bash shell - sed, awk文本捕获及替换
这篇文章探讨了在 bash shell 中处理复杂文本捕获与替换任务时,sed 与 awk 的实际能力差异。作者从一个具体需求出发:如何在一段包含多个 `background-image: url(...)` 的 CSS 字符串中,为每个图片路径(如 `a.jpg` 和 `b.jpg`)统一追加一段签名串。 虽然 bash 本身支持正则表达式,但作者指出,标准工具 `sed` 在应对这种“单次操作中匹配并处理多个目标”的场景时显得力不从心。他通过代码示例表明,用 sed 编写一句命令来同时捕获多个图并替换,实现起来相当困难。这引出了对更强大工具的需求。 文章的核心对比点在于 `awk` 的灵活性。作者展示了如何利用 awk 的字段分割和模式匹配能力,更优雅地遍历和处理这类包含重复模式的数据。与 sed 的行处理流不同,awk 能够将整个字符串视为可灵活操作的输入,从而轻松实现“捕获一个,处理一个”的逻辑,完美满足需求。 最终,作者提供了一个基于 awk 的完整脚本作为解决方案。这篇文章的价值在于,它并非泛泛地介绍工具,而是通过一个真实的字符串处理困境,具体地对比了 sed 和 awk 的适用边界,为遇到类似文本“捕获-替换”问题的开发者提供了清晰的技术选型参考。
服务器间同步/镜像/备份配置备忘录
这篇讲的是作者从VPS转向独立服务器后,面对备份策略完全自主的新挑战时,如何梳理和记录自己的一系列配置实践。文章的核心出发点很实际:经济型VPS虽然简陋,但服务商通常会提供基础的RAID1+0硬盘冗余,硬件故障尚有一线希望;而独立服务器出于成本考虑可能没有RAID保护,一旦疏于备份,数据风险便完全由自己承担。 作者并没有展开一个宏大的备份架构,而是像一份贴心的备忘录,记录了自己在“服务器间同步、镜像与备份”这个具体任务中,反复搜索、尝试并最终固定下来的一系列配置方案。这些内容包括具体的工具选择、配置命令和注意事项,旨在为自己省去日后重复折腾的麻烦。对于同样从托管服务转向自管理服务器的技术人员,尤其是那些预算有限、需要亲自上手维护数据安全的读者来说,这些凝聚了踩坑经验的配置笔记,提供了一份可以直接参考或借鉴的实战清单,避免了从零开始的盲目摸索。
一年米国VPS使用经验总结
这篇总结是作者在使用了多家美国VPS服务商后,对自己过去一年体验的全面梳理。文章没有停留在单一产品的测评,而是横向对比了不同服务商在配置、网络线路、稳定性及性价比上的实际表现。 从内容看,作者从建站、开发到日常使用的多个维度,记录了各款VPS的“脾气”与长板。比如哪家的线路对国内访问更友好,哪款在突发流量下更抗压,以及在不同预算下如何做出权衡。这些基于长期、多场景使用得出的经验,构成了文章的核心干货。 对于正在挑选或刚刚接触海外VPS的读者,这份汇总相当于一份“避坑”与“优选”参考。它跳开了营销宣传的套路,直接呈现了真实运维中的细微差别——哪些标称的“高性能”是实打实的,哪些低价套餐则存在隐性门槛。这种基于实践的横向对比,能帮助读者更快地锁定与自己需求匹配的选项。
利用tcpcopy引流做模拟在线测试
这篇文章讲的是如何利用开源工具 tcpcopy,在生产环境进行真实的流量回放和模拟在线测试。 作者从实际线上压测的痛点出发:很多线上问题难以在预发环境复现,而直接用压测工具生成流量又不够“真实”。文章详细介绍了 tcpcopy 的工作原理——它能将线上生产流量“复制”并“引流”到目标测试服务器,从而构造一个与线上几乎一致的流量环境。文中不仅涵盖了基础的安装与配置步骤,还分享了一些实战经验,比如如何处理 NAT 网络环境、如何结合 MySQL 进行数据库变更的影响模拟。 通过这种方式,团队可以在不直接影响线上服务的前提下,用真实的用户请求来验证新功能、性能瓶颈或故障预案的有效性。文章最终展示了一个完整的测试案例,证明了该方案在提前发现潜在问题、保障系统稳定性方面的实用价值,为线上稳定性测试提供了一种低成本且高保真的思路。
怎么样让 LVS 和 realserver 工作在同一台机器上
