计高可用系统提供了极具操作性的指导。
国内外旅游电子商务个性化推荐系统研究
这篇讲的是如何让旅游网站更懂你。当前多数旅游电商网站内容同质化严重、服务千篇一律,导致游客选择困难、预订转化率低。文章从这一痛点切入,以国内外发展现状为背景,深入探讨了个性化推荐系统在旅游电商中的应用。 作者首先梳理了国内(如携程、艺龙)与国外个性化服务从学术研究走向产业应用的历程。核心在于分析影响旅游消费者决策的经济与非经济因素——从收入、价格到动机、个性特征等,这些因素共同构成了个性化推荐的依据。文章重点对比了传统旅游电商与个性化推荐系统的区别:前者以交易效率为核心,后者则以提供个性化服务为前提,通过双向沟通和精细市场细分来设计产品。 研究最终落脚于个性化推荐系统的主要功能与体系结构分析,并进行了模拟应用。其目标是帮助游客高效决策,获得更好的旅游体验,从而提升网站竞争力与用户忠诚度。
设计模式原则总结
这篇文章系统梳理了面向对象设计中的七大核心原则,从单一职责到迪米特法则,为开发者提供了一份清晰的“设计心法”参考。作者没有停留在概念罗列,而是用通俗的语言点明了每个原则的实质:比如“开放-封闭”原则强调对扩展开放、对修改关闭,是应对需求变化的基石;里氏代换原则则为继承体系划定了行为边界,确保子类能无感替换父类;而依赖倒置原则提倡面向接口编程,正是解耦高层与底层模块的关键。 文章特别区分了合成/聚合复用原则中“聚合”(弱拥有关系)与“合成”(强拥有、生命周期一致)的微妙差异,这对选择正确的复用方式至关重要。所有解释都紧扣实际编码场景,如接口隔离原则直指“避免接口臃肿”和“最小化依赖”的痛点。文末注明内容源自经典书籍《大话设计模式》,为总结的权威性提供了背书。掌握这些原则,能帮助我们更清醒地判断代码结构,写出更健壮、可维护的系统。
网站统计中的数据收集原理及实现
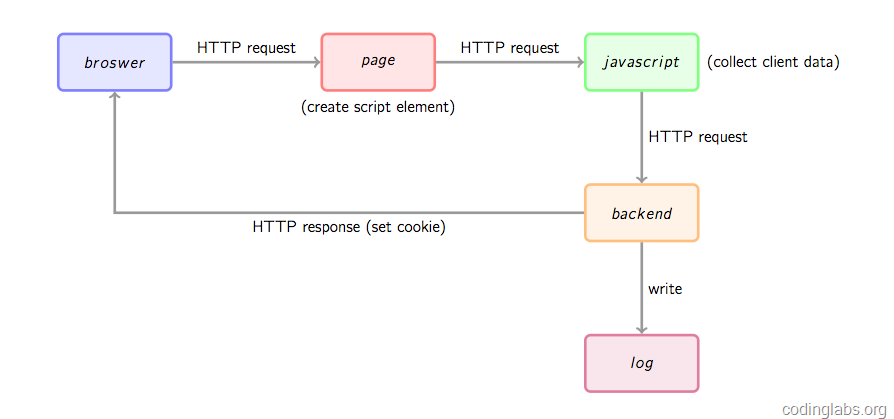
这篇技术解析从我们日常使用的谷歌分析、百度统计等工具切入,深入剖析了其背后数据收集的核心机制。作者指出现代统计的关键突破在于利用JavaScript进行可定制的埋点,从而能捕获从页面浏览到按钮点击、电商下单等丰富用户行为。 文章重点拆解了数据收集的“三步走”流程:首先,网站植入的埋点脚本会动态加载主收集脚本;其次,这个主脚本通过浏览器对象和自定义配置收集页面信息与事件数据,并巧妙创建一个指向后端地址的Image对象来实现跨域传输;最后,服务器端的收集脚本(常伪装成一个1x1的透明GIF)解析请求参数,结合服务器信息与Cookie技术来记录日志并追踪唯一访客。 最有价值的部分是,作者并未止步于理论分析,而是基于上述原理,动手实现了一个名为MyAnalytics的简易收集系统,详细展示了从确定收集字段(如URL、分辨率、Referrer)到设计服务端的全过程。这种从原理到实践的完整拆解,清晰揭示了网站统计工具“看透”用户行为的技术底色。
TF-IDF模型的概率解释
这篇讲的是如何从概率的角度,重新理解一个搜索引擎的核心算法——TF-IDF模型。作者敏锐地指出,传统信息检索中“匹配度”的定义相当模糊,更严谨的目标应该是计算“给定查询串q时,用户期望获得文档d的概率”。 为了推导这个概率,文章构建了一个巧妙的“盒子小球模型”:将文档比作装有彩色小球(词语)的盒子,整个问题就转化为经典的贝叶斯条件概率问题P(d|w)。作者逐层拆解这个公式:P(d)是文档的先验概率,这恰好对应了Google PageRank的思路,解释了为何它常与TF-IDF相乘;P(w)是关键词本身的搜索先验概率;而条件概率P(w|d)则被解释为“词w代表文档d主题的概率”。 文章的亮点在于对P(w|d)的推导。作者引入了信息论,指出idf公式中的log(n/docs(w,D))本质上就是词w的“信息量”——它对降低文档集合不确定性的贡献大小。通过这一关键连接,TF-IDF的乘积形式被自然地纳入概率框架。同时,模型也指出了当前简单搜索引擎可能忽略了文档的总词信息量(分母部分)和关键词的全局搜索频率P(w)。 最后,文章尝试将模型扩展到多关键词场景,并探讨了关键词独立性假设的局限。整体而言,作者并未止步于解释TF-IDF,而是用概率视角重构了整个排序问题的根基,并指出了更精确的优化方向。
星际争霸2编辑器的初接触
这篇讲的是团队如何用星际争霸2的编辑器来解决怪物AI配置的老问题。传统做法是策划写需求文档,再交给程序去改代码,流程长还容易出错。作者接手这个模块后,发现编辑器自带的触发器系统其实是个现成的解决方案——它支持用“如果-那么”的逻辑来定义行为,并且所有参数都能在界面里直接修改。 通过搭建一套基于触发器的AI框架,策划可以直接在编辑器里调整怪物的巡逻路线、攻击逻辑和技能释放条件,改完就能实时看到效果,不用再走提需求、等排期、测版本的漫长循环。这相当于把原本硬编码在程序里的行为“翻译”成了策划能看懂、能操作的数据配置。 这种做法的核心是把编辑器从单纯的关卡工具,变成了支持数据驱动的AI开发平台。虽然最初只是为了解决沟通效率问题,但最终让团队获得了快速迭代AI设计的能力——策划可以当场尝试不同的行为组合,测试反馈的周期从几天缩短到了几分钟。对于同样受困于工具链割裂的团队来说,这种“用现有工具挖掘隐藏功能”的思路,或许比从头自研一套编辑器更有实操参考价值。