这篇讲的是在资源有限的场景下,如何将 LVS 负载均衡(DR模式)与它背后的 realserver 服务(如数据库)部署在同一台物理机上,以节省硬件成本。作者在两台服务器构成的集群里,尝试通过 keepalived 实现 LVS 主从高可用,并希望负载和业务服务共存。 但配置完成后,服务无法正常工作。核心矛盾在于,VIP(虚拟IP)同时配置在作为 LVS 和 realserver 的本机网卡上,导致了本地数据流在内核网络栈中的异常路由和重复发送。文中提供的架构图清晰地展示了这个问题:请求包(CIP->VIP)在本机被 LVS 处理后,又作为“外来”数据包被本机的 realserver 服务重复接收了一次,形成了环路。 这篇文章并未直接给出最终的解决方案,而是像一篇“踩坑日志”,详细列出了问题现象、尝试的架构以及配置输出,将 LVS-DR 模式下的一个典型部署陷阱——“同机部署时的数据包回流与自环”——摆在了台面上。它邀请读者一起思考:在这种极致节省的架构下,到底该如何调整内核参数、网络配置或 LVS 规则,才能打破这个循环,让调度器和后端服务在同一台机器上和谐共存。这种对具体、细微问题的深入排查,对面临类似成本与架构权衡的运维和开发人员,有着直接的参考价值。
xxx.xxx.0.0/16 和 xxx.xxx.0.0/24的区别
这篇讲的是IP地址中两种常见子网掩码表示法——/16和/24——的核心差异。作者从实际应用场景出发,解释了/24代表C类地址(主机位占8位),网络号部分“xxx.xxx.0”固定,仅最后8位可变,通常用于局域网内小型网络划分;而/16则意味着网络前缀更短(仅16位),主机位长达16位,能容纳远超6万台设备(2^16-2),更适合大型企业网络或需要统一管理大量设备的场景。 关键差异在于可用主机数量和管理粒度:/24每个子网支持约254台主机,适合部门或项目隔离;/16则提供约65,000个主机地址,但广播域也更大,需配合更精细的VLAN或路由设计来控制广播风暴。文章虽短,却点出了选型时需权衡的核心——是要隔离性,还是要地址空间的扩展性。
xen虚拟机的迁移类型
这篇讲的是Xen虚拟机管理中一个关键但容易被忽略的环节——在线迁移。作者从保证业务连续性的高可用需求出发,具体拆解了两种核心迁移思路。 一种是“冷静态迁移”,它需要先完整保存Guest域的运行状态(通过xm save命令生成检查点文件),然后将配置文件、镜像连同检查点文件一并拷贝到目标服务器,再通过xm restore恢复运行。这本质上是一个“关机-转移-重启”的过程,虽然会导致服务中断,但状态保存完整。 更值得了解的是“温静态迁移”。它的精妙之处在于“暂停而非关机”——原宿主机先临时挂起(suspend)Guest域,随后将其内存状态和进程直接在目标宿主机上恢复(resume)运行。这种方式最大程度地减少了服务中断时间,是实现动态迁移的常见基础技术路径。 文章直接切入操作命令与步骤对比,清晰呈现了从完全停机到近乎不中断的两种技术权衡。对于需要规划虚拟机资源池维护或构建容灾体系的工程师来说,这两种迁移模式的适用场景和操作细节,正是实现高可用的实操基石。
Nginx使用Linux内存加速静态文件访问
这篇讲的是一个针对 Nginx 的性能压榨方案:当默认的磁盘 IO 在高并发下成为瓶颈时,如何进一步突破它。 作者从 Nginx 作为静态资源服务器的出色表现切入,但指出在极端压力下,磁盘的随机读写仍是短板。核心方案是利用 Linux 内核的 mmap 系统调用,将静态文件直接映射到内存中。这样,后续的请求就可以绕过文件系统,从内存直接提供文件数据,从而减少内核空间与用户空间之间的切换以及磁盘 IO 开销。 这个优化并非 Nginx 原生支持,需要通过第三方模块或自定义配置来实现。文章的关键在于点明了这种“内存优先”策略的适用场景:当你的静态文件访问量极大、且 IO 等待已成为主要延迟来源时,将热文件驻留内存能带来立竿见影的效果。这本质上是一种用内存空间换取响应速度和吞吐量的经典权衡。
三国演义的历史人物中 谁适合当产品经理
这篇讲的是一个技术人从组织“华东运维技术大会”中悟出的产品经理思维。作者从自己与潜在赞助商的谈判经历出发,发现了一个核心矛盾:作为技术人员,他秉持“互惠互利”的简单合作观,而市场销售方则天然追求“以最小代价获取最大收益”。即使对于仅2万元、相比对方上亿营收微不足道的赞助,对方仍希望额外置换一个广告性质的主题分享,这触犯了大会的技术纯粹性原则,合作最终告吹。 文章将这一具体冲突引申到经典IP“三国演义”中的人物身上,进行了一场有趣的思维实验。它并非在分析历史,而是借这些人物的性格与行事风格,来映射和探讨“产品经理”这一角色所需具备的特质。作者通过自身的挫败感,点出了技术人员转型做产品或项目管理时,容易忽视的商业博弈与资源谈判维度。对于不少埋头于技术的读者而言,这不仅是一次共鸣,更提供了从技术思维向产品思维切换的鲜活视角。
一个检查偶发连接失败的脚本
这篇讲的是一个针对偶发性连接失败的实用排查方案。在网络服务或分布式系统中,偶尔出现的连接超时或断开往往比持续性故障更令人头疼——它们难以复现,日志信息稀少,传统监控可能捕捉不到。作者从实际运维痛点出发,分享了一个轻量级的检测脚本,用于主动探查这类隐蔽问题。 核心思路是通过定时发送探测请求(比如HTTP或TCP握手),并精细记录响应时间与失败状态。脚本不仅捕获明显的连接拒绝,还能识别超时、半开连接等边缘情况,并将结果持久化为时序日志。作者特别展示了如何利用简单的统计方法(如滑动窗口内的失败率阈值)来区分偶发抖动与系统性风险,避免误告警。 这个脚本的巧妙之处在于它平衡了检测灵敏度与资源开销。对于运维人员而言,它就像一个常驻的“前哨”,能帮助定位问题发生的大致时段与模式,为后续深入排查(如检查网络设备日志、调整负载均衡策略或分析服务端资源瓶颈)提供明确线索。工具虽小,却切中了复杂系统中一个普遍存在的运维盲区。
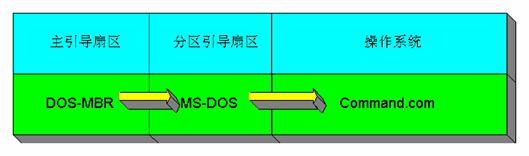
Linux操作系统的LILO详解
这篇讲的是Linux系统中一个经典启动加载器LILO的工作原理与配置方法。文章从最基本的安装方式入手,通过对比几种典型硬盘分区布局,清晰地揭示了LILO在不同场景下的运行逻辑。 作者详细对比了将LILO安装在Linux分区引导扇区与主引导扇区(MBR)的差异:前者需要手动切换活动分区,操作繁琐;后者则能完全接管启动流程,在开机时直接提供操作系统选择菜单,体验更优。此外,文中还提到了通过DOS下的LOADLIN工具启动Linux作为备选方案。 文章的核心亮点在于深入讲解了LILO如何向Linux内核传递启动参数。它不仅提供了一个交互式命令行界面让用户即时输入,还可以在配置文件`/etc/lilo.conf`中预先定义,例如设置单用户模式或配置网卡地址。通过一份结构化的配置文件范例,文章具体展示了如何管理多个启动选项、设置等待时间以及指定不同内核镜像。 整体而言,文章以实用的角度剖析了多重引导的配置思路,帮助读者理解如何根据自身需求选择和设置启动方案。
linux大磁盘分区工具parted
这篇讲的是在Linux下如何给超过2TB的大硬盘进行分区。 作者开篇点明了现实需求:如今大容量硬盘普及,但传统的MBR分区表存在2TB容量上限,导致很多传统工具无法处理。Linux自带的`parted`工具则是解决这个问题的好手。 文章重点对比了`parted`与另一个常用工具`fdisk`的核心差异。`parted`原生支持GPT分区表,能轻松管理大磁盘。更关键的是,它的操作是“实时”的,命令一旦执行就立即生效,而不像`fdisk`那样需要等到最后输入`w`才真正写入。这个区别至关重要,提醒管理员操作时必须格外谨慎。 为了帮助读者快速上手,文中还展示了`parted`工具的初始欢迎界面,给出了一个直观的起点。整体而言,文章从一个具体的技术痛点切入,清晰地介绍了解决工具及其关键注意事项。
将远程共享文件夹挂载到linux本地目录
客户要在不生成本地副本的情况下,将Windows虚拟机里10多T的扫描图片直接加载进数据库。这是一个典型的大数据量、高性能ETL场景,作者面对的核心矛盾是:物理主机无法直接挂载虚拟机磁盘,而传统的数据拷贝方式在数据量、时间成本和数据校验(MD5)上都不可接受。 文章首先探讨了在Windows虚拟机上安装Oracle客户端,使用SQL*Loader直接远程加载数据的方案。但由于安全策略限制(虚拟机无登录权限,数据目录仅开放读权限),该方案被否决。因此,作者转向了第二种思路:将Windows虚拟机上的扫描数据通过共享文件夹形式提供,然后将其挂载(mount)到Linux服务器的本地目录下。这样,从Linux应用的角度看,远程数据就像本地文件一样可以被直接访问和读取,为后续直接将数据流导入数据库(而非先落盘再导入)奠定了基础。文章给出了具体的实现验证开头,包括在Linux上创建测试表的SQL语句,预示着后续将进行实际的数据加载测试。
puppet vagrant 管理VirtualBox 虚拟机
这篇讲的是如何用Puppet和Vagrant这套组合拳来高效管理VirtualBox虚拟机。文章从运维团队面临的实际问题出发:手动创建和配置开发、测试环境费时费力,且难以保证一致性。作者提出的解决方案核心在于分工协作——Vagrant负责定义和快速创建VirtualBox虚拟机实例,解决环境“从无到有”的问题;而Puppet则专注于在虚拟机内部进行自动化的软件安装、配置和状态管理,解决“从有到优”和环境一致性的问题。 文章详细阐述了二者如何协同工作:通过Vagrantfile定义虚拟机基础配置,再编写Puppet manifest来描述期望的系统状态,最终一条命令就能交付一个完全符合要求的、可重复使用的标准化环境。这对于需要快速搭建复杂多机测试环境,或者希望在团队中统一开发环境配置的场景,提供了非常清晰和实用的落地路径。最终效果是显著减少了环境配置的重复劳动和人为错误,让基础设施即代码的理念得以在本地虚拟化环境中实践。
软件开发中的火车模型发布模式
作者翻开《启示录:打造用户喜爱的产品》时,对书中提及的“火车模型发布模式”产生了疑问。他发现,尽管这个模式被许多成熟互联网公司广泛采用,但网络上的相关介绍却寥寥无几,不少内容还因翻译差异而显得晦涩难懂。 为了解清楚,作者深入查找资料,最终找到了一个来自Firefox开发团队的经典案例。他通过这个具体的实践,将抽象的火车模型形象化地呈现出来:整个项目像一趟火车,按照固定的“时刻表”(如每六周)发布新版本;各个功能特性则像乘客,在固定的发车时间点,能赶上车的就上线,赶不上的就只能等下一班。 文章正是从这个常见却容易被含糊带过的概念入手,借Firefox团队的经验,把火车模型发布模式的核心——**规律性的发布节奏、可预测的产出以及团队协作的刚性框架**——讲透了。这对于理解许多互联网产品背后的迭代逻辑很有帮助。
使用Apache 和Passenger来运行puppetmaster
这篇讲的是如何用Apache和Passenger来部署Puppet Master,以解决其默认运行方式存在的性能和管理问题。文章指出,Puppet Master默认使用WEBrick服务器运行,虽然能工作,但在实际生产环境中,面对大量节点并发请求时,性能和稳定性会成为瓶颈。 作者给出的方案是,将Puppet Master部署在Apache Web服务器下,并通过Phusion Passenger模块来管理应用进程。这种架构将Apache作为前端,负责处理连接、SSL终端和静态文件,而Passenger则负责高效地管理Puppet Master的Ruby应用进程,实现了进程的预加载、动态伸缩和崩溃自动重启。 文章详细说明了配置步骤和关键参数,比如Passenger的并发进程数设置、Apache的虚拟主机配置,以及如何处理Puppet证书相关的SSL配置。采用这种方案后,Puppet Master的并发处理能力得到显著提升,服务更加稳定,同时也让日志管理和运维监控变得更加便捷。这为需要大规模部署Puppet的团队提供了一套成熟可靠的生产级部署方案。
Erlang虚拟机基础设施dtrace探测点介绍和使用
这篇讲的是 Erlang 虚拟机(R15B01 版本)中新增的 dtrace 探测点支持。文章从生产环境运维的角度切入,指出在复杂分布式系统中定位性能瓶颈的传统手段往往不够用。作者详细解读了这次更新带来的关键能力:通过在虚拟机底层基础设施(如调度器、内存管理、垃圾回收)埋入 dtrace 探测点,开发者和运维人员现在能够像使用系统级的“探照灯”一样,实时、低开销地观察 Erlang VM 的内部运行状态。 文章进一步探讨了这些探测点的具体应用场景,例如如何追踪特定调度器的上下文切换、监控消息传递的延迟,或是分析垃圾回收事件对系统吞吐量的影响。核心亮点在于,这些能力直接内建于 BEAM 虚拟机,无需修改应用代码即可在已部署的生产系统中动态启用,极大地降低了性能诊断的门槛。对于需要保障高可用 Erlang 服务稳定性的团队来说,这提供了一套深入内核的实用工具箱。
puppetca 高可用性以及负载均衡配置
这篇讲的是如何解决Puppet环境中CA(证书颁发机构)服务器单点故障的问题,并为大规模节点部署提供负载均衡方案。 在典型的Puppet架构中,所有节点在首次运行时都会向唯一的CA服务器发起证书请求。如果这台服务器宕机,新加入的节点将无法获取证书,整个配置管理流程就会中断。文章正是针对这一背景,详细介绍了构建高可用Puppet CA服务的具体步骤。作者不仅涵盖了如何设置主备CA服务器以实现故障自动切换,还探讨了如何配置负载均衡器来分发来自Agent节点的证书签名请求,从而提升系统的整体处理能力和可靠性。 文中对关键配置环节进行了拆解,例如证书的同步机制、负载均衡策略的选择以及在实际环境中需要特别注意的依赖项和潜在冲突。最终呈现的是一套经过验证的、可直接参考的实践方案,旨在帮助运维人员构建一个更加健壮和易于扩展的Puppet管理基础设施。
那些年,我们一起合作时头痛的事
这篇讲的是技术团队在跨部门合作中那些让人头疼的共同记忆。作者从多个真实项目经验出发,复盘了那些因沟通不畅、流程不顺而导致的线上事故或效率黑洞。比如,需求文档像“传声筒”一样走样,联调环境总在关键时刻崩掉,或者因为版本管理混乱,一个简单的合并就能引发雪崩。 文章没有停留在抱怨层面,而是深入剖析了问题背后的根因——往往是协作机制与信任基础的双重缺失。它指出了许多团队的共性误区:只关注技术实现,却忽略了协作流程的设计;或者只追求快速上线,而牺牲了必要的文档和沟通成本。文中的案例细节扎实,比如对某个典型“甩锅”场景的还原,读来让人会心一笑又深有共鸣。 它最终给出的启发很实在:建立清晰的接口人机制、坚持“文档先行”的文化、以及在压力下保持透明的沟通习惯。这些看似朴素的建议,恰恰是解开许多合作“死结”的关键。如果你也曾为跨团队协作感到疲惫,这篇复盘或许能提供一些破局的思路。
top监控命令在FreeBSD上的使用
这篇讲的是如何在FreeBSD系统上高效使用`top`这个实时进程监控工具。它不只是列出CPU占用高的进程,更详细拆解了FreeBSD版本特有的选项和输出含义,帮助系统管理员深入理解系统状态。 文章核心剖析了`top`运行时屏幕显示的三个关键部分。首先是系统概览,解释了“load averages”(负载平均值)和各状态进程数的意义,指出当单个CPU的运行任务数大于5时可能预示性能问题。其次是内存信息,细致区分了Active(活动页)、Wired(已写入页)、Cache(缓存)等状态的含义,以及交换区的使用情况,让读者能准确判断内存压力来源。最后是进程列表,逐一解读了PRI(优先级)、NICE(nice值)、SIZE与RES(内存占用)、以及%WCPU/%CPU(CPU利用率)等每一列数据的具体所指。 此外,文章还介绍了交互模式下可用的控制命令,如按`o`排序、按`k`终止进程等,以及如何通过`-S`、`-b`、`-I`等选项定制监控输出,例如显示系统进程或隐藏空闲进程。掌握这些细节,能让你在FreeBSD上用好`top`,进行快速的性能分析与问题定位。